Knowledge representation and reasoning is the field of artificial intelligence (AI) dedicated to representing information about the world in a form that a computer system can use to solve complex tasks such as diagnosing a medical condition or having a dialog in a natural language. Knowledge representation incorporates findings from psychology about how humans solve problems, and represent knowledge in order to design formalisms that will make complex systems easier to design and build. Knowledge representation and reasoning also incorporates findings from logic to automate various kinds of reasoning.

Semantics is the study of reference, meaning, or truth. The term can be used to refer to subfields of several distinct disciplines, including philosophy, linguistics and computer science.

The Semantic Web, sometimes known as Web 3.0, is an extension of the World Wide Web through standards set by the World Wide Web Consortium (W3C). The goal of the Semantic Web is to make Internet data machine-readable.
In information science, an ontology encompasses a representation, formal naming, and definitions of the categories, properties, and relations between the concepts, data, or entities that pertain to one, many, or all domains of discourse. More simply, an ontology is a way of showing the properties of a subject area and how they are related, by defining a set of terms and relational expressions that represent the entities in that subject area. The field which studies ontologies so conceived is sometimes referred to as applied ontology.
Description logics (DL) are a family of formal knowledge representation languages. Many DLs are more expressive than propositional logic but less expressive than first-order logic. In contrast to the latter, the core reasoning problems for DLs are (usually) decidable, and efficient decision procedures have been designed and implemented for these problems. There are general, spatial, temporal, spatiotemporal, and fuzzy description logics, and each description logic features a different balance between expressive power and reasoning complexity by supporting different sets of mathematical constructors.
The Web Ontology Language (OWL) is a family of knowledge representation languages for authoring ontologies. Ontologies are a formal way to describe taxonomies and classification networks, essentially defining the structure of knowledge for various domains: the nouns representing classes of objects and the verbs representing relations between the objects.
Semantic integration is the process of interrelating information from diverse sources, for example calendars and to do lists, email archives, presence information, documents of all sorts, contacts, search results, and advertising and marketing relevance derived from them. In this regard, semantics focuses on the organization of and action upon information by acting as an intermediary between heterogeneous data sources, which may conflict not only by structure but also context or value.
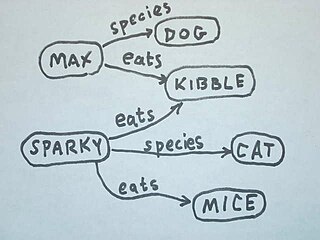
The ultimate goal of semantic technology is to help machines understand data. To enable the encoding of semantics with the data, well-known technologies are RDF and OWL. These technologies formally represent the meaning involved in information. For example, ontology can describe concepts, relationships between things, and categories of things. These embedded semantics with the data offer significant advantages such as reasoning over data and dealing with heterogeneous data sources.
F-logic is a knowledge representation and ontology language. F-logic combines the advantages of conceptual modeling with object-oriented, frame-based languages and offers a declarative, compact and simple syntax, as well as the well-defined semantics of a logic-based language.
Gellish is an ontology language for data storage and communication, designed and developed by Andries van Renssen since mid-1990s. It started out as an engineering modeling language but evolved into a universal and extendable conceptual data modeling language with general applications. Because it includes domain-specific terminology and definitions, it is also a semantic data modelling language and the Gellish modeling methodology is a member of the family of semantic modeling methodologies.
The CIDOC Conceptual Reference Model (CRM) provides an extensible ontology for concepts and information in cultural heritage and museum documentation. It is the international standard (ISO 21127:2023) for the controlled exchange of cultural heritage information. Galleries, libraries, archives, museums (GLAMs), and other cultural institutions are encouraged to use the CIDOC CRM to enhance accessibility to museum-related information and knowledge.
The concept of the Social Semantic Web subsumes developments in which social interactions on the Web lead to the creation of explicit and semantically rich knowledge representations. The Social Semantic Web can be seen as a Web of collective knowledge systems, which are able to provide useful information based on human contributions and which get better as more people participate. The Social Semantic Web combines technologies, strategies and methodologies from the Semantic Web, social software and the Web 2.0.
DOGMA, short for Developing Ontology-Grounded Methods and Applications, is the name of research project in progress at Vrije Universiteit Brussel's STARLab, Semantics Technology and Applications Research Laboratory. It is an internally funded project, concerned with the more general aspects of extracting, storing, representing and browsing information.
The Semantics of Business Vocabulary and Business Rules (SBVR) is an adopted standard of the Object Management Group (OMG) intended to be the basis for formal and detailed natural language declarative description of a complex entity, such as a business. SBVR is intended to formalize complex compliance rules, such as operational rules for an enterprise, security policy, standard compliance, or regulatory compliance rules. Such formal vocabularies and rules can be interpreted and used by computer systems. SBVR is an integral part of the OMG's model-driven architecture (MDA).
Amit Sheth is a computer scientist at University of South Carolina in Columbia, South Carolina. He is the founding Director of the Artificial Intelligence Institute, and a Professor of Computer Science and Engineering. From 2007 to June 2019, he was the Lexis Nexis Ohio Eminent Scholar, director of the Ohio Center of Excellence in Knowledge-enabled Computing, and a Professor of Computer Science at Wright State University. Sheth's work has been cited by over 48,800 publications. He has an h-index of 106, which puts him among the top 100 computer scientists with the highest h-index. Prior to founding the Kno.e.sis Center, he served as the director of the Large Scale Distributed Information Systems Lab at the University of Georgia in Athens, Georgia.

A semantic data model (SDM) is a high-level semantics-based database description and structuring formalism for databases. This database model is designed to capture more of the meaning of an application environment than is possible with contemporary database models. An SDM specification describes a database in terms of the kinds of entities that exist in the application environment, the classifications and groupings of those entities, and the structural interconnections among them. SDM provides a collection of high-level modeling primitives to capture the semantics of an application environment. By accommodating derived information in a database structural specification, SDM allows the same information to be viewed in several ways; this makes it possible to directly accommodate the variety of needs and processing requirements typically present in database applications. The design of the present SDM is based on our experience in using a preliminary version of it. SDM is designed to enhance the effectiveness and usability of database systems. An SDM database description can serve as a formal specification and documentation tool for a database; it can provide a basis for supporting a variety of powerful user interface facilities, it can serve as a conceptual database model in the database design process; and, it can be used as the database model for a new kind of database management system.

In computer science, information science and systems engineering, ontology engineering is a field which studies the methods and methodologies for building ontologies, which encompasses a representation, formal naming and definition of the categories, properties and relations between the concepts, data and entities of a given domain of interest. In a broader sense, this field also includes a knowledge construction of the domain using formal ontology representations such as OWL/RDF. A large-scale representation of abstract concepts such as actions, time, physical objects and beliefs would be an example of ontological engineering. Ontology engineering is one of the areas of applied ontology, and can be seen as an application of philosophical ontology. Core ideas and objectives of ontology engineering are also central in conceptual modeling.
Knowledge extraction is the creation of knowledge from structured and unstructured sources. The resulting knowledge needs to be in a machine-readable and machine-interpretable format and must represent knowledge in a manner that facilitates inferencing. Although it is methodically similar to information extraction (NLP) and ETL, the main criterion is that the extraction result goes beyond the creation of structured information or the transformation into a relational schema. It requires either the reuse of existing formal knowledge or the generation of a schema based on the source data.
In the Semantic Web and in knowledge representation, a metaclass is a class whose instances can themselves be classes. Similar to their role in programming languages, metaclasses in Semantic Web languages can have properties otherwise applicable only to individuals, while retaining the same class's ability to be classified in a concept hierarchy. This enables knowledge about instances of those metaclasses to be inferred by semantic reasoners using statements made in the metaclass. Metaclasses thus enhance the expressivity of knowledge representations in a way that can be intuitive for users. While classes are suitable to represent a population of individuals, metaclasses can, as one of their feature, be used to represent the conceptual dimension of an ontology. Metaclasses are supported in the ontology language OWL and the data-modeling vocabulary RDFS.
The Computer Science Ontology (CSO) is an automatically generated taxonomy of research topics in the field of Computer Science. It was produced by the Open University in collaboration with Springer Nature by running an information extraction system over a large corpus of scientific articles. Several branches were manually improved by domain experts. The current version includes about 14K research topics and 160K semantic relationships.