
In computer science, a binary search tree (BST), also called an ordered or sorted binary tree, is a rooted binary tree data structure with the key of each internal node being greater than all the keys in the respective node's left subtree and less than the ones in its right subtree. The time complexity of operations on the binary search tree is directly proportional to the height of the tree.

In computer science, a binary tree is a k-ary tree data structure in which each node has at most two children, which are referred to as the left child and the right child. A recursive definition using just set theory notions is that a (non-empty) binary tree is a tuple (L, S, R), where L and R are binary trees or the empty set and S is a singleton set containing the root. Some authors allow the binary tree to be the empty set as well.

In computer science, a heap is a specialized tree-based data structure that satisfies the heap property: In a max heap, for any given node C, if P is a parent node of C, then the key of P is greater than or equal to the key of C. In a min heap, the key of P is less than or equal to the key of C. The node at the "top" of the heap is called the root node.
In computer science, a red–black tree is a specialised binary search tree data structure noted for fast storage and retrieval of ordered information, and a guarantee that operations will complete within a known time. Compared to other self-balancing binary search trees, the nodes in a red-black tree hold an extra bit called "color" representing "red" and "black" which is used when re-organising the tree to ensure that it is always approximately balanced.

In computer science, a tree is a widely used abstract data type that represents a hierarchical tree structure with a set of connected nodes. Each node in the tree can be connected to many children, but must be connected to exactly one parent, except for the root node, which has no parent. These constraints mean there are no cycles or "loops", and also that each child can be treated like the root node of its own subtree, making recursion a useful technique for tree traversal. In contrast to linear data structures, many trees cannot be represented by relationships between neighboring nodes in a single straight line.

A binary heap is a heap data structure that takes the form of a binary tree. Binary heaps are a common way of implementing priority queues. The binary heap was introduced by J. W. J. Williams in 1964, as a data structure for heapsort.
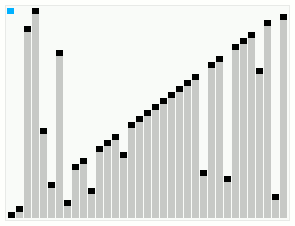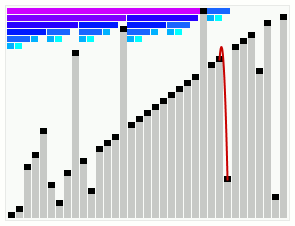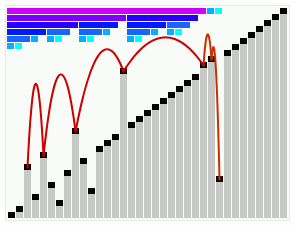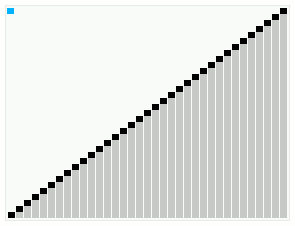
In computer science, smoothsort is a comparison-based sorting algorithm. A variant of heapsort, it was invented and published by Edsger Dijkstra in 1981. Like heapsort, smoothsort is an in-place algorithm with an upper bound of O(n log n), but it is not a stable sort. The advantage of smoothsort is that it comes closer to O(n) time if the input is already sorted to some degree, whereas heapsort averages O(n log n) regardless of the initial sorted state.
In computer science, a binomial heap is a data structure that acts as a priority queue but also allows pairs of heaps to be merged. It is important as an implementation of the mergeable heap abstract data type, which is a priority queue supporting merge operation. It is implemented as a heap similar to a binary heap but using a special tree structure that is different from the complete binary trees used by binary heaps. Binomial heaps were invented in 1978 by Jean Vuillemin.
In computer science, a Fibonacci heap is a data structure for priority queue operations, consisting of a collection of heap-ordered trees. It has a better amortized running time than many other priority queue data structures including the binary heap and binomial heap. Michael L. Fredman and Robert E. Tarjan developed Fibonacci heaps in 1984 and published them in a scientific journal in 1987. Fibonacci heaps are named after the Fibonacci numbers, which are used in their running time analysis.
In computer science, tree traversal is a form of graph traversal and refers to the process of visiting each node in a tree data structure, exactly once. Such traversals are classified by the order in which the nodes are visited. The following algorithms are described for a binary tree, but they may be generalized to other trees as well.
A B+ tree is an m-ary tree with a variable but often large number of children per node. A B+ tree consists of a root, internal nodes and leaves. The root may be either a leaf or a node with two or more children.
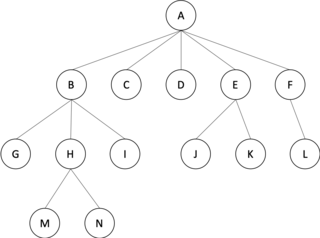
In graph theory, an m-ary tree is an arborescence in which each node has no more than m children. A binary tree is the special case where m = 2, and a ternary tree is another case with m = 3 that limits its children to three.
The d-ary heap or d-heap is a priority queue data structure, a generalization of the binary heap in which the nodes have d children instead of 2. Thus, a binary heap is a 2-heap, and a ternary heap is a 3-heap. According to Tarjan and Jensen et al., d-ary heaps were invented by Donald B. Johnson in 1975.
In computer science, a pagoda is a priority queue implemented with a variant of a binary tree. The root points to its children, as in a binary tree. Every other node points back to its parent and down to its leftmost or rightmost descendant leaf. The basic operation is merge or meld, which maintains the heap property. An element is inserted by merging it as a singleton. The root is removed by merging its right and left children. Merging is bottom-up, merging the leftmost edge of one with the rightmost edge of the other.

In computer science, a Cartesian tree is a binary tree derived from a sequence of distinct numbers. To construct the Cartesian tree, set its root to be the minimum number in the sequence, and recursively construct its left and right subtrees from the subsequences before and after this number. It is uniquely defined as a min-heap whose symmetric (in-order) traversal returns the original sequence.

In computer science, a ternary tree is a tree data structure in which each node has at most three child nodes, usually distinguished as "left", “mid” and "right". Nodes with children are parent nodes, and child nodes may contain references to their parents. Outside the tree, there is often a reference to the "root" node, if it exists. Any node in the data structure can be reached by starting at root node and repeatedly following references to either the left, mid or right child.
A B-heap is a binary heap implemented to keep subtrees in a single page. This reduces the number of pages accessed by up to a factor of ten for big heaps when using virtual memory, compared with the traditional implementation. The traditional mapping of elements to locations in an array puts almost every level in a different page.
In computer science, a weak heap is a data structure for priority queues, combining features of the binary heap and binomial heap. It can be stored in an array as an implicit binary tree like a binary heap, and has the efficiency guarantees of binomial heaps.

