Related Research Articles

A base pair (bp) is a fundamental unit of double-stranded nucleic acids consisting of two nucleobases bound to each other by hydrogen bonds. They form the building blocks of the DNA double helix and contribute to the folded structure of both DNA and RNA. Dictated by specific hydrogen bonding patterns, "Watson–Crick" base pairs allow the DNA helix to maintain a regular helical structure that is subtly dependent on its nucleotide sequence. The complementary nature of this based-paired structure provides a redundant copy of the genetic information encoded within each strand of DNA. The regular structure and data redundancy provided by the DNA double helix make DNA well suited to the storage of genetic information, while base-pairing between DNA and incoming nucleotides provides the mechanism through which DNA polymerase replicates DNA and RNA polymerase transcribes DNA into RNA. Many DNA-binding proteins can recognize specific base-pairing patterns that identify particular regulatory regions of genes.

Nucleic acids are biopolymers, or large biomolecules, essential to all known forms of life. They are composed of nucleotides, which are the monomers made of three components: a 5-carbon sugar, a phosphate group and a nitrogenous base. The two main classes of nucleic acids are deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). If the sugar is ribose, the polymer is RNA; if the sugar is the ribose derivative deoxyribose, the polymer is DNA.

Nucleotides are organic molecules consisting of a nucleoside and a phosphate. They serve as monomeric units of the nucleic acid polymers – deoxyribonucleic acid (DNA) and ribonucleic acid (RNA), both of which are essential biomolecules within all life-forms on Earth. Nucleotides are obtained in the diet and are also synthesized from common nutrients by the liver.

Protein biosynthesis is a core biological process, occurring inside cells, balancing the loss of cellular proteins through the production of new proteins. Proteins perform a number of critical functions as enzymes, structural proteins or hormones. Protein synthesis is a very similar process for both prokaryotes and eukaryotes but there are some distinct differences.
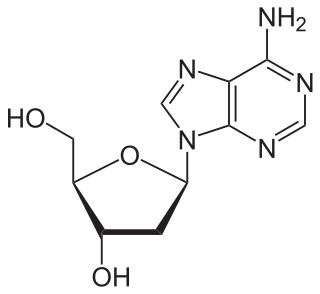
Nucleosides are glycosylamines that can be thought of as nucleotides without a phosphate group. A nucleoside consists simply of a nucleobase (also termed a nitrogenous base) and a five-carbon sugar (ribose or 2'-deoxyribose) whereas a nucleotide is composed of a nucleobase, a five-carbon sugar, and one or more phosphate groups. In a nucleoside, the anomeric carbon is linked through a glycosidic bond to the N9 of a purine or the N1 of a pyrimidine. Examples of nucleosides include cytidine, [ alcohol group (-CH2-OH) to produce nucleotides. Nucleotides are the molecular building-blocks of DNA and RNA.
A phosphodiesterase (PDE) is an enzyme that breaks a phosphodiester bond. Usually, phosphodiesterase refers to cyclic nucleotide phosphodiesterases, which have great clinical significance and are described below. However, there are many other families of phosphodiesterases, including phospholipases C and D, autotaxin, sphingomyelin phosphodiesterase, DNases, RNases, and restriction endonucleases, as well as numerous less-well-characterized small-molecule phosphodiesterases.
Biosynthesis is a multi-step, enzyme-catalyzed process where substrates are converted into more complex products in living organisms. In biosynthesis, simple compounds are modified, converted into other compounds, or joined together to form macromolecules. This process often consists of metabolic pathways. Some of these biosynthetic pathways are located within a single cellular organelle, while others involve enzymes that are located within multiple cellular organelles. Examples of these biosynthetic pathways include the production of lipid membrane components and nucleotides. Biosynthesis is usually synonymous with anabolism.

Terminal deoxynucleotidyl transferase (TdT), also known as DNA nucleotidylexotransferase (DNTT) or terminal transferase, is a specialized DNA polymerase expressed in immature, pre-B, pre-T lymphoid cells, and acute lymphoblastic leukemia/lymphoma cells. TdT adds N-nucleotides to the V, D, and J exons of the TCR and BCR genes during antibody gene recombination, enabling the phenomenon of junctional diversity. In humans, terminal transferase is encoded by the DNTT gene. As a member of the X family of DNA polymerase enzymes, it works in conjunction with polymerase λ and polymerase μ, both of which belong to the same X family of polymerase enzymes. The diversity introduced by TdT has played an important role in the evolution of the vertebrate immune system, significantly increasing the variety of antigen receptors that a cell is equipped with to fight pathogens. Studies using TdT knockout mice have found drastic reductions (10-fold) in T-cell receptor (TCR) diversity compared with that of normal, or wild-type, systems. The greater diversity of TCRs that an organism is equipped with leads to greater resistance to infection. Although TdT was one of the first DNA polymerases identified in mammals in 1960, it remains one of the least understood of all DNA polymerases. In 2016–18, TdT was discovered to demonstrate in trans template dependant behaviour in addition to its more broadly known template independent behaviour
V(D)J recombination is the mechanism of somatic recombination that occurs only in developing lymphocytes during the early stages of T and B cell maturation. It results in the highly diverse repertoire of antibodies/immunoglobulins and T cell receptors (TCRs) found in B cells and T cells, respectively. The process is a defining feature of the adaptive immune system.
Sialyltransferases are enzymes that transfer sialic acid to nascent oligosaccharide. Each sialyltransferase is specific for a particular sugar substrate. Sialyltransferases add sialic acid to the terminal portions of the sialylated glycolipids (gangliosides) or to the N- or O-linked sugar chains of glycoproteins.
In enzymology, a polynucleotide adenylyltransferase is an enzyme that catalyzes the chemical reaction

Potassium/sodium hyperpolarization-activated cyclic nucleotide-gated ion channel 2 is a protein that in humans is encoded by the HCN2 gene.
Potassium/sodium hyperpolarization-activated cyclic nucleotide-gated channel 4 is a protein that in humans is encoded by the HCN4 gene.

Potassium/sodium hyperpolarization-activated cyclic nucleotide-gated channel 1 is a protein that in humans is encoded by the HCN1 gene.
Hyperpolarization-activated cyclic nucleotide–gated (HCN) channels are integral membrane proteins that serve as nonselective voltage-gated cation channels in the plasma membranes of heart and brain cells. HCN channels are sometimes referred to as pacemaker channels because they help to generate rhythmic activity within groups of heart and brain cells. HCN channels are encoded by four genes and are widely expressed throughout the heart and the central nervous system.

Junctional diversity describes the DNA sequence variations introduced by the improper joining of gene segments during the process of V(D)J recombination. This process of V(D)J recombination has vital roles for the vertebrate immune system, as it is able to generate a huge repertoire of different T-cell receptor (TCR) and immunoglobulin molecules required for pathogen antigen recognition by T-cells and B cells, respectively. The inaccuracies of joining provided by junctional diversity is estimated to triple the diversity initially generated by these V(D)J recombinations.

Dock11, also known as Zizimin2, is a large protein involved in intracellular signalling networks. It is a member of the DOCK-D subfamily of the DOCK family of guanine nucleotide exchange factors (GEFs) which function as activators of small G proteins. Dock11 activates the small G protein Cdc42.
EF-Ts is one of the prokaryotic elongation factors. It is found in human mitochrondria as TSFM. It is similar to eukaryotic EF-1B.
The European Nucleotide Archive (ENA) is a repository providing free and unrestricted access to annotated DNA and RNA sequences. It also stores complementary information such as experimental procedures, details of sequence assembly and other metadata related to sequencing projects. The archive is composed of three main databases: the Sequence Read Archive, the Trace Archive and the EMBL Nucleotide Sequence Database. The ENA is produced and maintained by the European Bioinformatics Institute and is a member of the International Nucleotide Sequence Database Collaboration (INSDC) along with the DNA Data Bank of Japan and GenBank.
Sequence saturation mutagenesis (SeSaM) is a chemo-enzymatic random mutagenesis method applied for the directed evolution of proteins and enzymes. It is one of the most common saturation mutagenesis techniques. In four PCR-based reaction steps, phosphorothioate nucleotides are inserted in the gene sequence, cleaved and the resulting fragments elongated by universal or degenerate nucleotides. These nucleotides are then replaced by standard nucleotides, allowing for a broad distribution of nucleic acid mutations spread over the gene sequence with a preference to transversions and with a unique focus on consecutive point mutations, both difficult to generate by other mutagenesis techniques. The technique was developed by Professor Ulrich Schwaneberg at Jacobs University Bremen and RWTH Aachen University.
References
- ↑ Sandor, Z; Calicchio, ML; Sargent, RG; Roth, DB; Wilson, JH (2004). "Distinct requirements for Ku in N nucleotide addition at V(D)J- and non-V(D)J-generated double-strand breaks". Nucleic Acids Res. 32 (6): 1866–73. doi:10.1093/nar/gkh502. PMC 390357 . PMID 15047854.