
In computer science, a binary search tree (BST), also called an ordered or sorted binary tree, is a rooted binary tree data structure with the key of each internal node being greater than all the keys in the respective node's left subtree and less than the ones in its right subtree. The time complexity of operations on the binary search tree is linear with respect to the height of the tree.
In computer science, a red–black tree is a self-balancing binary search tree data structure noted for fast storage and retrieval of ordered information. The nodes in a red-black tree hold an extra "color" bit, often drawn as red and black, which help ensure that the tree is always approximately balanced.

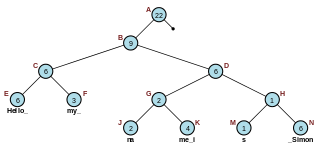
In computer science, a trie, also called digital tree or prefix tree, is a type of search tree: specifically, a k-ary tree data structure used for locating specific keys from within a set. These keys are most often strings, with links between nodes defined not by the entire key, but by individual characters. In order to access a key, the trie is traversed depth-first, following the links between nodes, which represent each character in the key.

In computer science, the Aho–Corasick algorithm is a string-searching algorithm invented by Alfred V. Aho and Margaret J. Corasick in 1975. It is a kind of dictionary-matching algorithm that locates elements of a finite set of strings within an input text. It matches all strings simultaneously. The complexity of the algorithm is linear in the length of the strings plus the length of the searched text plus the number of output matches. Note that because all matches are found, multiple matches will be returned for one string location if multiple substrings matched.
In computer science, tree traversal is a form of graph traversal and refers to the process of visiting each node in a tree data structure, exactly once. Such traversals are classified by the order in which the nodes are visited. The following algorithms are described for a binary tree, but they may be generalized to other trees as well.

In computer science, a suffix tree is a compressed trie containing all the suffixes of the given text as their keys and positions in the text as their values. Suffix trees allow particularly fast implementations of many important string operations.
In computer science, a search tree is a tree data structure used for locating specific keys from within a set. In order for a tree to function as a search tree, the key for each node must be greater than any keys in subtrees on the left, and less than any keys in subtrees on the right.
In computer programming, a rope, or cord, is a data structure composed of smaller strings that is used to efficiently store and manipulate longer strings or entire texts. For example, a text editing program may use a rope to represent the text being edited, so that operations such as insertion, deletion, and random access can be done efficiently.

In computer science, a radix tree is a data structure that represents a space-optimized trie in which each node that is the only child is merged with its parent. The result is that the number of children of every internal node is at most the radix r of the radix tree, where r = 2x for some integer x ≥ 1. Unlike regular trees, edges can be labeled with sequences of elements as well as single elements. This makes radix trees much more efficient for small sets and for sets of strings that share long prefixes.
In computer programming, a sentinel node is a specifically designated node used with linked lists and trees as a traversal path terminator. This type of node does not hold or reference any data managed by the data structure.

In computer science, recursion is a method of solving a computational problem where the solution depends on solutions to smaller instances of the same problem. Recursion solves such recursive problems by using functions that call themselves from within their own code. The approach can be applied to many types of problems, and recursion is one of the central ideas of computer science.
The power of recursion evidently lies in the possibility of defining an infinite set of objects by a finite statement. In the same manner, an infinite number of computations can be described by a finite recursive program, even if this program contains no explicit repetitions.

In computer science, a ternary tree is a tree data structure in which each node has at most three child nodes, usually distinguished as "left", “mid” and "right". Nodes with children are parent nodes, and child nodes may contain references to their parents. Outside the tree, there is often a reference to the "root" node, if it exists. Any node in the data structure can be reached by starting at root node and repeatedly following references to either the left, mid or right child.
In computer science, an x-fast trie is a data structure for storing integers from a bounded domain. It supports exact and predecessor or successor queries in time O(log log M), using O(n log M) space, where n is the number of stored values and M is the maximum value in the domain. The structure was proposed by Dan Willard in 1982, along with the more complicated y-fast trie, as a way to improve the space usage of van Emde Boas trees, while retaining the O(log log M) query time.
A concurrent hash-trie or Ctrie is a concurrent thread-safe lock-free implementation of a hash array mapped trie. It is used to implement the concurrent map abstraction. It has particularly scalable concurrent insert and remove operations and is memory-efficient. It is the first known concurrent data-structure that supports O(1), atomic, lock-free snapshots.
Parallel Specification and Implementation Language (ParaSail) is an object-oriented parallel programming language. Its design and ongoing implementation is described in a blog and on its official website.
The HAT-trie is a type of radix trie that uses array nodes to collect individual key–value pairs under radix nodes and hash buckets into an associative array. Unlike a simple hash table, HAT-tries store key–value in an ordered collection. The original inventors are Nikolas Askitis and Ranjan Sinha. Askitis & Zobel showed that building and accessing the HAT-trie key/value collection is considerably faster than other sorted access methods and is comparable to the array hash which is an unsorted collection. This is due to the cache-friendly nature of the data structure which attempts to group access to data in time and space into the 64 byte cache line size of the modern CPU.
Multi-key quicksort, also known as three-way radix quicksort, is an algorithm for sorting strings. This hybrid of quicksort and radix sort was originally suggested by P. Shackleton, as reported in one of C.A.R. Hoare's seminal papers on quicksort; its modern incarnation was developed by Jon Bentley and Robert Sedgewick in the mid-1990s. The algorithm is designed to exploit the property that in many problems, strings tend to have shared prefixes.
A bitwise trie is a special form of trie where each node with its child-branches represents a bit sequence of one or more bits of a key. A bitwise trie with bitmap uses a bitmap to denote valid child branches.