A splay tree is a binary search tree with the additional property that recently accessed elements are quick to access again. Like self-balancing binary search trees, a splay tree performs basic operations such as insertion, look-up and removal in O(log n) amortized time. For random access patterns drawn from a non-uniform random distribution, their amortized time can be faster than logarithmic, proportional to the entropy of the access pattern. For many patterns of non-random operations, also, splay trees can take better than logarithmic time, without requiring advance knowledge of the pattern. According to the unproven dynamic optimality conjecture, their performance on all access patterns is within a constant factor of the best possible performance that could be achieved by any other self-adjusting binary search tree, even one selected to fit that pattern. The splay tree was invented by Daniel Sleator and Robert Tarjan in 1985.[1]
All normal operations on a binary search tree are combined with one basic operation, called splaying. Splaying the tree for a certain element rearranges the tree so that the element is placed at the root of the tree. One way to do this with the basic search operation is to first perform a standard binary tree search for the element in question, and then use tree rotations in a specific fashion to bring the element to the top. Alternatively, a top-down algorithm can combine the search and the tree reorganization into a single phase.
Advantages
Good performance for a splay tree depends on the fact that it is self-optimizing, in that frequently accessed nodes will move nearer to the root where they can be accessed more quickly. The worst-case height—though unlikely—is O(n), with the average being O(log n). Having frequently-used nodes near the root is an advantage for many practical applications (also see locality of reference), and is particularly useful for implementing caches and garbage collection algorithms.
Advantages include:
Comparable performance: Average-case performance is as efficient as other trees.[3]
Small memory footprint: Splay trees do not need to store any bookkeeping data.
Disadvantages
The most significant disadvantage of splay trees is that the height of a splay tree can be linear.[2]:1 For example, this will be the case after accessing all n elements in non-decreasing order. Since the height of a tree corresponds to the worst-case access time, this means that the actual cost of a single operation can be high. However the amortized access cost of this worst case is logarithmic, O(log n). Also, the expected access cost can be reduced to O(log n) by using a randomized variant.[4]
The representation of splay trees can change even when they are accessed in a 'read-only' manner (i.e. by find operations). This complicates the use of such splay trees in a multi-threaded environment. Specifically, extra management is needed if multiple threads are allowed to perform find operations concurrently. This also makes them unsuitable for general use in purely functional programming, although even there they can be used in limited ways to implement priority queues.
Finally, when the access pattern is random, the additional splaying overhead adds a significant constant factor to the cost compared to less-dynamic alternatives.
Operations
Splaying
When a node x is accessed, a splay operation is performed on x to move it to the root. A splay operation is a sequence of splay steps, each of which moves x closer to the root. By performing a splay operation on the node of interest after every access, the recently accessed nodes are kept near the root and the tree remains roughly balanced, so it provides the desired amortized time bounds.
Each particular step depends on three factors:
Whether x is the left or right child of its parent node, p,
whether p is the root or not, and if not
whether p is the left or right child of its parent, g (the grandparent of x).
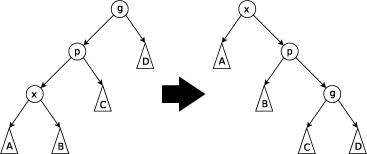
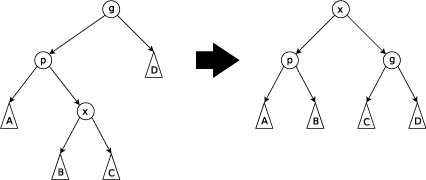
There are three types of splay steps, each of which has two symmetric variants: left- and right-handed. For the sake of brevity, only one of these two is shown for each type. (In the following diagrams, circles indicate nodes of interest and triangles indicate sub-trees of arbitrary size.) The three types of splay steps are:
Zig step: this step is done when p is the root. The tree is rotated on the edge between x and p. Zig steps exist to deal with the parity issue, will be done only as the last step in a splay operation, and only when x has odd depth at the beginning of the operation.
Zig-zig step: this step is done when p is not the root and x and p are either both right children or are both left children. The picture below shows the case where x and p are both left children. The tree is rotated on the edge joining p with its parent g, then rotated on the edge joining x with p. Zig-zig steps are the only thing that differentiate splay trees from the rotate to root method introduced by Allen and Munro[5] prior to the introduction of splay trees.
Zig-zag step: this step is done when p is not the root and x is a right child and p is a left child or vice versa (x is left, p is right). The tree is rotated on the edge between p and x, and then rotated on the resulting edge between x and g.
Join
Given two trees S and T such that all elements of S are smaller than the elements of T, the following steps can be used to join them to a single tree:
Splay the largest item in S. Now this item is in the root of S and has a null right child.
Set the right child of the new root to T.
Split
Given a tree and an element x, return two new trees: one containing all elements less than or equal to x and the other containing all elements greater than x. This can be done in the following way:
Splay x. Now it is in the root so the tree to its left contains all elements smaller than x and the tree to its right contains all element larger than x.
Split the right subtree from the rest of the tree.
As a result, the newly inserted node x becomes the root of the tree.
Alternatively:
Use the split operation to split the tree at the value of x to two sub-trees: S and T.
Create a new tree in which x is the root, S is its left sub-tree and T its right sub-tree.
Deletion
To delete a node x, use the same method as with a binary search tree:
If x has two children:
Swap its value with that of either the rightmost node of its left sub tree (its in-order predecessor) or the leftmost node of its right subtree (its in-order successor).
Remove that node instead.
In this way, deletion is reduced to the problem of removing a node with 0 or 1 children. Unlike a binary search tree, in a splay tree after deletion, we splay the parent of the removed node to the top of the tree.
Alternatively:
The node to be deleted is first splayed, i.e. brought to the root of the tree and then deleted. leaves the tree with two sub trees.
The two sub-trees are then joined using a "join" operation.
Implementation and variants
Splaying, as mentioned above, is performed during a second, bottom-up pass over the access path of a node. It is possible to record the access path during the first pass for use during the second, but that requires extra space during the access operation. Another alternative is to keep a parent pointer in every node, which avoids the need for extra space during access operations but may reduce overall time efficiency because of the need to update those pointers.[1]
Another method which can be used is based on the argument that the tree can be restructured during the way down the access path instead of making a second pass. This top-down splaying routine uses three sets of nodes – left tree, right tree and middle tree. The first two contain all items of original tree known to be less than or greater than current item respectively. The middle tree consists of the sub-tree rooted at the current node. These three sets are updated down the access path while keeping the splay operations in check. Another method, semisplaying, modifies the zig-zig case to reduce the amount of restructuring done in all operations.[1][6]
Below there is an implementation of splay trees in C++, which uses pointers to represent each node on the tree. This implementation is based on bottom-up splaying version and uses the second method of deletion on a splay tree. Also, unlike the above definition, this C++ version does not splay the tree on finds – it only splays on insertions and deletions, and the find operation, therefore, has linear time complexity.
#include<functional>#ifndef SPLAY_TREE#define SPLAY_TREEtemplate<typenameT,typenameComp=std::less<T>>classsplay_tree{private:Compcomp;unsignedlongp_size;structnode{node*left,*right;node*parent;Tkey;node(constT&init=T()):left(nullptr),right(nullptr),parent(nullptr),key(init){}~node(){}}*root;voidleft_rotate(node*x){node*y=x->right;if(y){x->right=y->left;if(y->left)y->left->parent=x;y->parent=x->parent;}if(!x->parent)root=y;elseif(x==x->parent->left)x->parent->left=y;elsex->parent->right=y;if(y)y->left=x;x->parent=y;}voidright_rotate(node*x){node*y=x->left;if(y){x->left=y->right;if(y->right)y->right->parent=x;y->parent=x->parent;}if(!x->parent)root=y;elseif(x==x->parent->left)x->parent->left=y;elsex->parent->right=y;if(y)y->right=x;x->parent=y;}voidsplay(node*x){while(x->parent){if(!x->parent->parent){if(x->parent->left==x)right_rotate(x->parent);elseleft_rotate(x->parent);}elseif(x->parent->left==x&&x->parent->parent->left==x->parent){right_rotate(x->parent->parent);right_rotate(x->parent);}elseif(x->parent->right==x&&x->parent->parent->right==x->parent){left_rotate(x->parent->parent);left_rotate(x->parent);}elseif(x->parent->left==x&&x->parent->parent->right==x->parent){right_rotate(x->parent);left_rotate(x->parent);}else{left_rotate(x->parent);right_rotate(x->parent);}}}voidreplace(node*u,node*v){if(!u->parent)root=v;elseif(u==u->parent->left)u->parent->left=v;elseu->parent->right=v;if(v)v->parent=u->parent;}node*subtree_minimum(node*u){while(u->left)u=u->left;returnu;}node*subtree_maximum(node*u){while(u->right)u=u->right;returnu;}public:splay_tree():root(nullptr),p_size(0){}voidinsert(constT&key){node*z=root;node*p=nullptr;while(z){p=z;if(comp(z->key,key))z=z->right;elsez=z->left;}z=newnode(key);z->parent=p;if(!p)root=z;elseif(comp(p->key,z->key))p->right=z;elsep->left=z;splay(z);p_size++;}node*find(constT&key){node*z=root;while(z){if(comp(z->key,key))z=z->right;elseif(comp(key,z->key))z=z->left;elsereturnz;}returnnullptr;}voiderase(constT&key){node*z=find(key);if(!z)return;splay(z);if(!z->left)replace(z,z->right);elseif(!z->right)replace(z,z->left);else{node*y=subtree_minimum(z->right);if(y->parent!=z){replace(y,y->right);y->right=z->right;y->right->parent=y;}replace(z,y);y->left=z->left;y->left->parent=y;}deletez;p_size--;}/* //the alternative implementation void erase(const T &key) { node *z = find(key); if (!z) return; splay(z); node *s = z->left; node *t = z->right; delete z; node *sMax = NULL; if (s) { s->parent = NULL; sMax = subtree_maximum(s); splay(sMax); root = sMax; } if (t) { if (s) sMax->right = t; else root = t; t->parent = sMax; } p_size--; }*/constT&minimum(){returnsubtree_minimum(root)->key;}constT&maximum(){returnsubtree_maximum(root)->key;}boolempty()const{returnroot==nullptr;}unsignedlongsize()const{returnp_size;}};#endif // SPLAY_TREE
size(r) = the number of nodes in the sub-tree rooted at node r (including r).
rank(r) = log2(size(r)).
Φ = the sum of the ranks of all the nodes in the tree.
Φ will tend to be high for poorly balanced trees and low for well-balanced trees.
To apply the potential method, we first calculate ΔΦ: the change in the potential caused by a splay operation. We check each case separately. Denote by rank' the rank function after the operation. x, p and g are the nodes affected by the rotation operation (see figures above).
The amortized cost of any operation is ΔΦ plus the actual cost. The actual cost of any zig-zig or zig-zag operation is 2 since there are two rotations to make. Hence:
amortized-cost
= cost + ΔΦ
≤ 3(rank'(x)−rank(x))
When summed over the entire splay operation, this telescopes to 1 + 3(rank(root)−rank(x)) which is O(log n), since we use The Zig operation at most once and the amortized cost of zig is at most 1+3(rank'(x)−rank(x)).
So now we know that the total amortized time for a sequence of m operations is:
To go from the amortized time to the actual time, we must add the decrease in potential from the initial state before any operation is done (Φi) to the final state after all operations are completed (Φf).
where the big O notation can be justified by the fact that for every node x, the minimum rank is 0 and the maximum rank is log(n).
Now we can finally bound the actual time:
Weighted analysis
The above analysis can be generalized in the following way.
Assign to each node r a weight w(r).
Define size(r) = the sum of weights of nodes in the sub-tree rooted at node r (including r).
Define rank(r) and Φ exactly as above.
The same analysis applies and the amortized cost of a splaying operation is again:
where W is the sum of all weights.
The decrease from the initial to the final potential is bounded by:
since the maximum size of any single node is W and the minimum is w(x).
Hence the actual time is bounded by:
Performance theorems
There are several theorems and conjectures regarding the worst-case runtime for performing a sequence S of m accesses in a splay tree containing n elements.
Balance Theorem—The cost of performing the sequence S is .
Proof
Take a constant weight, e.g. for every node x. Then .
This theorem implies that splay trees perform as well as static balanced binary search trees on sequences of at least n accesses.[1]
Static Optimality Theorem—Let be the number of times element x is accessed in S. If every element is accessed at least once, then the cost of performing S is
Proof
Let . Then .
This theorem implies that splay trees perform as well as an optimum static binary search tree on sequences of at least n accesses.[7] They spend less time on the more frequent items.[1] Another way of stating the same result is that, on input sequences where the items are drawn independently at random from a non-uniform probability distribution on n items, the amortized expected (average case) cost of each access is proportional to the entropy of the distribution.[8]
Static Finger Theorem—Assume that the items are numbered from 1 through n in ascending order. Let f be any fixed element (the 'finger'). Then the cost of performing S is .
Proof
Let . Then . The net potential drop is O (n log n) since the weight of any item is at least .[1]
Dynamic Finger Theorem—Assume that the 'finger' for each step accessing an element y is the element accessed in the previous step, x. The cost of performing S is .[9][10]
Working Set Theorem—At any time during the sequence, let be the number of distinct elements accessed before the previous time element x was accessed. The cost of performing S is
Proof
Let . Note that here the weights change during the sequence. However, the sequence of weights is still a permutation of . So as before . The net potential drop is O (n log n).
Scanning Theorem—Also known as the Sequential Access Theorem or the Queue theorem. Accessing the n elements of a splay tree in symmetric order takes O(n) time, regardless of the initial structure of the splay tree.[11] The tightest upper bound proven so far is .[12]
In addition to the proven performance guarantees for splay trees there is an unproven conjecture of great interest from the original Sleator and Tarjan paper. This conjecture is known as the dynamic optimality conjecture and it basically claims that splay trees perform as well as any other binary search tree algorithm up to a constant factor.
Dynamic Optimality Conjecture:[1] Let be any binary search tree algorithm that accesses an element by traversing the path from the root to at a cost of , and that between accesses can make any rotations in the tree at a cost of 1 per rotation. Let be the cost for to perform the sequence of accesses. Then the cost for a splay tree to perform the same accesses is .
There are several corollaries of the dynamic optimality conjecture that remain unproven:
Traversal Conjecture:[1] Let and be two splay trees containing the same elements. Let be the sequence obtained by visiting the elements in in preorder (i.e., depth first search order). The total cost of performing the sequence of accesses on is .
Deque Conjecture:[11][13][14] Let be a sequence of double-ended queue operations (push, pop, inject, eject). Then the cost of performing on a splay tree is .
Split Conjecture:[6] Let be any permutation of the elements of the splay tree. Then the cost of deleting the elements in the order , splitting each tree into two separate trees at each deleted item, is .
Variants
In order to reduce the number of restructuring operations, it is possible to replace the splaying with semi-splaying, in which an element is splayed only halfway towards the root.[1][2]
Another way to reduce restructuring is to do full splaying, but only in some of the access operations – only when the access path is longer than a threshold, or only in the first m access operations.[1]
The CBTree augments the splay tree with access counts at each node and uses them to restructure infrequently. A variant of the CBTree called the LazyCBTree does at most one rotation on each lookup. This is used along with an optimistic hand-over-hand validation scheme to make a concurrent self-adjusting tree.[15]
Using pointer-compression techniques,[16] it is possible to construct a succinct splay tree.
Brinkmann, Gunnar; Degraer, Jan; De Loof, Karel (January 2009). "Rehabilitation of an unloved child: semi-splaying"(PDF). Software: Practice and Experience. 39 (1): 33–45. CiteSeerX10.1.1.84.790. doi:10.1002/spe.v39:1. hdl:11382/102133. The results show that semi-splaying, which was introduced in the same paper as splaying, performs better than splaying under almost all possible conditions. This makes semi-splaying a good alternative for all applications where normally splaying would be applied. The reason why splaying became so prominent while semi-splaying is relatively unknown and much less studied is hard to understand.
Goodrich, Michael; Tamassia, Roberto; Goldwasser, Michael (2014). Data Structures and Algorithms in Java (6ed.). Wiley. p.506. ISBN978-1-118-77133-4.
Grinberg, Dennis; Rajagopalan, Sivaramakrishnan; Venkatesan, Ramarathnam; Wei, Victor K. (1995). "Splay trees for data compression". In Clarkson, Kenneth L. (ed.). Proceedings of the Sixth Annual ACM-SIAM Symposium on Discrete Algorithms, 22–24 January 1995. San Francisco, California, USA. ACM/SIAM. pp.522–530. Average depth of access in a splay tree is proportional to the entropy.
Knuth, Donald (1997). The Art of Computer Programming. Vol.3: Sorting and Searching (3rded.). Addison-Wesley. p.478. ISBN0-201-89685-0. The time needed to access data in a splay tree is known to be at most a small constant multiple of the access time of a statically optimum tree, when amortized over any series of operations.
Lucas, Joan M. (1991). "On the Competitiveness of Splay Trees: Relations to the Union-Find Problem". On-line Algorithms: Proceedings of a DIMACS Workshop, February 11–13, 1991. Series in Discrete Mathematics and Theoretical Computer Science. Vol.7. Center for Discrete Mathematics and Theoretical Computer Science. pp.95–124. ISBN0-8218-7111-0.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.