Related Research Articles
A relational database is a database based on the relational model of data, as proposed by E. F. Codd in 1970. A system used to maintain relational databases is a relational database management system (RDBMS). Many relational database systems are equipped with the option of using SQL for querying and updating the database.
The relational model (RM) is an approach to managing data using a structure and language consistent with first-order predicate logic, first described in 1969 by English computer scientist Edgar F. Codd, where all data is represented in terms of tuples, grouped into relations. A database organized in terms of the relational model is a relational database.
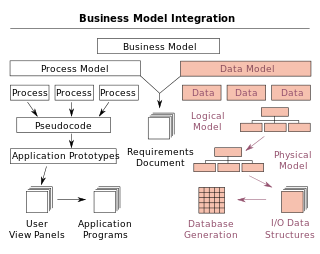
A data model is an abstract model that organizes elements of data and standardizes how they relate to one another and to the properties of real-world entities. For instance, a data model may specify that the data element representing a car be composed of a number of other elements which, in turn, represent the color and size of the car and define its owner.
In relational database theory, a functional dependency is a constraint between two sets of attributes in a relation from a database. In other words, a functional dependency is a constraint between two attributes in a relation. Given a relation R and sets of attributes , X is said to functionally determineY if and only if each X value in R is associated with precisely one Y value in R; R is then said to satisfy the functional dependency X → Y. Equivalently, the projection is a function, i.e. Y is a function of X. In simple words, if the values for the X attributes are known, then the values for the Y attributes corresponding to x can be determined by looking them up in any tuple of R containing x. Customarily X is called the determinant set and Y the dependent set. A functional dependency FD: X → Y is called trivial if Y is a subset of X.

In computing, extract, transform, load (ETL) is a three-phase process where data is extracted, transformed and loaded into an output data container. The data can be collated from one or more sources and it can also be output to one or more destinations. ETL processing is typically executed using software applications but it can also be done manually by system operators. ETL software typically automates the entire process and can be run manually or on reoccurring schedules either as single jobs or aggregated into a batch of jobs.
In the relational model of databases, a primary key is a specific choice of a minimal set of attributes (columns) that uniquely specify a tuple (row) in a relation (table). Informally, a primary key is "which attributes identify a record," and in simple cases constitute a single attribute: a unique ID. More formally, a primary key is a choice of candidate key ; any other candidate key is an alternate key.
A foreign key is a set of attributes in a table that refers to the primary key of another table. The foreign key links these two tables. Another way to put it: In the context of relational databases, a foreign key is a set of attributes subject to a certain kind of inclusion dependency constraints, specifically a constraint that the tuples consisting of the foreign key attributes in one relation, R, must also exist in some other relation, S, and furthermore that those attributes must also be a candidate key in S. In simpler words, a foreign key is a set of attributes that references a candidate key. For example, a table called TEAM may have an attribute, MEMBER_NAME, which is a foreign key referencing a candidate key, PERSON_NAME, in the PERSON table. Since MEMBER_NAME is a foreign key, any value existing as the name of a member in TEAM must also exist as a person's name in the PERSON table; in other words, every member of a TEAM is also a PERSON.
A surrogate key in a database is a unique identifier for either an entity in the modeled world or an object in the database. The surrogate key is not derived from application data, unlike a natural key.

An entity–relationship model describes interrelated things of interest in a specific domain of knowledge. A basic ER model is composed of entity types and specifies relationships that can exist between entities.
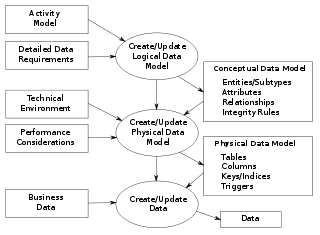
Data modeling in software engineering is the process of creating a data model for an information system by applying certain formal techniques. It may be applied as part of broader Model-driven engineering (MDD) concept.

In computing, the star schema is the simplest style of data mart schema and is the approach most widely used to develop data warehouses and dimensional data marts. The star schema consists of one or more fact tables referencing any number of dimension tables. The star schema is an important special case of the snowflake schema, and is more effective for handling simpler queries.
In database design, a composite key is a candidate key that consists of two or more attributes that together uniquely identify an entity occurrence. A compound key is a composite key for which each attribute that makes up the key is a foreign key in its own right.
The object–relational impedance mismatch is a set of conceptual and technical difficulties that are often encountered when organizations stored data in relational data stores and then being addressed and used by domain-driven object models, the default method of implementing business-centric objects in object-oriented programming languages. The problems arise not from a failure of addressing data as relational nor as domain objects, but as a result of the difficulty of implementing a data mapping between the data values of the two conceptually different logic models; both models are logical models that can be implemented differently depending upon the implementation technology utilized. These issues are not limited to applications, but exists across an enterprise, whenever data is stored in a relational manner then utilized as domain-driven object models, and vice versa. These difficulties are sometimes mitigated by use of a object-oriented data store, but that too has its own set of implementation difficulties.

Integration DEFinition for information modeling (IDEF1X) is a data modeling language for the development of semantic data models. IDEF1X is used to produce a graphical information model which represents the structure and semantics of information within an environment or system.
In relational database management systems, a unique key is a candidate key. All the candidate keys of a relation can uniquely identify the records of the relation, but only one of them is used as the primary key of the relation. The remaining candidate keys are called unique keys because they can uniquely identify a record in a relation. Unique keys can consist of multiple columns. Unique keys are also called alternate keys. Unique keys are an alternative to the primary key of the relation. In SQL, the unique keys have a UNIQUE constraint assigned to them in order to prevent duplicates. Alternate keys may be used like the primary key when doing a single-table select or when filtering in a where clause, but are not typically used to join multiple tables.
A database refactoring is a simple change to a database schema that improves its design while retaining both its behavioral and informational semantics. Database refactoring does not change the way data is interpreted or used and does not fix bugs or add new functionality. Every refactoring to a database leaves the system in a working state, thus not causing maintenance lags, provided the meaningful data exists in the production environment.

A database model is a type of data model that determines the logical structure of a database. It fundamentally determines in which manner data can be stored, organized and manipulated. The most popular example of a database model is the relational model, which uses a table-based format.

Data vault modeling is a database modeling method that is designed to provide long-term historical storage of data coming in from multiple operational systems. It is also a method of looking at historical data that deals with issues such as auditing, tracing of data, loading speed and resilience to change as well as emphasizing the need to trace where all the data in the database came from. This means that every row in a data vault must be accompanied by record source and load date attributes, enabling an auditor to trace values back to the source. The concept was published in 2000 by Dan Linstedt.

In database theory, a relation, as originally defined by E. F. Codd, is a set of tuples (d1, d2, ..., dn), where each element dj is a member of Dj, a data domain. Codd's original definition notwithstanding, and contrary to the usual definition in mathematics, there is no ordering to the elements of the tuples of a relation. Instead, each element is termed an attribute value. An attribute is a name paired with a domain. An attribute value is an attribute name paired with an element of that attribute's domain, and a tuple is a set of attribute values in which no two distinct elements have the same name. Thus, in some accounts, a tuple is described as a function, mapping names to values.
The following is provided as an overview of and topical guide to databases:
References
- ↑ Data modelling: What exactly is a Business Key? by Roy, Rajiv Max. 19 November 2020. Retrieved 1 August 2022.
- ↑ Auto Keys Versus Domain Keys
- ↑ Intelligent Versus Surrogate Keys
- ↑ "[CONFSERVER-2524] Enable creation of same-named pages within a space - Create and track feature requests for Atlassian products".