Real-time deques via lazy rebuilding and scheduling
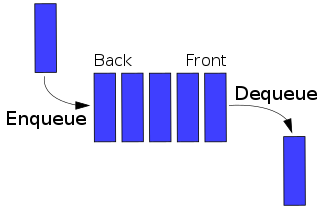
A double-ended queue is represented as a sextuple (len_front, front, tail_front, len_rear, rear, tail_rear) where front is a linked list which contains the front of the queue of length len_front. Similarly, rear is a linked list which represents the reverse of the rear of the queue, of length len_rear. Furthermore, it is assured that |front| ≤ 2|rear|+1 and |rear| ≤ 2|front|+1 - intuitively, it means that both the front and the rear contains between a third minus one and two thirds plus one of the elements. Finally, tail_front and tail_rear are tails of front and of rear, they allow scheduling the moment where some lazy operations are forced. Note that, when a double-ended queue contains n elements in the front list and n elements in the rear list, then the inequality invariant remains satisfied after i insertions and d deletions when (i+d) ≤ n/2. That is, at most n/2 operations can happen between each rebalancing.
Let us first give an implementation of the various operations that affect the front of the deque - cons, head and tail. Those implementations do not necessarily respect the invariant. In a second time we'll explain how to modify a deque which does not satisfy the invariant into one which satisfies it. However, they use the invariant, in that if the front is empty then the rear has at most one element. The operations affecting the rear of the list are defined similarly by symmetry.
empty=(0,NIL,NIL,0,NIL,NIL)funinsert'(x,(len_front,front,tail_front,len_rear,rear,tail_rear))=(len_front+1,CONS(x,front),drop(2,tail_front),len_rear,rear,drop(2,tail_rear))funhead((_,CONS(h,_),_,_,_,_))=hfunhead((_,NIL,_,_,CONS(h,NIL),_))=hfuntail'((len_front,CONS(head_front,front),tail_front,len_rear,rear,tail_rear))=(len_front-1,front,drop(2,tail_front),len_rear,rear,drop(2,tail_rear))funtail'((_,NIL,_,_,CONS(h,NIL),_))=empty
It remains to explain how to define a method balance that rebalance the deque if insert' or tail broke the invariant. The method insert and tail can be defined by first applying insert' and tail' and then applying balance.
funbalance(qas(len_front,front,tail_front,len_rear,rear,tail_rear))=letfloor_half_len=(len_front+len_rear)/2inletceil_half_len=len_front+len_rear-floor_half_leniniflen_front>2*len_rear+1thenletvalfront'=take(ceil_half_len,front)valrear'=rotateDrop(rear,floor_half_len,front)in(ceil_half_len,front',front',floor_half_len,rear',rear')elseiflen_front>2*len_rear+1thenletvalrear'=take(floor_half_len,rear)valfront'=rotateDrop(front,ceil_half_len,rear)in(ceil_half_len,front',front',floor_half_len,rear',rear')elseq
where rotateDrop(front, i, rear)) return the concatenation of front and of drop(i, rear). That isfront' = rotateDrop(front, ceil_half_len, rear) put into front' the content of front and the content of rear that is not already in rear'. Since dropping n elements takes  time, we use laziness to ensure that elements are dropped two by two, with two drops being done during each
time, we use laziness to ensure that elements are dropped two by two, with two drops being done during each tail' and each insert' operation.
funrotateDrop(front,i,rear)=ifi<2thenrotateRev(front,drop(i,rear),NIL)elseletCONS(x,front')=frontinCONS(x,rotateDrop(front',j-2,drop(2,rear)))
where rotateRev(front, middle, rear) is a function that returns the front, followed by the middle reversed, followed by the rear. This function is also defined using laziness to ensure that it can be computed step by step, with one step executed during each insert' and tail' and taking a constant time. This function uses the invariant that |rear|-2|front| is 2 or 3.
funrotateRev(NIL,rear,a)=reverse(rear)++afunrotateRev(CONS(x,front),rear,a)=CONS(x,rotateRev(front,drop(2,rear),reverse(take(2,rear))++a))
where ++ is the function concatenating two lists.