See also
- Illumina Inc. and its beadArray technology
- lumi Bioconductor package of processing Illumina expression microarray
The nucleotide universal IDentifier (nuID) in molecular biology, is designed to uniquely and globally identify oligonucleotide microarray probes.
Oligonucleotide probes of microarrays that are sequence identical may have different identifiers between manufacturers and even between different versions of the same company's microarray; and sometimes the same identifier is reused and represents a completely different oligonucleotide, resulting in ambiguity and potentially mis-identification of the genes hybridizing to that probe. This also makes data interpretation and integration of different batches of data difficult. nuID was designed to solve these problems. It is a unique, non-degenerate encoding scheme that can be used as a universal representation to identify an oligonucleotide across manufacturers. The design of nuID was inspired by the fact that the raw sequence of the oligonucleotide is the true definition of identity for a probe, the encoding algorithm uniquely and non-degenerately transforms the sequence itself into a compact identifier (a lossless compression). In addition, a redundancy check (checksum) was added to validate the integrity of the identifier. These two steps, encoding plus checksum, result in an nuID, which is a unique, non-degenerate, permanent, robust and efficient representation of the probe sequence. For commercial applications that require the sequence identity to be confidential, encryption schema can also be added for nuID. The utility of nuIDs has been implemented for the annotation of Illumina microarrays, which can be downloaded from Bioconductor website . It also has universal applicability as a source-independent naming convention for oligomers.
The nuID schema has three significant advantages over using the oligo sequence directly as an identifier: first it is more compact due to the base-64 encoding; second, it has a built-in error detection and self-identification; and third, it can be encrypted in cases where the sequences are preferred not to be disclosed. For more details, please refer to the nuID paper. [1] The implementation nuID encoding and decoding algorithms can be found in the lumi package or at
Oligonucleotides are short DNA or RNA molecules, oligomers, that have a wide range of applications in genetic testing, research, and forensics. Commonly made in the laboratory by solid-phase chemical synthesis, these small bits of nucleic acids can be manufactured as single-stranded molecules with any user-specified sequence, and so are vital for artificial gene synthesis, polymerase chain reaction (PCR), DNA sequencing, molecular cloning and as molecular probes. In nature, oligonucleotides are usually found as small RNA molecules that function in the regulation of gene expression, or are degradation intermediates derived from the breakdown of larger nucleic acid molecules.

A DNA microarray is a collection of microscopic DNA spots attached to a solid surface. Scientists use DNA microarrays to measure the expression levels of large numbers of genes simultaneously or to genotype multiple regions of a genome. Each DNA spot contains picomoles of a specific DNA sequence, known as probes. These can be a short section of a gene or other DNA element that are used to hybridize a cDNA or cRNA sample under high-stringency conditions. Probe-target hybridization is usually detected and quantified by detection of fluorophore-, silver-, or chemiluminescence-labeled targets to determine relative abundance of nucleic acid sequences in the target. The original nucleic acid arrays were macro arrays approximately 9 cm × 12 cm and the first computerized image based analysis was published in 1981. It was invented by Patrick O. Brown. An example of its application is in SNPs arrays for polymorphisms in cardiovascular diseases, cancer, pathogens and GWAS analysis. It is also used for the identification of structural variations and the measurement of gene expression.
In bioinformatics and biochemistry, the FASTA format is a text-based format for representing either nucleotide sequences or amino acid (protein) sequences, in which nucleotides or amino acids are represented using single-letter codes. The format also allows for sequence names and comments to precede the sequences. The format originates from the FASTA software package, but has now become a near universal standard in the field of bioinformatics.
A geocode is a code that represents a geographic entity. It is a unique identifier of the entity, to distinguish it from others in a finite set of geographic entities. In general the geocode is a human-readable and short identifier.

The Electronic Product Code (EPC) is designed as a universal identifier that provides a unique identity for every physical object anywhere in the world, for all time. The EPC structure is defined in the EPCglobal Tag Data Standard, which is an open standard freely available for download from the website of EPCglobal, Inc. The canonical representation of an EPC is a URI, namely the 'pure-identity URI' representation that is intended for use when referring to a specific physical object in communications about EPCs among information systems and business application software.
Bioconductor is a free, open source and open development software project for the analysis and comprehension of genomic data generated by wet lab experiments in molecular biology.

In the field of molecular biology, gene expression profiling is the measurement of the activity of thousands of genes at once, to create a global picture of cellular function. These profiles can, for example, distinguish between cells that are actively dividing, or show how the cells react to a particular treatment. Many experiments of this sort measure an entire genome simultaneously, that is, every gene present in a particular cell.
Genotyping is the process of determining differences in the genetic make-up (genotype) of an individual by examining the individual's DNA sequence using biological assays and comparing it to another individual's sequence or a reference sequence. It reveals the alleles an individual has inherited from their parents. Traditionally genotyping is the use of DNA sequences to define biological populations by use of molecular tools. It does not usually involve defining the genes of an individual.

Microarray analysis techniques are used in interpreting the data generated from experiments on DNA, RNA, and protein microarrays, which allow researchers to investigate the expression state of a large number of genes - in many cases, an organism's entire genome - in a single experiment. Such experiments can generate very large amounts of data, allowing researchers to assess the overall state of a cell or organism. Data in such large quantities is difficult - if not impossible - to analyze without the help of computer programs.
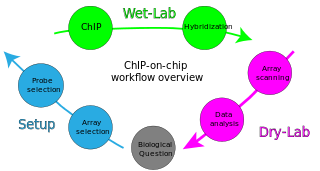
ChIP-on-chip is a technology that combines chromatin immunoprecipitation ('ChIP') with DNA microarray ("chip"). Like regular ChIP, ChIP-on-chip is used to investigate interactions between proteins and DNA in vivo. Specifically, it allows the identification of the cistrome, the sum of binding sites, for DNA-binding proteins on a genome-wide basis. Whole-genome analysis can be performed to determine the locations of binding sites for almost any protein of interest. As the name of the technique suggests, such proteins are generally those operating in the context of chromatin. The most prominent representatives of this class are transcription factors, replication-related proteins, like origin recognition complex protein (ORC), histones, their variants, and histone modifications.
lumi is a free, open source and open development software project for the analysis and comprehension of Illumina expression and methylation microarray data. The project was started in the summer of 2006 and set out to provide algorithms and data management tools of Illumina in the framework of Bioconductor. It is based on the statistical R programming language.

SOLiD (Sequencing by Oligonucleotide Ligation and Detection) is a next-generation DNA sequencing technology developed by Life Technologies and has been commercially available since 2006. This next generation technology generates 108 - 109 small sequence reads at one time. It uses 2 base encoding to decode the raw data generated by the sequencing platform into sequence data.

Tiling arrays are a subtype of microarray chips. Like traditional microarrays, they function by hybridizing labeled DNA or RNA target molecules to probes fixed onto a solid surface.
The Illumina Methylation Assay using the Infinium I platform uses 'BeadChip' technology to generate a comprehensive genome-wide profiling of human DNA methylation. Similar to bisulfite sequencing and pyrosequencing, this method quantifies methylation levels at various loci within the genome. This assay is used for methylation probes on the Illumina Infinium HumanMethylation27 BeadChip. Probes on the 27k array target regions of the human genome to measure methylation levels at 27,578 CpG dinucleotides in 14,495 genes. The Infinium HumanMethylation450 BeadChip array targets > 450,000 methylation sites.

MAGIChips, also known as "microarrays of gel-immobilized compounds on a chip" or "three-dimensional DNA microarrays", are devices for molecular hybridization produced by immobilizing oligonucleotides, DNA, enzymes, antibodies, and other compounds on a photopolymerized micromatrix of polyacrylamide gel pads of 100x100x20µm or smaller size. This technology is used for analysis of nucleic acid hybridization, specific binding of DNA, and low-molecular weight compounds with proteins, and protein-protein interactions.
FASTQ format is a text-based format for storing both a biological sequence and its corresponding quality scores. Both the sequence letter and quality score are each encoded with a single ASCII character for brevity.
DNA-encoded chemical libraries (DEL) is a technology for the synthesis and screening on unprecedented scale of collections of small molecule compounds. DEL is used in medicinal chemistry to bridge the fields of combinatorial chemistry and molecular biology. The aim of DEL technology is to accelerate the drug discovery process and in particular early phase discovery activities such as target validation and hit identification.
Massive parallel signature sequencing (MPSS) is a procedure that is used to identify and quantify mRNA transcripts, resulting in data similar to serial analysis of gene expression (SAGE), although it employs a series of biochemical and sequencing steps that are substantially different.
Transcriptomics technologies are the techniques used to study an organism's transcriptome, the sum of all of its RNA transcripts. The information content of an organism is recorded in the DNA of its genome and expressed through transcription. Here, mRNA serves as a transient intermediary molecule in the information network, whilst non-coding RNAs perform additional diverse functions. A transcriptome captures a snapshot in time of the total transcripts present in a cell. Transcriptomics technologies provide a broad account of which cellular processes are active and which are dormant. A major challenge in molecular biology is to understand how a single genome gives rise to a variety of cells. Another is how gene expression is regulated.
{{cite journal}}: CS1 maint: multiple names: authors list (link)| | This bioinformatics-related article is a stub. You can help Wikipedia by expanding it. |