
In computer science, binary search, also known as half-interval search, logarithmic search, or binary chop, is a search algorithm that finds the position of a target value within a sorted array. Binary search compares the target value to the middle element of the array. If they are not equal, the half in which the target cannot lie is eliminated and the search continues on the remaining half, again taking the middle element to compare to the target value, and repeating this until the target value is found. If the search ends with the remaining half being empty, the target is not in the array.

In computer science, a binary search tree (BST), also called an ordered or sorted binary tree, is a rooted binary tree data structure with the key of each internal node being greater than all the keys in the respective node's left subtree and less than the ones in its right subtree. The time complexity of operations on the binary search tree is directly proportional to the height of the tree.

In computer science and information theory, a Huffman code is a particular type of optimal prefix code that is commonly used for lossless data compression. The process of finding or using such a code proceeds by means of Huffman coding, an algorithm developed by David A. Huffman while he was a Sc.D. student at MIT, and published in the 1952 paper "A Method for the Construction of Minimum-Redundancy Codes".

In computer science, a heap is a specialized tree-based data structure which is essentially an almost complete tree that satisfies the heap property: in a max heap, for any given node C, if P is a parent node of C, then the key of P is greater than or equal to the key of C. In a min heap, the key of P is less than or equal to the key of C. The node at the "top" of the heap is called the root node.
In computer science, a linear search or sequential search is a method for finding an element within a list. It sequentially checks each element of the list until a match is found or the whole list has been searched.

In computer science, merge sort is an efficient, general-purpose, and comparison-based sorting algorithm. Most implementations produce a stable sort, which means that the order of equal elements is the same in the input and output. Merge sort is a divide-and-conquer algorithm that was invented by John von Neumann in 1945. A detailed description and analysis of bottom-up merge sort appeared in a report by Goldstine and von Neumann as early as 1948.
Merge algorithms are a family of algorithms that take multiple sorted lists as input and produce a single list as output, containing all the elements of the inputs lists in sorted order. These algorithms are used as subroutines in various sorting algorithms, most famously merge sort.

In computer science, a search algorithm is an algorithm designed to solve a search problem. Search algorithms work to retrieve information stored within particular data structure, or calculated in the search space of a problem domain, with either discrete or continuous values.
A splay tree is a binary search tree with the additional property that recently accessed elements are quick to access again. Like self-balancing binary search trees, a splay tree performs basic operations such as insertion, look-up and removal in O(log n) amortized time. For random access patterns drawn from a non-uniform random distribution, their amortized time can be faster than logarithmic, proportional to the entropy of the access pattern. For many patterns of non-random operations, also, splay trees can take better than logarithmic time, without requiring advance knowledge of the pattern. According to the unproven dynamic optimality conjecture, their performance on all access patterns is within a constant factor of the best possible performance that could be achieved by any other self-adjusting binary search tree, even one selected to fit that pattern. The splay tree was invented by Daniel Sleator and Robert Tarjan in 1985.

In computer science, a sorting algorithm is an algorithm that puts elements of a list into an order. The most frequently used orders are numerical order and lexicographical order, and either ascending or descending. Efficient sorting is important for optimizing the efficiency of other algorithms that require input data to be in sorted lists. Sorting is also often useful for canonicalizing data and for producing human-readable output.

A binary heap is a heap data structure that takes the form of a binary tree. Binary heaps are a common way of implementing priority queues. The binary heap was introduced by J. W. J. Williams in 1964, as a data structure for heapsort.
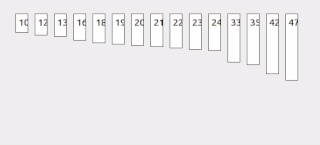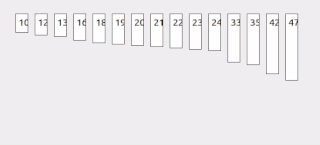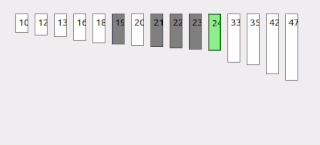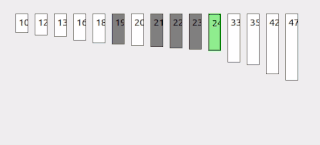
Interpolation search is an algorithm for searching for a key in an array that has been ordered by numerical values assigned to the keys. It was first described by W. W. Peterson in 1957. Interpolation search resembles the method by which people search a telephone directory for a name : in each step the algorithm calculates where in the remaining search space the sought item might be, based on the key values at the bounds of the search space and the value of the sought key, usually via a linear interpolation. The key value actually found at this estimated position is then compared to the key value being sought. If it is not equal, then depending on the comparison, the remaining search space is reduced to the part before or after the estimated position. This method will only work if calculations on the size of differences between key values are sensible.

In computer science, a self-balancing binary search tree (BST) is any node-based binary search tree that automatically keeps its height small in the face of arbitrary item insertions and deletions. These operations when designed for a self-balancing binary search tree, contain precautionary measures against boundlessly increasing tree height, so that these abstract data structures receive the attribute "self-balancing".

In computer science, the time complexity is the computational complexity that describes the amount of computer time it takes to run an algorithm. Time complexity is commonly estimated by counting the number of elementary operations performed by the algorithm, supposing that each elementary operation takes a fixed amount of time to perform. Thus, the amount of time taken and the number of elementary operations performed by the algorithm are taken to be related by a constant factor.

A comparison sort is a type of sorting algorithm that only reads the list elements through a single abstract comparison operation that determines which of two elements should occur first in the final sorted list. The only requirement is that the operator forms a total preorder over the data, with:
- if a ≤ b and b ≤ c then a ≤ c (transitivity)
- for all a and b, a ≤ b or b ≤ a (connexity).

Quicksort is an efficient, general-purpose sorting algorithm. Quicksort was developed by British computer scientist Tony Hoare in 1959 and published in 1961. It is still a commonly used algorithm for sorting. Overall, it is slightly faster than merge sort and heapsort for randomized data, particularly on larger distributions.
In computer science, Kosaraju-Sharir's algorithm is a linear time algorithm to find the strongly connected components of a directed graph. Aho, Hopcroft and Ullman credit it to S. Rao Kosaraju and Micha Sharir. Kosaraju suggested it in 1978 but did not publish it, while Sharir independently discovered it and published it in 1981. It makes use of the fact that the transpose graph has exactly the same strongly connected components as the original graph.
In computer science, integer sorting is the algorithmic problem of sorting a collection of data values by integer keys. Algorithms designed for integer sorting may also often be applied to sorting problems in which the keys are floating point numbers, rational numbers, or text strings. The ability to perform integer arithmetic on the keys allows integer sorting algorithms to be faster than comparison sorting algorithms in many cases, depending on the details of which operations are allowed in the model of computing and how large the integers to be sorted are.
In computer science, an exponential search is an algorithm, created by Jon Bentley and Andrew Chi-Chih Yao in 1976, for searching sorted, unbounded/infinite lists. There are numerous ways to implement this, with the most common being to determine a range that the search key resides in and performing a binary search within that range. This takes O(log i) where i is the position of the search key in the list, if the search key is in the list, or the position where the search key should be, if the search key is not in the list.
In computer science, an optimal binary search tree (Optimal BST), sometimes called a weight-balanced binary tree, is a binary search tree which provides the smallest possible search time (or expected search time) for a given sequence of accesses (or access probabilities). Optimal BSTs are generally divided into two types: static and dynamic.
