
In computer science, heapsort is a comparison-based sorting algorithm. Heapsort can be thought of as an improved selection sort: like that algorithm, it divides its input into a sorted and an unsorted region, and it iteratively shrinks the unsorted region by extracting the largest element and moving that to the sorted region. The improvement consists of the use of a heap data structure rather than a linear-time search to find the maximum.

In computer science, a heap is a specialized tree-based data structure which is essentially an almost complete tree that satisfies the heap property: in a max heap, for any given node C, if P is a parent node of C, then the key of P is greater than or equal to the key of C. In a min heap, the key of P is less than or equal to the key of C. The node at the "top" of the heap is called the root node.

Insertion sort is a simple sorting algorithm that builds the final sorted array one item at a time. It is much less efficient on large lists than more advanced algorithms such as quicksort, heapsort, or merge sort. However, insertion sort provides several advantages:
Merge algorithms are a family of algorithms that take multiple sorted lists as input and produce a single list as output, containing all the elements of the inputs lists in sorted order. These algorithms are used as subroutines in various sorting algorithms, most famously merge sort.
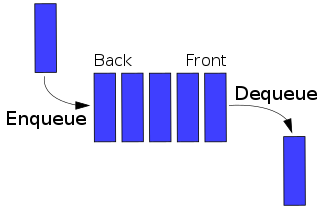
In computer science, a queue is a collection in which the entities in the collection are kept in order and the principal operations on the collection are the addition of entities to the rear terminal position, known as enqueue, and removal of entities from the front terminal position, known as dequeue. This makes the queue a First-In-First-Out (FIFO) data structure. In a FIFO data structure, the first element added to the queue will be the first one to be removed. This is equivalent to the requirement that once a new element is added, all elements that were added before have to be removed before the new element can be removed. Often a peek or front operation is also entered, returning the value of the front element without dequeuing it. A queue is an example of a linear data structure, or more abstractly a sequential collection.

Dijkstra's algorithm is an algorithm for finding the shortest paths between nodes in a graph, which may represent, for example, road networks. It was conceived by computer scientist Edsger W. Dijkstra in 1956 and published three years later.
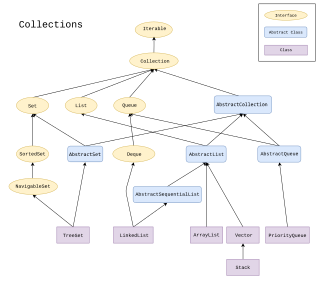
The Java collections framework is a set of classes and interfaces that implement commonly reusable collection data structures.
The d-ary heap or d-heap is a priority queue data structure, a generalization of the binary heap in which the nodes have d children instead of 2. Thus, a binary heap is a 2-heap, and a ternary heap is a 3-heap. According to Tarjan and Jensen et al., d-ary heaps were invented by Donald B. Johnson in 1975.
In computer science, a collection or container is a grouping of some variable number of data items that have some shared significance to the problem being solved and need to be operated upon together in some controlled fashion. Generally, the data items will be of the same type or, in languages supporting inheritance, derived from some common ancestor type. A collection is a concept applicable to abstract data types, and does not prescribe a specific implementation as a concrete data structure, though often there is a conventional choice.

In computer science, a Cartesian tree is a binary tree derived from a sequence of numbers; it can be uniquely defined from the properties that it is heap-ordered and that a symmetric (in-order) traversal of the tree returns the original sequence. Introduced by Vuillemin (1980) in the context of geometric range searching data structures, Cartesian trees have also been used in the definition of the treap and randomized binary search tree data structures for binary search problems. The Cartesian tree for a sequence may be constructed in linear time using a stack-based algorithm for finding all nearest smaller values in a sequence.
In computer science, a search data structure is any data structure that allows the efficient retrieval of specific items from a set of items, such as a specific record from a database.
In computer science, a double-ended priority queue (DEPQ) or double-ended heap is a data structure similar to a priority queue or heap, but allows for efficient removal of both the maximum and minimum, according to some ordering on the keys (items) stored in the structure. Every element in a DEPQ has a priority or value. In a DEPQ, it is possible to remove the elements in both ascending as well as descending order.
In computer science, integer sorting is the algorithmic problem of sorting a collection of data values by numeric keys, each of which is an integer. Algorithms designed for integer sorting may also often be applied to sorting problems in which the keys are floating point numbers, rational numbers, or text strings. The ability to perform integer arithmetic on the keys allows integer sorting algorithms to be faster than comparison sorting algorithms in many cases, depending on the details of which operations are allowed in the model of computing and how large the integers to be sorted are.
In computing, sequence containers refer to a group of container class templates in the standard library of the C++ programming language that implement storage of data elements. Being templates, they can be used to store arbitrary elements, such as integers or custom classes. One common property of all sequential containers is that the elements can be accessed sequentially. Like all other standard library components, they reside in namespace std.
In computer science, peek is an operation on certain abstract data types, specifically sequential collections such as stacks and queues, which returns the value of the top ("front") of the collection without removing the element from the collection. It thus returns the same value as operations such as "pop" or "dequeue", but does not modify the data.
A weak heap is a combination of the binary heap and binomial heap data structures for implementing priority queues. It can be stored in an array as an implicit binary tree like the former, and has the efficiency guarantees of the latter.

