
In computer science, a binary tree is a tree data structure in which each node has at most two children, referred to as the left child and the right child. That is, it is a k-ary tree with k = 2. A recursive definition using set theory is that a binary tree is a tuple (L, S, R), where L and R are binary trees or the empty set and S is a singleton set containing the root.
In computer science, a linked list is a linear collection of data elements whose order is not given by their physical placement in memory. Instead, each element points to the next. It is a data structure consisting of a collection of nodes which together represent a sequence. In its most basic form, each node contains data, and a reference to the next node in the sequence. This structure allows for efficient insertion or removal of elements from any position in the sequence during iteration. More complex variants add additional links, allowing more efficient insertion or removal of nodes at arbitrary positions. A drawback of linked lists is that data access time is linear in respect to the number of nodes in the list. Because nodes are serially linked, accessing any node requires that the prior node be accessed beforehand. Faster access, such as random access, is not feasible. Arrays have better cache locality compared to linked lists.
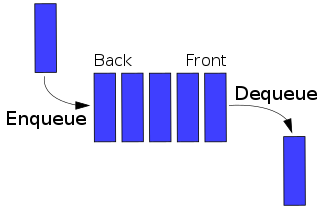
In computer science, a queue is a collection of entities that are maintained in a sequence and can be modified by the addition of entities at one end of the sequence and the removal of entities from the other end of the sequence. By convention, the end of the sequence at which elements are added is called the back, tail, or rear of the queue, and the end at which elements are removed is called the head or front of the queue, analogously to the words used when people line up to wait for goods or services.
In computer science, a red–black tree is a self-balancing binary search tree data structure noted for fast storage and retrieval of ordered information. The nodes in a red-black tree hold an extra "color" bit, often drawn as red and black, which help ensure that the tree is always approximately balanced.

Dijkstra's algorithm is an algorithm for finding the shortest paths between nodes in a weighted graph, which may represent, for example, a road network. It was conceived by computer scientist Edsger W. Dijkstra in 1956 and published three years later.
An XOR linked list is a type of data structure used in computer programming. It takes advantage of the bitwise XOR operation to decrease storage requirements for doubly linked lists by storing the composition of both addresses in one field. While the composed address is not meaningful on its own, during traversal it can be combined with knowledge of the last-visited node address to deduce the address of the following node.
In computer science, tree traversal is a form of graph traversal and refers to the process of visiting each node in a tree data structure, exactly once. Such traversals are classified by the order in which the nodes are visited. The following algorithms are described for a binary tree, but they may be generalized to other trees as well.
In computing, a persistent data structure or not ephemeral data structure is a data structure that always preserves the previous version of itself when it is modified. Such data structures are effectively immutable, as their operations do not (visibly) update the structure in-place, but instead always yield a new updated structure. The term was introduced in Driscoll, Sarnak, Sleator, and Tarjan's 1986 article.
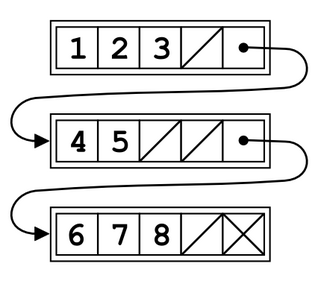
In computer programming, an unrolled linked list is a variation on the linked list which stores multiple elements in each node. It can dramatically increase cache performance, while decreasing the memory overhead associated with storing list metadata such as references. It is related to the B-tree.
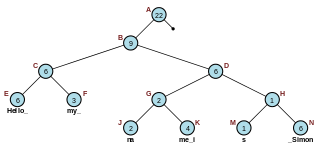
In computer programming, a rope, or cord, is a data structure composed of smaller strings that is used to efficiently store and manipulate longer strings or entire texts. For example, a text editing program may use a rope to represent the text being edited, so that operations such as insertion, deletion, and random access can be done efficiently.

In computer science, a radix tree is a data structure that represents a space-optimized trie in which each node that is the only child is merged with its parent. The result is that the number of children of every internal node is at most the radix r of the radix tree, where r = 2x for some integer x ≥ 1. Unlike regular trees, edges can be labeled with sequences of elements as well as single elements. This makes radix trees much more efficient for small sets and for sets of strings that share long prefixes.

Coalesced hashing, also called coalesced chaining, is a strategy of collision resolution in a hash table that forms a hybrid of separate chaining and open addressing.
In computer science, a ternary search tree is a type of trie where nodes are arranged in a manner similar to a binary search tree, but with up to three children rather than the binary tree's limit of two. Like other prefix trees, a ternary search tree can be used as an associative map structure with the ability for incremental string search. However, ternary search trees are more space efficient compared to standard prefix trees, at the cost of speed. Common applications for ternary search trees include spell-checking and auto-completion.
In computer programming, a sentinel node is a specifically designated node used with linked lists and trees as a traversal path terminator. This type of node does not hold or reference any data managed by the data structure.

In computer science, recursion is a method of solving a computational problem where the solution depends on solutions to smaller instances of the same problem. Recursion solves such recursive problems by using functions that call themselves from within their own code. The approach can be applied to many types of problems, and recursion is one of the central ideas of computer science.
The power of recursion evidently lies in the possibility of defining an infinite set of objects by a finite statement. In the same manner, an infinite number of computations can be described by a finite recursive program, even if this program contains no explicit repetitions.
In computer science, fringe search is a graph search algorithm that finds the least-cost path from a given initial node to one goal node.
In computer science, a linked data structure is a data structure which consists of a set of data records (nodes) linked together and organized by references. The link between data can also be called a connector.

In computer science, a queap is a priority queue data structure. The data structure allows insertions and deletions of arbitrary elements, as well as retrieval of the highest-priority element. Each deletion takes amortized time logarithmic in the number of items that have been in the structure for a longer time than the removed item. Insertions take constant amortized time.
Skip graphs are a kind of distributed data structure based on skip lists. They were invented in 2003 by James Aspnes and Gauri Shah. A nearly identical data structure called SkipNet was independently invented by Nicholas Harvey, Michael Jones, Stefan Saroiu, Marvin Theimer and Alec Wolman, also in 2003.
A non-blocking linked list is an example of non-blocking data structures designed to implement a linked list in shared memory using synchronization primitives:
