Related Research Articles
Distributed computing is a field of computer science that studies distributed systems, defined as computer systems whose inter-communicating components are located on different networked computers.

A supercomputer is a type of computer with a high level of performance as compared to a general-purpose computer. The performance of a supercomputer is commonly measured in floating-point operations per second (FLOPS) instead of million instructions per second (MIPS). Since 2022, supercomputers have existed which can perform over 1018 FLOPS, so called exascale supercomputers. For comparison, a desktop computer has performance in the range of hundreds of gigaFLOPS (1011) to tens of teraFLOPS (1013). Since November 2017, all of the world's fastest 500 supercomputers run on Linux-based operating systems. Additional research is being conducted in the United States, the European Union, Taiwan, Japan, and China to build faster, more powerful and technologically superior exascale supercomputers.
Grid computing is the use of widely distributed computer resources to reach a common goal. A computing grid can be thought of as a distributed system with non-interactive workloads that involve many files. Grid computing is distinguished from conventional high-performance computing systems such as cluster computing in that grid computers have each node set to perform a different task/application. Grid computers also tend to be more heterogeneous and geographically dispersed than cluster computers. Although a single grid can be dedicated to a particular application, commonly a grid is used for a variety of purposes. Grids are often constructed with general-purpose grid middleware software libraries. Grid sizes can be quite large.
Parallel computing is a type of computation in which many calculations or processes are carried out simultaneously. Large problems can often be divided into smaller ones, which can then be solved at the same time. There are several different forms of parallel computing: bit-level, instruction-level, data, and task parallelism. Parallelism has long been employed in high-performance computing, but has gained broader interest due to the physical constraints preventing frequency scaling. As power consumption by computers has become a concern in recent years, parallel computing has become the dominant paradigm in computer architecture, mainly in the form of multi-core processors.
AirawatPARAM is a series of Indian supercomputers designed and assembled by the Centre for Development of Advanced Computing (C-DAC) in Pune. PARAM means "supreme" in the Sanskrit language, whilst also creating an acronym for "PARAllel Machine". As of November 2022, the fastest machine in the series is the PARAM Airawat which ranks 63rd in world, with an Rpeak of 5.267 petaflops.

High-performance computing (HPC) is the use of supercomputers and computer clusters to solve advanced computation problems.
Utility computing, or computer utility, is a service provisioning model in which a service provider makes computing resources and infrastructure management available to the customer as needed, and charges them for specific usage rather than a flat rate. Like other types of on-demand computing, the utility model seeks to maximize the efficient use of resources and/or minimize associated costs. Utility is the packaging of system resources, such as computation, storage and services, as a metered service. This model has the advantage of a low or no initial cost to acquire computer resources; instead, resources are essentially rented.
TeraGrid was an e-Science grid computing infrastructure combining resources at eleven partner sites. The project started in 2001 and operated from 2004 through 2011.

A computer cluster is a set of computers that work together so that they can be viewed as a single system. Unlike grid computers, computer clusters have each node set to perform the same task, controlled and scheduled by software. The newest manifestation of cluster computing is cloud computing.
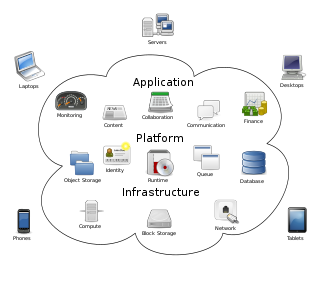
Cloud computing is "a paradigm for enabling network access to a scalable and elastic pool of shareable physical or virtual resources with self-service provisioning and administration on-demand," according to ISO.
Distributed European Infrastructure for Supercomputing Applications (DEISA) was a consortium of major national supercomputing centres in Europe. Initiated in 2002, it became a European Union funded supercomputer project. The consortium of eleven national supercomputing centres from seven European countries promoted pan-European research on European high-performance computing systems by creating a European collaborative environment in the area of supercomputing.
The Techila Distributed Computing Engine is a commercial grid computing software product. Techila Distributed Computing Engine is developed and licensed by Techila Technologies Ltd, a privately held company headquartered in Tampere, Finland. The product is also available as an on-demand solution in Google Cloud Launcher, the online marketplace created and operated by Google.
Data-intensive computing is a class of parallel computing applications which use a data parallel approach to process large volumes of data typically terabytes or petabytes in size and typically referred to as big data. Computing applications that devote most of their execution time to computational requirements are deemed compute-intensive, whereas applications are deemed data-intensive if they require large volumes of data and devote most of their processing time to input/output and manipulation of data.
HPCC, also known as DAS, is an open source, data-intensive computing system platform developed by LexisNexis Risk Solutions. The HPCC platform incorporates a software architecture implemented on commodity computing clusters to provide high-performance, data-parallel processing for applications utilizing big data. The HPCC platform includes system configurations to support both parallel batch data processing (Thor) and high-performance online query applications using indexed data files (Roxie). The HPCC platform also includes a data-centric declarative programming language for parallel data processing called ECL.

Quasi-opportunistic supercomputing is a computational paradigm for supercomputing on a large number of geographically disperse computers. Quasi-opportunistic supercomputing aims to provide a higher quality of service than opportunistic resource sharing.

Approaches to supercomputer architecture have taken dramatic turns since the earliest systems were introduced in the 1960s. Early supercomputer architectures pioneered by Seymour Cray relied on compact innovative designs and local parallelism to achieve superior computational peak performance. However, in time the demand for increased computational power ushered in the age of massively parallel systems.
Message passing is an inherent element of all computer clusters. All computer clusters, ranging from homemade Beowulfs to some of the fastest supercomputers in the world, rely on message passing to coordinate the activities of the many nodes they encompass. Message passing in computer clusters built with commodity servers and switches is used by virtually every internet service.
A distributed file system for cloud is a file system that allows many clients to have access to data and supports operations on that data. Each data file may be partitioned into several parts called chunks. Each chunk may be stored on different remote machines, facilitating the parallel execution of applications. Typically, data is stored in files in a hierarchical tree, where the nodes represent directories. There are several ways to share files in a distributed architecture: each solution must be suitable for a certain type of application, depending on how complex the application is. Meanwhile, the security of the system must be ensured. Confidentiality, availability and integrity are the main keys for a secure system.
Computation offloading is the transfer of resource intensive computational tasks to a separate processor, such as a hardware accelerator, or an external platform, such as a cluster, grid, or a cloud. Offloading to a coprocessor can be used to accelerate applications including: image rendering and mathematical calculations. Offloading computing to an external platform over a network can provide computing power and overcome hardware limitations of a device, such as limited computational power, storage, and energy.
In the high-performance computing environment, burst buffer is a fast intermediate storage layer positioned between the front-end computing processes and the back-end storage systems. It bridges the performance gap between the processing speed of the compute nodes and the Input/output (I/O) bandwidth of the storage systems. Burst buffers are often built from arrays of high-performance storage devices, such as NVRAM and SSD. It typically offers from one to two orders of magnitude higher I/O bandwidth than the back-end storage systems.
References
- 1 2 Jason Maassen, et al Towards jungle computing with Ibis/Constellation in Proceedings of the 2011 workshop on Dynamic distributed data-intensive applications, programming abstractions, and systems, ACM New York, ISBN 978-1-4503-0705-5 [ permanent dead link ]
- ↑ Jungle Computing: Distributed Supercomputing Beyond Clusters, Grids, and Clouds by Frank Seinstra et al in "Grids, Clouds and Virtualization, Computer Communications and Networks", ISBN 978-0-85729-048-9. Springer-Verlag London Limited, 2011, p. 167
| | This computing article is a stub. You can help Wikipedia by expanding it. |