Related Research Articles
Computational linguistics is an interdisciplinary field concerned with the computational modelling of natural language, as well as the study of appropriate computational approaches to linguistic questions. In general, computational linguistics draws upon linguistics, computer science, artificial intelligence, mathematics, logic, philosophy, cognitive science, cognitive psychology, psycholinguistics, anthropology and neuroscience, among others.

Machine translation is use of computational techniques to translate text or speech from one language to another, including the contextual, idiomatic and pragmatic nuances of both languages.

In the industrial design field of human–computer interaction, a user interface (UI) is the space where interactions between humans and machines occur. The goal of this interaction is to allow effective operation and control of the machine from the human end, while the machine simultaneously feeds back information that aids the operators' decision-making process. Examples of this broad concept of user interfaces include the interactive aspects of computer operating systems, hand tools, heavy machinery operator controls and process controls. The design considerations applicable when creating user interfaces are related to, or involve such disciplines as, ergonomics and psychology.
Word-sense disambiguation (WSD) is the process of identifying which sense of a word is meant in a sentence or other segment of context. In human language processing and cognition, it is usually subconscious/automatic, but can often come to conscious attention when ambiguity impairs clarity of communication, given the pervasive polysemy in natural language. In computational linguistics, it is an open problem that affects other computer-related writing, such as discourse, improving relevance of search engines, anaphora resolution, coherence, and inference.
Question answering (QA) is a computer science discipline within the fields of information retrieval and natural language processing (NLP) that is concerned with building systems that automatically answer questions that are posed by humans in a natural language.
Computer-aided translation (CAT), also referred to as computer-assisted translation or computer-aided human translation (CAHT), is the use of software, also known as a translator, to assist a human translator in the translation process. The translation is created by a human, and certain aspects of the process are facilitated by software; this is in contrast with machine translation (MT), in which the translation is created by a computer, optionally with some human intervention.
Human-centered computing (HCC) studies the design, development, and deployment of mixed-initiative human-computer systems. It is emerged from the convergence of multiple disciplines that are concerned both with understanding human beings and with the design of computational artifacts. Human-centered computing is closely related to human-computer interaction and information science. Human-centered computing is usually concerned with systems and practices of technology use while human-computer interaction is more focused on ergonomics and the usability of computing artifacts and information science is focused on practices surrounding the collection, manipulation, and use of information.
Multimodal interaction provides the user with multiple modes of interacting with a system. A multimodal interface provides several distinct tools for input and output of data.
ALPAC was a committee of seven scientists led by John R. Pierce, established in 1964 by the United States government in order to evaluate the progress in computational linguistics in general and machine translation in particular. Its report, issued in 1966, gained notoriety for being very skeptical of research done in machine translation so far, and emphasizing the need for basic research in computational linguistics; this eventually caused the U.S. government to reduce its funding of the topic dramatically. This marked the beginning of the first AI winter.
Martin Kay was a computer scientist, known especially for his work in computational linguistics.
Computational humor is a branch of computational linguistics and artificial intelligence which uses computers in humor research. It is a relatively new area, with the first dedicated conference organized in 1996.

Visual analytics is an outgrowth of the fields of information visualization and scientific visualization that focuses on analytical reasoning facilitated by interactive visual interfaces.

Human–computer interaction (HCI) is research in the design and the use of computer technology, which focuses on the interfaces between people (users) and computers. HCI researchers observe the ways humans interact with computers and design technologies that allow humans to interact with computers in novel ways. A device that allows interaction between human being and a computer is known as a "Human-computer Interface (HCI)".
Caitra is a translation Computer Assisted Tool, or CAT, developed by the University of Edinburgh. Provided from an online platform, Caitra is based on AJAX Web.2 technologies and the Moses decoder. The web page of the tool is implemented with Ruby on Rails, an open source web framework, and C++.
In natural language processing, textual entailment (TE), also known as natural language inference (NLI), is a directional relation between text fragments. The relation holds whenever the truth of one text fragment follows from another text.
The following outline is provided as an overview of and topical guide to natural-language processing:
LEPOR is an automatic language independent machine translation evaluation metric with tunable parameters and reinforced factors.
MateCat is a web-based computer-assisted translation (CAT) tool, released as open-source software under the Lesser General Public License (LGPL).
Neural machine translation (NMT) is an approach to machine translation that uses an artificial neural network to predict the likelihood of a sequence of words, typically modeling entire sentences in a single integrated model.
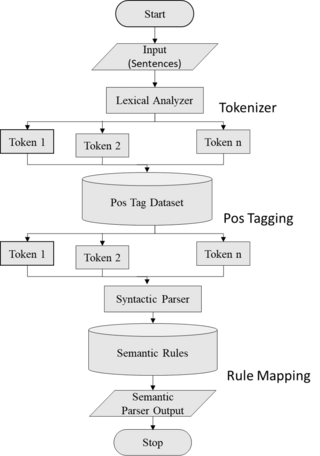
Semantic parsing is the task of converting a natural language utterance to a logical form: a machine-understandable representation of its meaning. Semantic parsing can thus be understood as extracting the precise meaning of an utterance. Applications of semantic parsing include machine translation, question answering, ontology induction, automated reasoning, and code generation. The phrase was first used in the 1970s by Yorick Wilks as the basis for machine translation programs working with only semantic representations. Semantic parsing is one of the important tasks in computational linguistics and natural language processing.
References
- 1 2 Casacuberta, Francisco; Civera, Jorge; Cubel, Elsa; Lagarda, Antonio L.; Lapalme, Guy; Macklovitch, Elliott; Vidal, Enrique (2009). "Human interaction for high quality machine translation" (PDF). Communications of the ACM. 52 (10): 135–138. doi:10.1145/1562764.1562798. Archived from the original (PDF) on 2011-07-06.
- ↑ Herbig, Nico; Pal, Santanu; van Genabith, Josef; Krüger, Antonio (2019). "Integrating Artificial and Human Intelligence for Efficient Translation". arXiv: 1903.02978 [cs.HC].
- 1 2 3 Barrachina, Sergio; Bender, Oliver; Casacuberta, Francisco; Civera, Jorge; Cubel, Elsa; Khadivi, Shahram; Lagarda, Antonio L.; Ney, Hermann; Tomás, Jesús; Vidal, Enrique (2009). "Statistical approaches to computer-assisted translation" (PDF). Computational Linguistics. 25 (1): 3–28. doi: 10.1162/coli.2008.07-055-r2-06-29 .
- ↑ Foster, George; Isabelle, Pierre; Plamondon, Pierre (1997). "Target-text mediated interactive machine translation". Machine Translation. 12 (1): 175–194. doi:10.1023/a:1007999327580.
- ↑ Alabau, Vicent; Buck, Christian; Carl, Michael; Casacuberta, Francisco; Garcia-Martinez, Mercedes; Germann, Ulrich; Gonzalez-Rubio, Jesus; Hill, Robin; Koehn, Philipp; Leiva, Luis; Mesa-Lao, Barto; Ortiz, Daniel; Saint-Amand, Herve; Sanchis, German; Tsoukala, Chara (April 2014). "CASMACAT: A Computer-assisted Translation Workbench" (PDF). Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics. Los Angeles, California: Association for Computational Linguistics. pp. 25–28.
- ↑ Ortiz-Martinez, Daniel; Garcia-Varea, Ismael; Casacuberta, Francisco (June 2010). "Online Learning for Interactive Statistical Machine Translation" (PDF). Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the ACL. Association for Computational Linguistics. pp. 546–554.
- ↑ Martinez-Gomez, Pascual; Sanchis-Trilles, German; Casacuberta, Francisco (September 2012). "Online adaptation strategies for statistical machine translation in post-editing scenarios". Pattern Recognition. 45 (9). Elsevier: 3193–3203. doi:10.1016/j.patcog.2012.01.011. hdl: 10251/37324 .
- ↑ Koehn, Philipp (June 2010). "Enabling Monolingual Translators: Post-Editing vs. Options" (PDF). Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics (HLT/NAACL). Los Angeles, California: Association for Computational Linguistics. pp. 537–545.
- ↑ Juan Antonio, Pérez-Ortiz; Torregrosa, Daniel; Forcada, Mikel (2014). "Black-box integration of heterogeneous bilingual resources into an interactive translation system". Proceedings of the EACL 2014 Workshop on Humans and Computer-assisted Translation. Los Angeles, California: Association for Computational Linguistics. pp. 57–65.
- ↑ Sanchis-Trilles, Germán; Ortiz-Martínez, Daniel; Civera, Jorge; Casacuberta, Francisco; Vidal, Enrique; Hoang, Hieu (October 2008). "Improving Interactive Machine Translation via Mouse Actions" (PDF). Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing (EMNLP). Honolulu, Hawaii: Association for Computational Linguistics. pp. 485–494.
- ↑ González-Rubio, Jesús; Ortiz-Martínez, Daniel; Casacuberta, Francisco (July 2010). "Balancing User Effort and Translation Error in Interactive Machine Translation via Confidence Measures" (PDF). Proceedings of the ACL 2010 Conference Short Papers (ACL). Uppsala, Sweden: Association for Computational Linguistics. pp. 173–177.
- ↑ Underwood, Nancy; Mesa-Lao, Bartolomé; García-Martínez, Mercedes; Carl, Michael; Alabau, Vicent; González-Rubio, Jesús; Leiva, Luis; Sanchis-Trilles, Germán; Ortiz-Martínez, Daniel; Casacuberta, Francisco (May 2014). "Evaluating the Effects of Interactivity in a Post-Editing Workbench" (PDF). Proceedings of the 29th edition of the Language Resources and Evaluation Conference (LREC). Reykjavik, Iceland. pp. 553–559.
- ↑ Ortiz-Martínez, Daniel; González-Rubio, Jesús; Alabau, Vicent; Sanchis-Trilles, Germán; Casacuberta, Francisco (August 2015). "Integrating Online and Active Learning in a Computer-Assisted Translation Workbench". New Directions in Empirical Translation Process Research: Exploring the CRITT TPR-DB. Springer. pp. 54–73.
- ↑ Alabau, Vicent; Carl, Michael; Casacuberta, Francisco; García-Martínez, Mercedes; Mesa-Lao, Bartolomé; Ortiz-Martínez, Daniel; González-Rubio, Jesús; Sanchis-Trilles, Germán; Schaeffer, Moritz (August 2015). "Learning Advanced Post-editing". New Directions in Empirical Translation Process Research: Exploring the CRITT TPR-DB. Springer. pp. 95–111.