Related Research Articles
Speech recognition is an interdisciplinary subfield of computer science and computational linguistics that develops methodologies and technologies that enable the recognition and translation of spoken language into text by computers. It is also known as automatic speech recognition (ASR), computer speech recognition or speech-to-text (STT). It incorporates knowledge and research in the computer science, linguistics and computer engineering fields. The reverse process is speech synthesis.
A hidden Markov model (HMM) is a Markov model in which the observations are dependent on a latent Markov process. An HMM requires that there be an observable process whose outcomes depend on the outcomes of in a known way. Since cannot be observed directly, the goal is to learn about state of by observing . By definition of being a Markov model, an HMM has an additional requirement that the outcome of at time must be "influenced" exclusively by the outcome of at and that the outcomes of and at must be conditionally independent of at given at time . Estimation of the parameters in an HMM can be performed using maximum likelihood estimation. For linear chain HMMs, the Baum–Welch algorithm can be used to estimate parameters.
The Viterbi algorithm is a dynamic programming algorithm for obtaining the maximum a posteriori probability estimate of the most likely sequence of hidden states—called the Viterbi path—that results in a sequence of observed events. This is done especially in the context of Markov information sources and hidden Markov models (HMM).
In electrical engineering, statistical computing and bioinformatics, the Baum–Welch algorithm is a special case of the expectation–maximization algorithm used to find the unknown parameters of a hidden Markov model (HMM). It makes use of the forward-backward algorithm to compute the statistics for the expectation step.
The Framework Programmes for Research and Technological Development, also called Framework Programmes or abbreviated FP1 to FP9, are funding programmes created by the European Union/European Commission to support and foster research in the European Research Area (ERA). Starting in 2014, the funding programmes were named Horizon.
CMU Sphinx, also called Sphinx for short, is the general term to describe a group of speech recognition systems developed at Carnegie Mellon University. These include a series of speech recognizers and an acoustic model trainer (SphinxTrain).
Julius is a speech recognition engine, specifically a high-performance, two-pass large vocabulary continuous speech recognition (LVCSR) decoder software for speech-related researchers and developers. It can perform almost real-time computing (RTC) decoding on most current personal computers (PCs) in 60k word dictation task using word trigram (3-gram) and context-dependent Hidden Markov model (HMM). Major search methods are fully incorporated.
As of the early 2000s, several speech recognition (SR) software packages exist for Linux. Some of them are free and open-source software and others are proprietary software. Speech recognition usually refers to software that attempts to distinguish thousands of words in a human language. Voice control may refer to software used for communicating operational commands to a computer.
The Intelligence Advanced Research Projects Activity (IARPA) is an organization within the Office of the Director of National Intelligence responsible for leading research to overcome difficult challenges relevant to the United States Intelligence Community. IARPA characterizes its mission as follows: "To envision and lead high-risk, high-payoff research that delivers innovative technology for future overwhelming intelligence advantage."
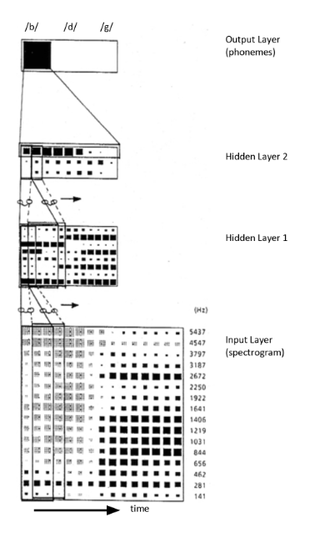
Time delay neural network (TDNN) is a multilayer artificial neural network architecture whose purpose is to 1) classify patterns with shift-invariance, and 2) model context at each layer of the network.
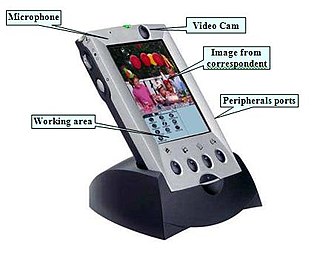
The first integration between mobile phone and Palm (PDA Personal Device Assistant) occurred in 1999, as a result of an Italian–lead project submitted to the action line V1.1 CPA1 "Integrated application platforms and services" 5th Framework Program of the European Community (project number IST1999-11100). The project, called MTM (Multimedia Terminal Mobile), was a multimedia platform, including both phone and PDA features; it also integrated the first miniature camera and a unidirectional microphone for video conferencing and commands interpretation through voice recognition. The creator and coordinator of the project, Alessandro Pappa, worked in a team with other European partners:
The HPC-Europa programmes are European Union (EU) funded research initiatives in the field of high-performance computing (HPC). The programmes concentrate on the development of a European Research Area, and in particular, improving the ability of European researchers to access the European supercomputing infrastructure provided by the programmes' partners. The programme is currently in its third iteration, known as "HPC-Europa3" or "HPCE3", and fully titled the "Transnational Access Programme for a Pan-European Network of HPC Research Infrastructures and Laboratories for scientific computing".
Nelson Harold Morgan is an American computer scientist and professor in residence (emeritus) of electrical engineering and computer science at the University of California, Berkeley. Morgan is the co-inventor of the Relative Spectral (RASTA) approach to speech signal processing, first described in a technical report published in 1991.
Kaldi is an open-source speech recognition toolkit written in C++ for speech recognition and signal processing, freely available under the Apache License v2.0.
In signal processing, Feature space Maximum Likelihood Linear Regression (fMLLR) is a global feature transform that are typically applied in a speaker adaptive way, where fMLLR transforms acoustic features to speaker adapted features by a multiplication operation with a transformation matrix. In some literature, fMLLR is also known as the Constrained Maximum Likelihood Linear Regression (cMLLR).

C3D Toolkit is a proprietary cross-platform geometric modeling kit software developed by Russian C3D Labs. It's written in C++. It can be licensed by other companies for use in their 3D computer graphics software products. The most widely known software in which C3D Toolkit is typically used are computer aided design (CAD), computer-aided manufacturing (CAM), and computer-aided engineering (CAE) systems.
The EuroMatrixPlus is a project that ran from March 2009 to February 2012. EuroMatrixPlus succeeded a project called EuroMatrix and continued in further development and improvement of machine translation (MT) systems for languages of the European Union (EU).
SwellRT was a free and open-source backend-as-a-service and API focused to ease development of apps featuring real-time collaboration. It supported the building of mobile and web apps, and aims to facilitate interoperability and federation.
The IARPA Babel program developed speech recognition technology for noisy telephone conversations. The main goal of the program was to improve the performance of keyword search on languages with very little transcribed data, i.e. low-resource languages. Data from 26 languages was collected with certain languages being held-out as "surprise" languages to test the ability of the teams to rapidly build a system for a new language.
References
- ↑ Sebastian Stüker. "KIT - Janus Recognition Toolkit". Isl.ira.uka.de. Retrieved 2012-04-23.[ permanent dead link ]
- ↑ Patricia Lichtblau (2012-02-01). "EU-Bridge - Homepage". Eu-bridge.eu. Retrieved 2012-04-23.
- ↑ Esben Eidevik (2012-04-15). "EVEIL-3D-Startseite". Eveil-3d.eu. Retrieved 2012-04-23.
- ↑ "IARPA - Solicitations - Office of Incisive Analysis, Babel Program". Iarpa.gov. Archived from the original on 2012-04-22. Retrieved 2012-04-23.
- ↑ "Bienvenue sur le site de Quaero". Quaero.org. Retrieved 2012-04-23.
- ↑ "SFB 588 - Humanoid Robots". Sfb588.uni-karlsruhe.de. Retrieved 2012-04-23.
- ↑ "European Commission : CORDIS : Projects & Results Service : Technology and corpora for speech to speech translation". Cordis.europa.eu. Retrieved 2016-07-16.
- ↑ "European Commission : CORDIS : Projects & Results Service : Facilitating Agent in Multicultural Exchange". Cordis.europa.eu. Retrieved 2016-07-16.
- ↑ "European Commission : CORDIS : Projects & Results Service : NEgotiating through SPOken Language in E-commerce". Cordis.europa.eu. Retrieved 2016-07-16.