In linguistics, creaky voice refers to a low, scratchy sound that occupies the vocal range below the common vocal register. It is a special kind of phonation in which the arytenoid cartilages in the larynx are drawn together; as a result, the vocal folds are compressed rather tightly, becoming relatively slack and compact. They normally vibrate irregularly at 20–50 pulses per second, about two octaves below the frequency of modal voicing, and the airflow through the glottis is very slow. Although creaky voice may occur with very low pitch, as at the end of a long intonation unit, it can also occur with a higher pitch. All contribute to make a speaker's voice sound creaky or raspy.
The term phonation has slightly different meanings depending on the subfield of phonetics. Among some phoneticians, phonation is the process by which the vocal folds produce certain sounds through quasi-periodic vibration. This is the definition used among those who study laryngeal anatomy and physiology and speech production in general. Phoneticians in other subfields, such as linguistic phonetics, call this process voicing, and use the term phonation to refer to any oscillatory state of any part of the larynx that modifies the airstream, of which voicing is just one example. Voiceless and supra-glottal phonations are included under this definition.

The human voice consists of sound made by a human being using the vocal tract, including talking, singing, laughing, crying, screaming, shouting, humming or yelling. The human voice frequency is specifically a part of human sound production in which the vocal folds are the primary sound source.
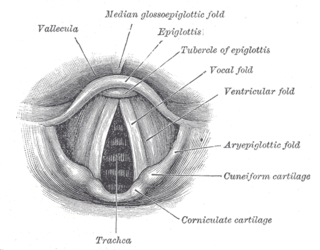
A vocal register is a range of tones in the human voice produced by a particular vibratory pattern of the vocal folds. These registers include modal voice, vocal fry, falsetto, and the whistle register. Registers originate in laryngeal function. They occur because the vocal folds are capable of producing several different vibratory patterns. Each of these vibratory patterns appears within a particular range of pitches and produces certain characteristic sounds.
In speech communication, intelligibility is a measure of how comprehensible speech is in given conditions. Intelligibility is affected by the level and quality of the speech signal, the type and level of background noise, reverberation, and, for speech over communication devices, the properties of the communication system. A common standard measurement for the quality of the intelligibility of speech is the Speech Transmission Index (STI). The concept of speech intelligibility is relevant to several fields, including phonetics, human factors, acoustical engineering, and audiometry.
Throat singing refers to several vocal practices found in different cultures worldwide. These vocal practices are generally associated with a certain type of guttural voice that contrasts with the most common types of voices employed in singing, which are usually represented by chest (modal) and head registers. Throat singing is often described as producing the sensation of more than one pitch at a time, meaning that the listener perceives two or more distinct musical notes while the singer is producing a single vocalization.
Speech perception is the process by which the sounds of language are heard, interpreted, and understood. The study of speech perception is closely linked to the fields of phonology and phonetics in linguistics and cognitive psychology and perception in psychology. Research in speech perception seeks to understand how human listeners recognize speech sounds and use this information to understand spoken language. Speech perception research has applications in building computer systems that can recognize speech, in improving speech recognition for hearing- and language-impaired listeners, and in foreign-language teaching.

Philip E. Rubin is an American cognitive scientist, technologist, and science administrator known for raising the visibility of behavioral and cognitive science, neuroscience, and ethical issues related to science, technology, and medicine, at a national level. His research career is noted for his theoretical contributions and pioneering technological developments, starting in the 1970s, related to speech synthesis and speech production, including articulatory synthesis and sinewave synthesis, and their use in studying complex temporal events, particularly understanding the biological bases of speech and language.
In phonetics and phonology, an alveolar stop is a type of consonantal sound, made with the tongue in contact with the alveolar ridge located just behind the teeth, held tightly enough to block the passage of air. The most common sounds are the stops and, as in English toe and doe, and the voiced nasal. The 2-D finite element mode of the front part of the midsagittal tongue can stimulate the air pressed release of an alveolar stop. Alveolar consonants in children's productions have generally been demonstrated to undergo smaller vowel-related coarticulatory effects than labial and velar consonants, thus yielding consonant-specific patterns similar to those observed in adults.
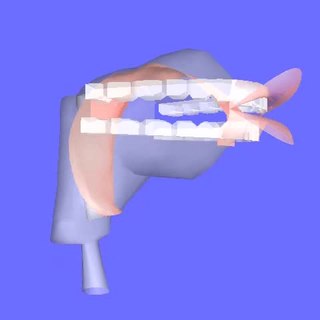
Articulatory synthesis refers to computational techniques for synthesizing speech based on models of the human vocal tract and the articulation processes occurring there. The shape of the vocal tract can be controlled in a number of ways which usually involves modifying the position of the speech articulators, such as the tongue, jaw, and lips. Speech is created by digitally simulating the flow of air through the representation of the vocal tract.
Articulatory phonology is a linguistic theory originally proposed in 1986 by Catherine Browman of Haskins Laboratories and Louis Goldstein of University of Southern California and Haskins. The theory identifies theoretical discrepancies between phonetics and phonology and aims to unify the two by treating them as low- and high-dimensional descriptions of a single system.
Katherine Safford Harris is a noted psychologist and speech scientist. She is Distinguished Professor Emerita in Speech and Hearing at the CUNY Graduate Center and a member of the Board of Directors Archived 2006-03-03 at the Wayback Machine of Haskins Laboratories. She is also the former President of the Acoustical Society of America and Vice President of Haskins Laboratories.
Duplex perception refers to the linguistic phenomenon whereby "part of the acoustic signal is used for both a speech and a nonspeech percept." A listener is presented with two simultaneous, dichotic stimuli. One ear receives an isolated third-formant transition that sounds like a nonspeech chirp. At the same time the other ear receives a base syllable. This base syllable consists of the first two formants, complete with formant transitions, and the third formant without a transition. Normally, there would be peripheral masking in such a binaural listening task but this does not occur. Instead, the listener's percept is duplex, that is, the completed syllable is perceived and the nonspeech chirp is heard at the same time. This is interpreted as being due to the existence of a special speech module.
Speech shadowing is a psycholinguistic experimental technique in which subjects repeat speech at a delay to the onset of hearing the phrase. The time between hearing the speech and responding, is how long the brain takes to process and produce speech. The task instructs participants to shadow speech, which generates intent to reproduce the phrase while motor regions in the brain unconsciously process the syntax and semantics of the words spoken. Words repeated during the shadowing task would also imitate the parlance of the shadowed speech.

The Lombard effect or Lombard reflex is the involuntary tendency of speakers to increase their vocal effort when speaking in loud noise to enhance the audibility of their voice. This change includes not only loudness but also other acoustic features such as pitch, rate, and duration of syllables. This compensation effect maintains the auditory signal-to-noise ratio of the speaker's spoken words.
Buccal speech is an alaryngeal form of vocalization which uses the inner cheek to produce sound rather than the larynx. The speech is also known as Donald Duck talk, after the Disney character Donald Duck.

Leonid Maksimovich Brekhovskikh was a Soviet and Russian scientist known for his work in acoustical and physical oceanography.
Auditory feedback (AF) is an aid used by humans to control speech production and singing by helping the individual verify whether the current production of speech or singing is in accordance with his acoustic-auditory intention. This process is possible through what is known as the auditory feedback loop, a three-part cycle that allows individuals to first speak, then listen to what they have said, and lastly, correct it when necessary. From the viewpoint of movement sciences and neurosciences, the acoustic-auditory speech signal can be interpreted as the result of movements of speech articulators. Auditory feedback can hence be inferred as a feedback mechanism controlling skilled actions in the same way that visual feedback controls limb movements.
Temporal envelope (ENV) and temporal fine structure (TFS) are changes in the amplitude and frequency of sound perceived by humans over time. These temporal changes are responsible for several aspects of auditory perception, including loudness, pitch and timbre perception and spatial hearing.
Deniz Başkent is a Turkish-born Dutch auditory scientist who works on auditory perception. As of 2018, she is Professor of Audiology at the University Medical Center Groningen, Netherlands.