Related Research Articles
Computational linguistics is an interdisciplinary field concerned with the computational modelling of natural language, as well as the study of appropriate computational approaches to linguistic questions. In general, computational linguistics draws upon linguistics, computer science, artificial intelligence, mathematics, logic, philosophy, cognitive science, cognitive psychology, psycholinguistics, anthropology and neuroscience, among others.

Semantics is the study of reference, meaning, or truth. The term can be used to refer to subfields of several distinct disciplines, including philosophy, linguistics and computer science.

A semantic network, or frame network is a knowledge base that represents semantic relations between concepts in a network. This is often used as a form of knowledge representation. It is a directed or undirected graph consisting of vertices, which represent concepts, and edges, which represent semantic relations between concepts, mapping or connecting semantic fields. A semantic network may be instantiated as, for example, a graph database or a concept map. Typical standardized semantic networks are expressed as semantic triples.
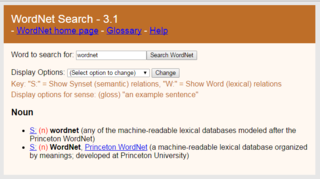
WordNet is a lexical database of semantic relations between words that links words into semantic relations including synonyms, hyponyms, and meronyms. The synonyms are grouped into synsets with short definitions and usage examples. It can thus be seen as a combination and extension of a dictionary and thesaurus. While it is accessible to human users via a web browser, its primary use is in automatic text analysis and artificial intelligence applications. It was first created in the English language and the English WordNet database and software tools have been released under a BSD style license and are freely available for download from that WordNet website. There are now WordNets in more than 200 languages.
Corpus linguistics is the study of a language as that language is expressed in its text corpus, its body of "real world" text. Corpus linguistics proposes that a reliable analysis of a language is more feasible with corpora collected in the field—the natural context ("realia") of that language—with minimal experimental interference. The large collections of text allow linguistics to run quantitative analyses on linguistic concepts, otherwise harder to quantify.
In information science, an ontology encompasses a representation, formal naming, and definitions of the categories, properties, and relations between the concepts, data, or entities that pertain to one, many, or all domains of discourse. More simply, an ontology is a way of showing the properties of a subject area and how they are related, by defining a set of terms and relational expressions that represent the entities in that subject area. The field which studies ontologies so conceived is sometimes referred to as applied ontology.
Word-sense disambiguation (WSD) is the process of identifying which sense of a word is meant in a sentence or other segment of context. In human language processing and cognition, it is usually subconscious/automatic but can often come to conscious attention when ambiguity impairs clarity of communication, given the pervasive polysemy in natural language. In computational linguistics, it is an open problem that affects other computer-related writing, such as discourse, improving relevance of search engines, anaphora resolution, coherence, and inference.

Wiktionary is a multilingual, web-based project to create a free content dictionary of terms in all natural languages and in a number of artificial languages. These entries may contain definitions, images for illustration, pronunciations, etymologies, inflections, usage examples, quotations, related terms, and translations of terms into other languages, among other features. It is collaboratively edited via a wiki. Its name is a portmanteau of the words wiki and dictionary. It is available in 192 languages and in Simple English. Like its sister project Wikipedia, Wiktionary is run by the Wikimedia Foundation, and is written collaboratively by volunteers, dubbed "Wiktionarians". Its wiki software, MediaWiki, allows almost anyone with access to the website to create and edit entries.
Semantic similarity is a metric defined over a set of documents or terms, where the idea of distance between items is based on the likeness of their meaning or semantic content as opposed to lexicographical similarity. These are mathematical tools used to estimate the strength of the semantic relationship between units of language, concepts or instances, through a numerical description obtained according to the comparison of information supporting their meaning or describing their nature. The term semantic similarity is often confused with semantic relatedness. Semantic relatedness includes any relation between two terms, while semantic similarity only includes "is a" relations. For example, "car" is similar to "bus", but is also related to "road" and "driving".
A language model is a probabilistic model of a natural language. In 1980, the first significant statistical language model was proposed, and during the decade IBM performed ‘Shannon-style’ experiments, in which potential sources for language modeling improvement were identified by observing and analyzing the performance of human subjects in predicting or correcting text.

Automatic image annotation is the process by which a computer system automatically assigns metadata in the form of captioning or keywords to a digital image. This application of computer vision techniques is used in image retrieval systems to organize and locate images of interest from a database.
Frame semantics is a theory of linguistic meaning developed by Charles J. Fillmore that extends his earlier case grammar. It relates linguistic semantics to encyclopedic knowledge. The basic idea is that one cannot understand the meaning of a single word without access to all the essential knowledge that relates to that word. For example, one would not be able to understand the word "sell" without knowing anything about the situation of commercial transfer, which also involves, among other things, a seller, a buyer, goods, money, the relation between the money and the goods, the relations between the seller and the goods and the money, the relation between the buyer and the goods and the money and so on. Thus, a word activates, or evokes, a frame of semantic knowledge relating to the specific concept to which it refers.
In digital lexicography, natural language processing, and digital humanities, a lexical resource is a language resource consisting of data regarding the lexemes of the lexicon of one or more languages e.g., in the form of a database.
MicrosoftEncarta is a discontinued digital multimedia encyclopedia published by Microsoft from 1993 to 2009. Originally sold on CD-ROM or DVD, it was also available online via annual subscription, although later articles could also be viewed for free online with advertisements. By 2008, the complete English version, Encarta Premium, consisted of more than 62,000 articles, numerous photos and illustrations, music clips, videos, interactive content, timelines, maps, atlases and homework tools.
RetrievalWare is an enterprise search engine emphasizing natural language processing and semantic networks which was commercially available from 1992 to 2007 and is especially known for its use by government intelligence agencies.
Junction grammar is a descriptive model of language developed during the 1960s by Eldon G. Lytle (1936–2010).
BabelNet is a multilingual lexicalized semantic network and ontology developed at the NLP group of the Sapienza University of Rome. BabelNet was automatically created by linking Wikipedia to the most popular computational lexicon of the English language, WordNet. The integration is done using an automatic mapping and by filling in lexical gaps in resource-poor languages by using statistical machine translation. The result is an encyclopedic dictionary that provides concepts and named entities lexicalized in many languages and connected with large amounts of semantic relations. Additional lexicalizations and definitions are added by linking to free-license wordnets, OmegaWiki, the English Wiktionary, Wikidata, FrameNet, VerbNet and others. Similarly to WordNet, BabelNet groups words in different languages into sets of synonyms, called Babel synsets. For each Babel synset, BabelNet provides short definitions in many languages harvested from both WordNet and Wikipedia.
The following outline is provided as an overview of and topical guide to natural-language processing:
UBY is a large-scale lexical-semantic resource for natural language processing (NLP) developed at the Ubiquitous Knowledge Processing Lab (UKP) in the department of Computer Science of the Technische Universität Darmstadt . UBY is based on the ISO standard Lexical Markup Framework (LMF) and combines information from several expert-constructed and collaboratively constructed resources for English and German.
Almaany is a free online Arabic dictionary. According to The Routledge Course on Media, Legal and Technical Translation, Almaany has more than thirty different search domains, including accounting, agriculture, computer, social, legal, et cetera. It has Arabic to English translations and English to Arabic, as well as a significant quantity of technical terminology. It is very useful to translators as its search results are given in context. Almaany offers correspondent meanings for Arabic terms with semantically similar words and is widely used in Arabic language research. Researchers such as Touahri and Mazroui have used Almaany to "explain difficult meaning lemmas" in their published results.
References
- ↑ Montemagni, S. & L. Vanderwende (1992). "Structural Patterns vs. string patterns for extracting semantic information from dictionaries". Proceedings of COLING92: 546–552.
- ↑ Dolan, William B., L. Vanderwende, and S. Richardson. (1993). "Automatically Deriving Structured Knowledge Bases from On-line Dictionaries". Proceedings of the Pacific Association for Computational Linguistics.
{{cite journal}}: CS1 maint: multiple names: authors list (link) - ↑ Dolan, William B., L. Vanderwende, and S. Richardson (1993). "Combining Dictionary-based and Example-based Methods for Natural Language Analysis". Proceedings of the Fifth International Conference on Theoretical and Methodological Issues in Machine Translation: 69–79.
{{cite journal}}: CS1 maint: multiple names: authors list (link) - ↑ Chan, Sin-Wai (2015). Routledge Encyclopedia of Translation Technology. Oxon: Routledge. p. 430. ISBN 9780415524841.
- ↑ Ågotnes, Thomas (2011). Stairs 2010: Proceedings of the Fifth Starting AI Researchers' Symposium. Amsterdam: IOS Press. p. 201. ISBN 9781607506751.
- 1 2 Allan, Keith (2009). Concise Encyclopedia of Semantics. Oxford: Elsevier Ltd. p. 493. ISBN 9780080959689.
- ↑ Buderi, Robert (2000). Engines of Tomorrow . Simon and Schuster. p. 358. ISBN 9780684839004.
| | This computing article is a stub. You can help Wikipedia by expanding it. |