
In genetics, a promoter is a sequence of DNA to which proteins bind to initiate transcription of a single RNA transcript from the DNA downstream of the promoter. The RNA transcript may encode a protein (mRNA), or can have a function in and of itself, such as tRNA or rRNA. Promoters are located near the transcription start sites of genes, upstream on the DNA . Promoters can be about 100–1000 base pairs long, the sequence of which is highly dependent on the gene and product of transcription, type or class of RNA polymerase recruited to the site, and species of organism.

In molecular biology, a transcription factor (TF) is a protein that controls the rate of transcription of genetic information from DNA to messenger RNA, by binding to a specific DNA sequence. The function of TFs is to regulate—turn on and off—genes in order to make sure that they are expressed in the desired cells at the right time and in the right amount throughout the life of the cell and the organism. Groups of TFs function in a coordinated fashion to direct cell division, cell growth, and cell death throughout life; cell migration and organization during embryonic development; and intermittently in response to signals from outside the cell, such as a hormone. There are 1500-1600 TFs in the human genome. Transcription factors are members of the proteome as well as regulome.

Transcription is the process of copying a segment of DNA into RNA. The segments of DNA transcribed into RNA molecules that can encode proteins are said to produce messenger RNA (mRNA). Other segments of DNA are copied into RNA molecules called non-coding RNAs (ncRNAs). mRNA comprises only 1–3% of total RNA samples. Less than 2% of the human genome can be transcribed into mRNA, while at least 80% of mammalian genomic DNA can be actively transcribed, with the majority of this 80% considered to be ncRNA.
A regulatory sequence is a segment of a nucleic acid molecule which is capable of increasing or decreasing the expression of specific genes within an organism. Regulation of gene expression is an essential feature of all living organisms and viruses.
In molecular biology and genetics, transcriptional regulation is the means by which a cell regulates the conversion of DNA to RNA (transcription), thereby orchestrating gene activity. A single gene can be regulated in a range of ways, from altering the number of copies of RNA that are transcribed, to the temporal control of when the gene is transcribed. This control allows the cell or organism to respond to a variety of intra- and extracellular signals and thus mount a response. Some examples of this include producing the mRNA that encode enzymes to adapt to a change in a food source, producing the gene products involved in cell cycle specific activities, and producing the gene products responsible for cellular differentiation in multicellular eukaryotes, as studied in evolutionary developmental biology.

The Encyclopedia of DNA Elements (ENCODE) is a public research project which aims "to build a comprehensive parts list of functional elements in the human genome."
Cis-regulatory elements (CREs) or Cis-regulatory modules (CRMs) are regions of non-coding DNA which regulate the transcription of neighboring genes. CREs are vital components of genetic regulatory networks, which in turn control morphogenesis, the development of anatomy, and other aspects of embryonic development, studied in evolutionary developmental biology.

Transcriptional repressor CTCF also known as 11-zinc finger protein or CCCTC-binding factor is a transcription factor that in humans is encoded by the CTCF gene. CTCF is involved in many cellular processes, including transcriptional regulation, insulator activity, V(D)J recombination and regulation of chromatin architecture.
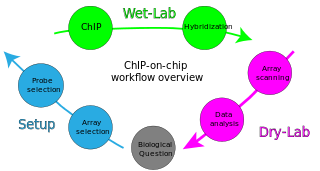
ChIP-on-chip is a technology that combines chromatin immunoprecipitation ('ChIP') with DNA microarray ("chip"). Like regular ChIP, ChIP-on-chip is used to investigate interactions between proteins and DNA in vivo. Specifically, it allows the identification of the cistrome, the sum of binding sites, for DNA-binding proteins on a genome-wide basis. Whole-genome analysis can be performed to determine the locations of binding sites for almost any protein of interest. As the name of the technique suggests, such proteins are generally those operating in the context of chromatin. The most prominent representatives of this class are transcription factors, replication-related proteins, like origin recognition complex protein (ORC), histones, their variants, and histone modifications.

D site of albumin promoter binding protein, also known as DBP, is a protein which in humans is encoded by the DBP gene.

Transcription factor SOX-6 is a protein that in humans is encoded by the SOX6 gene.
ChIP-sequencing, also known as ChIP-seq, is a method used to analyze protein interactions with DNA. ChIP-seq combines chromatin immunoprecipitation (ChIP) with massively parallel DNA sequencing to identify the binding sites of DNA-associated proteins. It can be used to map global binding sites precisely for any protein of interest. Previously, ChIP-on-chip was the most common technique utilized to study these protein–DNA relations.
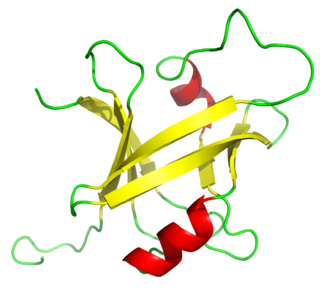
The B3 DNA binding domain (DBD) is a highly conserved domain found exclusively in transcription factors combined with other domains. It consists of 100-120 residues, includes seven beta strands and two alpha helices that form a DNA-binding pseudobarrel protein fold ; it interacts with the major groove of DNA.

DNA binding sites are a type of binding site found in DNA where other molecules may bind. DNA binding sites are distinct from other binding sites in that (1) they are part of a DNA sequence and (2) they are bound by DNA-binding proteins. DNA binding sites are often associated with specialized proteins known as transcription factors, and are thus linked to transcriptional regulation. The sum of DNA binding sites of a specific transcription factor is referred to as its cistrome. DNA binding sites also encompasses the targets of other proteins, like restriction enzymes, site-specific recombinases and methyltransferases.
Chromatin Interaction Analysis by Paired-End Tag Sequencing is a technique that incorporates chromatin immunoprecipitation (ChIP)-based enrichment, chromatin proximity ligation, Paired-End Tags, and High-throughput sequencing to determine de novo long-range chromatin interactions genome-wide.

The Basic Leucine Zipper Domain is found in many DNA binding eukaryotic proteins. One part of the domain contains a region that mediates sequence specific DNA binding properties and the leucine zipper that is required to hold together (dimerize) two DNA binding regions. The DNA binding region comprises a number of basic amino acids such as arginine and lysine. Proteins containing this domain are transcription factors.
TRANSFAC is a manually curated database of eukaryotic transcription factors, their genomic binding sites and DNA binding profiles. The contents of the database can be used to predict potential transcription factor binding sites.
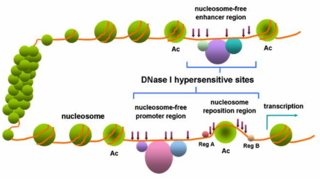
In genetics, DNase I hypersensitive sites (DHSs) are regions of chromatin that are sensitive to cleavage by the DNase I enzyme. In these specific regions of the genome, chromatin has lost its condensed structure, exposing the DNA and making it accessible. This raises the availability of DNA to degradation by enzymes, such as DNase I. These accessible chromatin zones are functionally related to transcriptional activity, since this remodeled state is necessary for the binding of proteins such as transcription factors.
Transcription factors are proteins that bind genomic regulatory sites. Identification of genomic regulatory elements is essential for understanding the dynamics of developmental, physiological and pathological processes. Recent advances in chromatin immunoprecipitation followed by sequencing (ChIP-seq) have provided powerful ways to identify genome-wide profiling of DNA-binding proteins and histone modifications. The application of ChIP-seq methods has reliably discovered transcription factor binding sites and histone modification sites.
CUT&RUN sequencing, also known as cleavage under targets and release using nuclease, is a method used to analyze protein interactions with DNA. CUT&RUN sequencing combines antibody-targeted controlled cleavage by micrococcal nuclease with massively parallel DNA sequencing to identify the binding sites of DNA-associated proteins. It can be used to map global DNA binding sites precisely for any protein of interest. Currently, ChIP-Seq is the most common technique utilized to study protein–DNA relations, however, it suffers from a number of practical and economical limitations that CUT&RUN sequencing does not.