Related Research Articles
In computer science, an array is a data structure consisting of a collection of elements, of same memory size, each identified by at least one array index or key. An array is stored such that the position of each element can be computed from its index tuple by a mathematical formula. The simplest type of data structure is a linear array, also called one-dimensional array.

In computer science, binary search, also known as half-interval search, logarithmic search, or binary chop, is a search algorithm that finds the position of a target value within a sorted array. Binary search compares the target value to the middle element of the array. If they are not equal, the half in which the target cannot lie is eliminated and the search continues on the remaining half, again taking the middle element to compare to the target value, and repeating this until the target value is found. If the search ends with the remaining half being empty, the target is not in the array.

In computer science, a data structure is a data organization and storage format that is usually chosen for efficient access to data. More precisely, a data structure is a collection of data values, the relationships among them, and the functions or operations that can be applied to the data, i.e., it is an algebraic structure about data.
In computing, a hash table is a data structure that implements an associative array, also called a dictionary or simply map; an associative array is an abstract data type that maps keys to values. A hash table uses a hash function to compute an index, also called a hash code, into an array of buckets or slots, from which the desired value can be found. During lookup, the key is hashed and the resulting hash indicates where the corresponding value is stored. A map implemented by a hash table is called a hash map.
In computer science, a linked list is a linear collection of data elements whose order is not given by their physical placement in memory. Instead, each element points to the next. It is a data structure consisting of a collection of nodes which together represent a sequence. In its most basic form, each node contains data, and a reference to the next node in the sequence. This structure allows for efficient insertion or removal of elements from any position in the sequence during iteration. More complex variants add additional links, allowing more efficient insertion or removal of nodes at arbitrary positions. A drawback of linked lists is that data access time is linear in respect to the number of nodes in the list. Because nodes are serially linked, accessing any node requires that the prior node be accessed beforehand. Faster access, such as random access, is not feasible. Arrays have better cache locality compared to linked lists.

In computer science, a trie, also called digital tree or prefix tree, is a type of k-ary search tree, a tree data structure used for locating specific keys from within a set. These keys are most often strings, with links between nodes defined not by the entire key, but by individual characters. In order to access a key, the trie is traversed depth-first, following the links between nodes, which represent each character in the key.
In computer science, an associative array, map, symbol table, or dictionary is an abstract data type that stores a collection of pairs, such that each possible key appears at most once in the collection. In mathematical terms, an associative array is a function with finite domain. It supports 'lookup', 'remove', and 'insert' operations.
In computer science, a set is an abstract data type that can store unique values, without any particular order. It is a computer implementation of the mathematical concept of a finite set. Unlike most other collection types, rather than retrieving a specific element from a set, one typically tests a value for membership in a set.
In computer programming, cons is a fundamental function in most dialects of the Lisp programming language. consconstructs memory objects which hold two values or pointers to two values. These objects are referred to as (cons) cells, conses, non-atomic s-expressions ("NATSes"), or (cons) pairs. In Lisp jargon, the expression "to cons x onto y" means to construct a new object with (cons xy). The resulting pair has a left half, referred to as the car, and a right half, referred to as the cdr.
In computer science, a list or sequence is collection of items that are finite in number and in a particular order. An instance of a list is a computer representation of the mathematical concept of a tuple or finite sequence.
A list comprehension is a syntactic construct available in some programming languages for creating a list based on existing lists. It follows the form of the mathematical set-builder notation as distinct from the use of map and filter functions.

In computer science, a self-balancing binary search tree (BST) is any node-based binary search tree that automatically keeps its height small in the face of arbitrary item insertions and deletions. These operations when designed for a self-balancing binary search tree, contain precautionary measures against boundlessly increasing tree height, so that these abstract data structures receive the attribute "self-balancing".
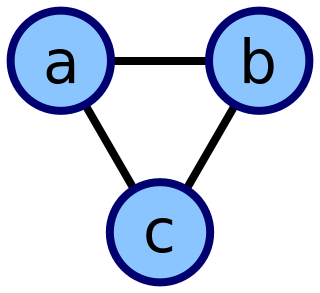
In graph theory and computer science, an adjacency list is a collection of unordered lists used to represent a finite graph. Each unordered list within an adjacency list describes the set of neighbors of a particular vertex in the graph. This is one of several commonly used representations of graphs for use in computer programs.
A Bloom filter is a space-efficient probabilistic data structure, conceived by Burton Howard Bloom in 1970, that is used to test whether an element is a member of a set. False positive matches are possible, but false negatives are not – in other words, a query returns either "possibly in set" or "definitely not in set". Elements can be added to the set, but not removed ; the more items added, the larger the probability of false positives.
In computing, a persistent data structure or not ephemeral data structure is a data structure that always preserves the previous version of itself when it is modified. Such data structures are effectively immutable, as their operations do not (visibly) update the structure in-place, but instead always yield a new updated structure. The term was introduced in Driscoll, Sarnak, Sleator, and Tarjan's 1986 article.

In computer science, a radix tree is a data structure that represents a space-optimized trie in which each node that is the only child is merged with its parent. The result is that the number of children of every internal node is at most the radix r of the radix tree, where r = 2x for some integer x ≥ 1. Unlike regular trees, edges can be labeled with sequences of elements as well as single elements. This makes radix trees much more efficient for small sets and for sets of strings that share long prefixes.
In computer science, a multimap is a generalization of a map or associative array abstract data type in which more than one value may be associated with and returned for a given key. Both map and multimap are particular cases of containers. Often the multimap is implemented as a map with lists or sets as the map values.
This comparison of programming languages (associative arrays) compares the features of associative array data structures or array-lookup processing for over 40 computer programming languages.
A concurrent hash-trie or Ctrie is a concurrent thread-safe lock-free implementation of a hash array mapped trie. It is used to implement the concurrent map abstraction. It has particularly scalable concurrent insert and remove operations and is memory-efficient. It is the first known concurrent data-structure that supports O(1), atomic, lock-free snapshots.
References
- 1 2 Marriott, Kim; Stuckey, Peter J. (1998). Programming with Constraints: An Introduction. MIT Press. pp. 193–195. ISBN 9780262133418.
- ↑ Frické, Martin (2012). "2.8.3 Association Lists". Logic and the Organization of Information. Springer. pp. 44–45. ISBN 9781461430872.
- ↑ Knuth, Donald. "6.1 Sequential Searching". The Art of Computer Programming, Vol. 3: Sorting and Searching (2nd ed.). Addison Wesley. pp. 396–405. ISBN 0-201-89685-0.
- ↑ Janes, Calvin (2011). "Using Association Lists for Associative Arrays". Developer's Guide to Collections in Microsoft .NET. Pearson Education. p. 191. ISBN 9780735665279.
- 1 2 McCarthy, John; Abrahams, Paul W.; Edwards, Daniel J.; Hart, Timothy P.; Levin, Michael I. (1985). LISP 1.5 Programmer's Manual . MIT Press. ISBN 0-262-13011-4. See in particular p. 12 for functions that search an association list and use it to substitute symbols in another expression, and p. 103 for the application of association lists in maintaining variable bindings.
- ↑ van de Snepscheut, Jan L. A. (1993). What Computing Is All About. Monographs in Computer Science. Springer. p. 201. ISBN 9781461227106.
- ↑ Scott, Michael Lee (2000). "3.3.4 Association Lists and Central Reference Tables". Programming Language Pragmatics. Morgan Kaufmann. p. 137. ISBN 9781558604421.
- ↑ Pearce, Jon (2012). Programming and Meta-Programming in Scheme. Undergraduate Texts in Computer Science. Springer. p. 214. ISBN 9781461216827.
- ↑ Minsky, Yaron; Madhavapeddy, Anil; Hickey, Jason (2013). Real World OCaml: Functional Programming for the Masses. O'Reilly Media. p. 253. ISBN 9781449324766.
- ↑ O'Sullivan, Bryan; Goerzen, John; Stewart, Donald Bruce (2008). Real World Haskell: Code You Can Believe In. O'Reilly Media. p. 299. ISBN 9780596554309.
- ↑ "10.1. The Property List". Cs.cmu.edu. Retrieved 29 September 2017.