A document type definition (DTD) is a specification file that contains set of markup declarations that define a document type for an SGML-family markup language. The DTD specification file can be used to validate documents.
Natural language processing (NLP) is an interdisciplinary subfield of computer science and artificial intelligence. It is primarily concerned with providing computers with the ability to process data encoded in natural language and is thus closely related to information retrieval, knowledge representation and computational linguistics, a subfield of linguistics. Typically data is collected in text corpora, using either rule-based, statistical or neural-based approaches in machine learning and deep learning.

The Standard Generalized Markup Language is a standard for defining generalized markup languages for documents. ISO 8879 Annex A.1 states that generalized markup is "based on two postulates":

Extensible Markup Language (XML) is a markup language and file format for storing, transmitting, and reconstructing arbitrary data. It defines a set of rules for encoding documents in a format that is both human-readable and machine-readable. The World Wide Web Consortium's XML 1.0 Specification of 1998 and several other related specifications—all of them free open standards—define XML.

Optical character recognition or optical character reader (OCR) is the electronic or mechanical conversion of images of typed, handwritten or printed text into machine-encoded text, whether from a scanned document, a photo of a document, a scene photo or from subtitle text superimposed on an image.
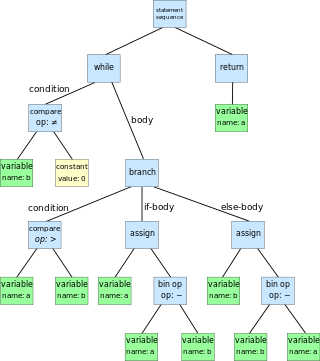
An abstract syntax tree (AST) is a data structure used in computer science to represent the structure of a program or code snippet. It is a tree representation of the abstract syntactic structure of text written in a formal language. Each node of the tree denotes a construct occurring in the text. It is sometimes called just a syntax tree.

Wiktionary is a multilingual, web-based project to create a free content dictionary of terms in all natural languages and in a number of artificial languages. These entries may contain definitions, images for illustration, pronunciations, etymologies, inflections, usage examples, quotations, related terms, and translations of terms into other languages, among other features. It is collaboratively edited via a wiki. Its name is a portmanteau of the words wiki and dictionary. It is available in 193 languages and in Simple English. Like its sister project Wikipedia, Wiktionary is run by the Wikimedia Foundation, and is written collaboratively by volunteers, dubbed "Wiktionarians". Its wiki software, MediaWiki, allows almost anyone with access to the website to create and edit entries.
Text mining, text data mining (TDM) or text analytics is the process of deriving high-quality information from text. It involves "the discovery by computer of new, previously unknown information, by automatically extracting information from different written resources." Written resources may include websites, books, emails, reviews, and articles. High-quality information is typically obtained by devising patterns and trends by means such as statistical pattern learning. According to Hotho et al. (2005) we can distinguish between three different perspectives of text mining: information extraction, data mining, and a knowledge discovery in databases (KDD) process. Text mining usually involves the process of structuring the input text, deriving patterns within the structured data, and finally evaluation and interpretation of the output. 'High quality' in text mining usually refers to some combination of relevance, novelty, and interest. Typical text mining tasks include text categorization, text clustering, concept/entity extraction, production of granular taxonomies, sentiment analysis, document summarization, and entity relation modeling.
YAML is a human-readable data serialization language. It is commonly used for configuration files and in applications where data are being stored or transmitted. YAML targets many of the same communications applications as Extensible Markup Language (XML) but has a minimal syntax that intentionally differs from Standard Generalized Markup Language (SGML). It uses Python-style indentation to indicate nesting and does not require quotes around most string values.
Transport Neutral Encapsulation Format or TNEF is a proprietary email attachment format used by Microsoft Outlook and Microsoft Exchange Server. An attached file with TNEF encoding is most often named winmail.dat or win.dat, and has a MIME type of Application/MS-TNEF. The official (IANA) media type, however, is application/vnd.ms-tnef.

A network processor is an integrated circuit which has a feature set specifically targeted at the networking application domain.
Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites. Web scraping software may directly access the World Wide Web using the Hypertext Transfer Protocol or a web browser. While web scraping can be done manually by a software user, the term typically refers to automated processes implemented using a bot or web crawler. It is a form of copying in which specific data is gathered and copied from the web, typically into a central local database or spreadsheet, for later retrieval or analysis.
An IFilter is a plugin that allows Microsoft's search engines to index various file formats so that they become searchable. Without an appropriate IFilter, contents of a file cannot be parsed and indexed by the search engine.
PDF/A is an ISO-standardized version of the Portable Document Format (PDF) specialized for use in the archiving and long-term preservation of electronic documents. PDF/A differs from PDF by prohibiting features unsuitable for long-term archiving, such as font linking and encryption. The ISO requirements for PDF/A file viewers include color management guidelines, support for embedded fonts, and a user interface for reading embedded annotations.
Search engine indexing is the collecting, parsing, and storing of data to facilitate fast and accurate information retrieval. Index design incorporates interdisciplinary concepts from linguistics, cognitive psychology, mathematics, informatics, and computer science. An alternate name for the process, in the context of search engines designed to find web pages on the Internet, is web indexing.
Embedded RDF (eRDF) is a syntax for writing HTML in such a way that the information in the HTML document can be extracted into Resource Description Framework (RDF). This can be of great use for searching within data.
Virtual Token Descriptor for eXtensible Markup Language (VTD-XML) refers to a collection of cross-platform XML processing technologies centered on a non-extractive XML, "document-centric" parsing technique called Virtual Token Descriptor (VTD). Depending on the perspective, VTD-XML can be viewed as one of the following:
Knowledge extraction is the creation of knowledge from structured and unstructured sources. The resulting knowledge needs to be in a machine-readable and machine-interpretable format and must represent knowledge in a manner that facilitates inferencing. Although it is methodically similar to information extraction (NLP) and ETL, the main criterion is that the extraction result goes beyond the creation of structured information or the transformation into a relational schema. It requires either the reuse of existing formal knowledge or the generation of a schema based on the source data.

An infobox is a digital or physical table used to collect and present a subset of information about its subject, such as a document. It is a structured document containing a set of attribute–value pairs, and in Wikipedia represents a summary of information about the subject of an article. In this way, they are comparable to data tables in some aspects. When presented within the larger document it summarizes, an infobox is often presented in a sidebar format.
Data scraping is a technique where a computer program extracts data from human-readable output coming from another program.