In linear algebra, the determinant is a scalar value that can be computed from the elements of a square matrix and encodes certain properties of the linear transformation described by the matrix. The determinant of a matrix A is denoted det(A), det A, or |A|. Geometrically, it can be viewed as the volume scaling factor of the linear transformation described by the matrix. This is also the signed volume of the n-dimensional parallelepiped spanned by the column or row vectors of the matrix. The determinant is positive or negative according to whether the linear mapping preserves or reverses the orientation of n-space.
In linear algebra, a symmetric real matrix is said to be positive definite if the scalar is strictly positive for every non-zero column vector of real numbers. Here denotes the transpose of .. When interpreting as the output of an operator, , that is acting on an input, , the property of positive definiteness implies that the output always has a positive inner product with the input, as often observed in physical processes.

In linear algebra, the column space of a matrix A is the span of its column vectors. The column space of a matrix is the image or range of the corresponding matrix transformation.
An orthogonal matrix is a square matrix whose columns and rows are orthogonal unit vectors, i.e.
In mathematics, matrix multiplication or matrix product is a binary operation that produces a matrix from two matrices with entries in a field, or, more generally, in a ring or even a semiring. The matrix product is designed for representing the composition of linear maps that are represented by matrices. Matrix multiplication is thus a basic tool of linear algebra, and as such has numerous applications in many areas of mathematics, as well as in applied mathematics, statistics, physics, economics, and engineering. In more detail, if A is an n × m matrix and B is an m × p matrix, their matrix product AB is an n × p matrix, in which the m entries across a row of A are multiplied with the m entries down a column of B and summed to produce an entry of AB. When two linear maps are represented by matrices, then the matrix product represents the composition of the two maps.

In mathematics, a square matrix is a matrix with the same number of rows and columns. An n-by-n matrix is known as a square matrix of order n. Any two square matrices of the same order can be added and multiplied.
In linear algebra, a diagonal matrix is a matrix in which the entries outside the main diagonal are all zero. The term usually refers to square matrices. An example of a 2-by-2 diagonal matrix is ; the following matrix is a 3-by-3 diagonal matrix: . An identity matrix of any size, or any multiple of it, will be a diagonal matrix.
In linear algebra, an n-by-n square matrix A is called invertible if there exists an n-by-n square matrix B such that
In mathematics applied to computer science, Monge arrays, or Monge matrices, are mathematical objects named for their discoverer, the French mathematician Gaspard Monge.
In mathematics, particularly in matrix theory, a permutation matrix is a square binary matrix that has exactly one entry of 1 in each row and each column and 0s elsewhere. Each such matrix, say P, represents a permutation of m elements and, when used to multiply another matrix, say A, results in permuting the rows or columns of the matrix A.
In linear algebra, a QR decomposition of a matrix is a decomposition of a matrix A into a product A = QR of an orthogonal matrix Q and an upper triangular matrix R. QR decomposition is often used to solve the linear least squares problem and is the basis for a particular eigenvalue algorithm, the QR algorithm.
In abstract algebra, a matrix ring is any collection of matrices over some ring R that form a ring under matrix addition and matrix multiplication. The set of n × n matrices with entries from R is a matrix ring denoted Mn(R), as well as some subsets of infinite matrices which form infinite matrix rings. Any subring of a matrix ring is a matrix ring.
In linear algebra, linear transformations can be represented by matrices. If is a linear transformation mapping to and is a column vector with entries, then
In mathematics, the Smith normal form is a normal form that can be defined for any matrix with entries in a principal ideal domain (PID). The Smith normal form of a matrix is diagonal, and can be obtained from the original matrix by multiplying on the left and right by invertible square matrices. In particular, the integers are a PID, so one can always calculate the Smith normal form of an integer matrix. The Smith normal form is very useful for working with finitely generated modules over a PID, and in particular for deducing the structure of a quotient of a free module. It is named for the British mathematician Henry John Stephen Smith.
In mathematics, and in particular, algebra, a generalized inverse of an element x is an element y that has some properties of an inverse element but not necessarily all of them. Generalized inverses can be defined in any mathematical structure that involves associative multiplication, that is, in a semigroup. This article describes generalized inverses of a matrix .
In mathematics, especially in linear algebra and matrix theory, the vectorization of a matrix is a linear transformation which converts the matrix into a column vector. Specifically, the vectorization of an m × n matrix A, denoted vec(A), is the mn × 1 column vector obtained by stacking the columns of the matrix A on top of one another:
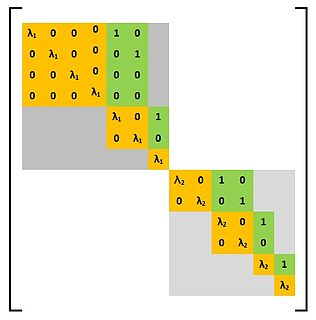
In mathematics, in linear algebra, a Weyr canonical form is a square matrix satisfying certain conditions. A square matrix is said to be in the Weyr canonical form if the matrix satisfies the conditions defining the Weyr canonical form. The Weyr form was discovered by the Czech mathematician Eduard Weyr in 1885. The Weyr form did not become popular among mathematicians and it was overshadowed by the closely related, but distinct, canonical form known by the name Jordan canonical form. The Weyr form has been rediscovered several times since Weyr’s original discovery in 1885. This form has been variously called as modified Jordan form,reordered Jordan form,second Jordan form, and H-form. The current terminology is credited to Shapiro who introduced it in a paper published in the American Mathematical Monthly in 1999.
















