
In bioinformatics, a sequence alignment is a way of arranging the sequences of DNA, RNA, or protein to identify regions of similarity that may be a consequence of functional, structural, or evolutionary relationships between the sequences. Aligned sequences of nucleotide or amino acid residues are typically represented as rows within a matrix. Gaps are inserted between the residues so that identical or similar characters are aligned in successive columns. Sequence alignments are also used for non-biological sequences such as calculating the distance cost between strings in a natural language, or to display financial data.
In bioinformatics, BLAST is an algorithm and program for comparing primary biological sequence information, such as the amino-acid sequences of proteins or the nucleotides of DNA and/or RNA sequences. A BLAST search enables a researcher to compare a subject protein or nucleotide sequence with a library or database of sequences, and identify database sequences that resemble the query sequence above a certain threshold. For example, following the discovery of a previously unknown gene in the mouse, a scientist will typically perform a BLAST search of the human genome to see if humans carry a similar gene; BLAST will identify sequences in the human genome that resemble the mouse gene based on similarity of sequence.
In bioinformatics and biochemistry, the FASTA format is a text-based format for representing either nucleotide sequences or amino acid (protein) sequences, in which nucleotides or amino acids are represented using single-letter codes.
BioJava is an open-source software project dedicated to provide Java tools to process biological data. BioJava is a set of library functions written in the programming language Java for manipulating sequences, protein structures, file parsers, Common Object Request Broker Architecture (CORBA) interoperability, Distributed Annotation System (DAS), access to AceDB, dynamic programming, and simple statistical routines. BioJava supports a range of data, starting from DNA and protein sequences to the level of 3D protein structures. The BioJava libraries are useful for automating many daily and mundane bioinformatics tasks such as to parsing a Protein Data Bank (PDB) file, interacting with Jmol and many more. This application programming interface (API) provides various file parsers, data models and algorithms to facilitate working with the standard data formats and enables rapid application development and analysis.

Comparative genomics is a field of biological research in which the genomic features of different organisms are compared. The genomic features may include the DNA sequence, genes, gene order, regulatory sequences, and other genomic structural landmarks. In this branch of genomics, whole or large parts of genomes resulting from genome projects are compared to study basic biological similarities and differences as well as evolutionary relationships between organisms. The major principle of comparative genomics is that common features of two organisms will often be encoded within the DNA that is evolutionarily conserved between them. Therefore, comparative genomic approaches start with making some form of alignment of genome sequences and looking for orthologous sequences in the aligned genomes and checking to what extent those sequences are conserved. Based on these, genome and molecular evolution are inferred and this may in turn be put in the context of, for example, phenotypic evolution or population genetics.
In molecular biology, reading frames are defined as spans of DNA sequence between the start and stop codons. Usually, this is considered within a studied region of a prokaryotic DNA sequence, where only one of the six possible reading frames will be "open". Such an ORF may contain a start codon and by definition cannot extend beyond a stop codon. That start codon indicates where translation may start. The transcription termination site is located after the ORF, beyond the translation stop codon. If transcription were to cease before the stop codon, an incomplete protein would be made during translation.

Ensembl genome database project is a scientific project at the European Bioinformatics Institute, which provides a centralized resource for geneticists, molecular biologists and other researchers studying the genomes of our own species and other vertebrates and model organisms. Ensembl is one of several well known genome browsers for the retrieval of genomic information.
The European Bioinformatics Institute (EMBL-EBI) is an intergovernmental organization (IGO) which, as part of the European Molecular Biology Laboratory (EMBL) family, focuses on research and services in bioinformatics. It is located on the Wellcome Genome Campus in Hinxton near Cambridge, and employs over 600 full-time equivalent (FTE) staff. Institute leaders such as Rolf Apweiler, Alex Bateman, Ewan Birney, and Guy Cochrane, an adviser on the National Genomics Data Center Scientific Advisory Board, serve as part of the international research network of the BIG Data Center at the Beijing Institute of Genomics.
T-Coffee is a multiple sequence alignment software using a progressive approach. It generates a library of pairwise alignments to guide the multiple sequence alignment. It can also combine multiple sequences alignments obtained previously and in the latest versions can use structural information from PDB files (3D-Coffee). It has advanced features to evaluate the quality of the alignments and some capacity for identifying occurrence of motifs (Mocca). It produces alignment in the aln format (Clustal) by default, but can also produce PIR, MSF, and FASTA format. The most common input formats are supported.
In bioinformatics, MAFFT is a program used to create multiple sequence alignments of amino acid or nucleotide sequences. Published in 2002, the first version of MAFFT used an algorithm based on progressive alignment, in which the sequences were clustered with the help of the fast Fourier transform. Subsequent versions of MAFFT have added other algorithms and modes of operation, including options for faster alignment of large numbers of sequences, higher accuracy alignments, alignment of non-coding RNA sequences, and the addition of new sequences to existing alignments.
AMAP is a multiple sequence alignment program based on sequence annealing. This approach consists of building up the multiple alignment one match at a time, thereby circumventing many of the problems of progressive alignment. The AMAP parameters can be used to tune the sensitivity-specificity tradeoff.
BLAT is a pairwise sequence alignment algorithm that was developed by Jim Kent at the University of California Santa Cruz (UCSC) in the early 2000s to assist in the assembly and annotation of the human genome. It was designed primarily to decrease the time needed to align millions of mouse genomic reads and expressed sequence tags against the human genome sequence. The alignment tools of the time were not capable of performing these operations in a manner that would allow a regular update of the human genome assembly. Compared to pre-existing tools, BLAT was ~500 times faster with performing mRNA/DNA alignments and ~50 times faster with protein/protein alignments.

Galaxy is a scientific workflow, data integration, and data and analysis persistence and publishing platform that aims to make computational biology accessible to research scientists that do not have computer programming or systems administration experience. Although it was initially developed for genomics research, it is largely domain agnostic and is now used as a general bioinformatics workflow management system.

MicrobesOnline is a publicly and freely accessible website that hosts multiple comparative genomic tools for comparing microbial species at the genomic, transcriptomic and functional levels. MicrobesOnline was developed by the Virtual Institute for Microbial Stress and Survival, which is based at the Lawrence Berkeley National Laboratory in Berkeley, California. The site was launched in 2005, with regular updates until 2011.
The Viral Bioinformatics Resource Center (VBRC) is an online resource providing access to a database of curated viral genomes and a variety of tools for bioinformatic genome analysis. This resource was one of eight BRCs funded by NIAID with the goal of promoting research against emerging and re-emerging pathogens, particularly those seen as potential bioterrorism threats. The VBRC is now supported by Dr. Chris Upton at the University of Victoria.
FSA is a multiple sequence alignment program for aligning many proteins or RNAs or long genomic DNA sequences. Along with MUSCLE and MAFFT, FSA is one of the few sequence alignment programs which can align datasets of hundreds or thousands of sequences. FSA uses a different optimization criterion which allows it to more reliably identify non-homologous sequences than these other programs, although this increased accuracy comes at the cost of decreased speed.
The UCSC Genome Browser is an online and downloadable genome browser hosted by the University of California, Santa Cruz (UCSC). It is an interactive website offering access to genome sequence data from a variety of vertebrate and invertebrate species and major model organisms, integrated with a large collection of aligned annotations. The Browser is a graphical viewer optimized to support fast interactive performance and is an open-source, web-based tool suite built on top of a MySQL database for rapid visualization, examination, and querying of the data at many levels. The Genome Browser Database, browsing tools, downloadable data files, and documentation can all be found on the UCSC Genome Bioinformatics website.
Phyre and Phyre2 are free web-based services for protein structure prediction. Phyre is among the most popular methods for protein structure prediction having been cited over 1500 times. Like other remote homology recognition techniques, it is able to regularly generate reliable protein models when other widely used methods such as PSI-BLAST cannot. Phyre2 has been designed to ensure a user-friendly interface for users inexpert in protein structure prediction methods. Its development is funded by the Biotechnology and Biological Sciences Research Council.
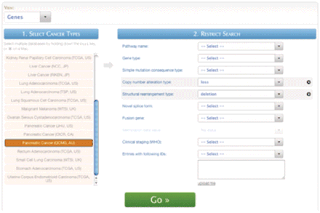
BioMart is a community-driven project to provide a single point of access to distributed research data. The BioMart project contributes open source software and data services to the international scientific community. Although the BioMart software is primarily used by the biomedical research community, it is designed in such a way that any type of data can be incorporated into the BioMart framework. The BioMart project originated at the European Bioinformatics Institute as a data management solution for the Human Genome Project. Since then, BioMart has grown to become a multi-institute collaboration involving various database projects on five continents.

In silico PCR refers to computational tools used to calculate theoretical polymerase chain reaction (PCR) results using a given set of primers (probes) to amplify DNA sequences from a sequenced genome or transcriptome.