An intron is any nucleotide sequence within a gene that is not expressed or operative in the final RNA product. The word intron is derived from the term intragenic region, i.e., a region inside a gene. The term intron refers to both the DNA sequence within a gene and the corresponding RNA sequence in RNA transcripts. The non-intron sequences that become joined by this RNA processing to form the mature RNA are called exons.

In biology, a mutation is an alteration in the nucleic acid sequence of the genome of an organism, virus, or extrachromosomal DNA. Viral genomes contain either DNA or RNA. Mutations result from errors during DNA or viral replication, mitosis, or meiosis or other types of damage to DNA, which then may undergo error-prone repair, cause an error during other forms of repair, or cause an error during replication. Mutations may also result from insertion or deletion of segments of DNA due to mobile genetic elements.

A prion is a misfolded protein that induces misfolding in normal variants of the same protein, leading to cellular death. Prions are responsible for prion diseases, known as transmissible spongiform encephalopathies (TSEs), which are fatal and transmissible neurodegenerative diseases affecting both humans and animals. These proteins can misfold sporadically, due to genetic mutations, or by exposure to an already misfolded protein, leading to an abnormal three-dimensional structure that can propagate misfolding in other proteins.

The human genome is a complete set of nucleic acid sequences for humans, encoded as DNA within the 23 chromosome pairs in cell nuclei and in a small DNA molecule found within individual mitochondria. These are usually treated separately as the nuclear genome and the mitochondrial genome. Human genomes include both protein-coding DNA sequences and various types of DNA that does not encode proteins. The latter is a diverse category that includes DNA coding for non-translated RNA, such as that for ribosomal RNA, transfer RNA, ribozymes, small nuclear RNAs, and several types of regulatory RNAs. It also includes promoters and their associated gene-regulatory elements, DNA playing structural and replicatory roles, such as scaffolding regions, telomeres, centromeres, and origins of replication, plus large numbers of transposable elements, inserted viral DNA, non-functional pseudogenes and simple, highly repetitive sequences. Introns make up a large percentage of non-coding DNA. Some of this non-coding DNA is non-functional junk DNA, such as pseudogenes, but there is no firm consensus on the total amount of junk DNA.
An inverted repeat is a single stranded sequence of nucleotides followed downstream by its reverse complement. The intervening sequence of nucleotides between the initial sequence and the reverse complement can be any length including zero. For example, 5'---TTACGnnnnnnCGTAA---3' is an inverted repeat sequence. When the intervening length is zero, the composite sequence is a palindromic sequence.
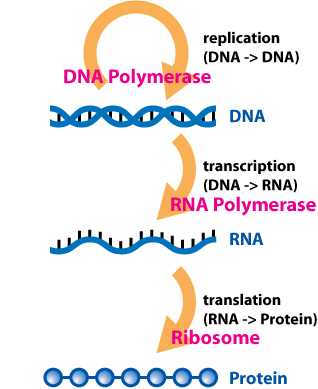
The central dogma of molecular biology deals with the flow of genetic information within a biological system. It is often stated as "DNA makes RNA, and RNA makes protein", although this is not its original meaning. It was first stated by Francis Crick in 1957, then published in 1958:
The Central Dogma. This states that once "information" has passed into protein it cannot get out again. In more detail, the transfer of information from nucleic acid to nucleic acid, or from nucleic acid to protein may be possible, but transfer from protein to protein, or from protein to nucleic acid is impossible. Information here means the precise determination of sequence, either of bases in the nucleic acid or of amino acid residues in the protein.

A non-coding RNA (ncRNA) is a functional RNA molecule that is not translated into a protein. The DNA sequence from which a functional non-coding RNA is transcribed is often called an RNA gene. Abundant and functionally important types of non-coding RNAs include transfer RNAs (tRNAs) and ribosomal RNAs (rRNAs), as well as small RNAs such as microRNAs, siRNAs, piRNAs, snoRNAs, snRNAs, exRNAs, scaRNAs and the long ncRNAs such as Xist and HOTAIR.
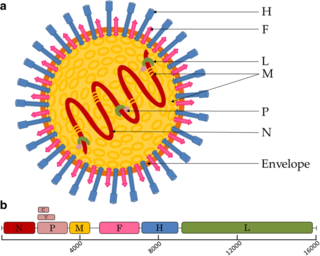
Paramyxoviridae is a family of negative-strand RNA viruses in the order Mononegavirales. Vertebrates serve as natural hosts. Diseases associated with this family include measles, mumps, and respiratory tract infections. The family has four subfamilies, 17 genera, three of which are unassigned to a subfamily, and 78 species.
The coding region of a gene, also known as the coding sequence (CDS), is the portion of a gene's DNA or RNA that codes for a protein. Studying the length, composition, regulation, splicing, structures, and functions of coding regions compared to non-coding regions over different species and time periods can provide a significant amount of important information regarding gene organization and evolution of prokaryotes and eukaryotes. This can further assist in mapping the human genome and developing gene therapy.
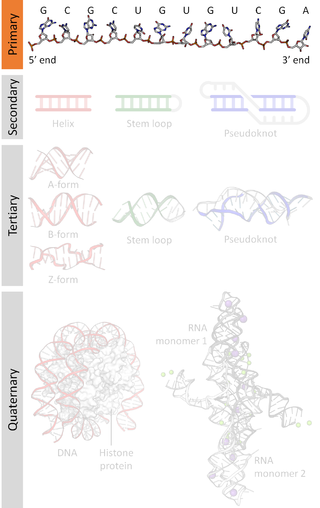
A nucleic acid sequence is a succession of bases within the nucleotides forming alleles within a DNA or RNA (GACU) molecule. This succession is denoted by a series of a set of five different letters that indicate the order of the nucleotides. By convention, sequences are usually presented from the 5' end to the 3' end. For DNA, with its double helix, there are two possible directions for the notated sequence; of these two, the sense strand is used. Because nucleic acids are normally linear (unbranched) polymers, specifying the sequence is equivalent to defining the covalent structure of the entire molecule. For this reason, the nucleic acid sequence is also termed the primary structure.
In molecular genetics, the three prime untranslated region (3′-UTR) is the section of messenger RNA (mRNA) that immediately follows the translation termination codon. The 3′-UTR often contains regulatory regions that post-transcriptionally influence gene expression.

In genetics and bioinformatics, a single-nucleotide polymorphism is a germline substitution of a single nucleotide at a specific position in the genome. Although certain definitions require the substitution to be present in a sufficiently large fraction of the population, many publications do not apply such a frequency threshold.

A frameshift mutation is a genetic mutation caused by indels of a number of nucleotides in a DNA sequence that is not divisible by three. Due to the triplet nature of gene expression by codons, the insertion or deletion can change the reading frame, resulting in a completely different translation from the original. The earlier in the sequence the deletion or insertion occurs, the more altered the protein. A frameshift mutation is not the same as a single-nucleotide polymorphism in which a nucleotide is replaced, rather than inserted or deleted. A frameshift mutation will in general cause the reading of the codons after the mutation to code for different amino acids. The frameshift mutation will also alter the first stop codon encountered in the sequence. The polypeptide being created could be abnormally short or abnormally long, and will most likely not be functional.

A point mutation is a genetic mutation where a single nucleotide base is changed, inserted or deleted from a DNA or RNA sequence of an organism's genome. Point mutations have a variety of effects on the downstream protein product—consequences that are moderately predictable based upon the specifics of the mutation. These consequences can range from no effect to deleterious effects, with regard to protein production, composition, and function.
In genetics, a nonsense mutation is a point mutation in a sequence of DNA that results in a nonsense codon, or a premature stop codon in the transcribed mRNA, and leads to a truncated, incomplete, and possibly nonfunctional protein product. Nonsense mutations are not always harmful; the functional effect of a nonsense mutation depends on many aspects, such as the location of the stop codon within the coding DNA. For example, the effect of a nonsense mutation depends on the proximity of the nonsense mutation to the original stop codon, and the degree to which functional subdomains of the protein are affected. As nonsense mutations leads to premature termination of polypeptide chains; they are also called chain termination mutations.
The major prion protein (PrP) is encoded in the human body by the PRNP gene also known as CD230. Expression of the protein is most predominant in the nervous system but occurs in many other tissues throughout the body.

In biology, the word gene has two meanings. The Mendelian gene is a basic unit of heredity. The molecular gene is a sequence of nucleotides in DNA that is transcribed to produce a functional RNA. There are two types of molecular genes: protein-coding genes and non-coding genes.

A splice site mutation is a genetic mutation that inserts, deletes or changes a number of nucleotides in the specific site at which splicing takes place during the processing of precursor messenger RNA into mature messenger RNA. Splice site consensus sequences that drive exon recognition are located at the very termini of introns. The deletion of the splicing site results in one or more introns remaining in mature mRNA and may lead to the production of abnormal proteins. When a splice site mutation occurs, the mRNA transcript possesses information from these introns that normally should not be included. Introns are supposed to be removed, while the exons are expressed.
In molecular genetics, an untranslated region refers to either of two sections, one on each side of a coding sequence on a strand of mRNA. If it is found on the 5' side, it is called the 5' UTR, or if it is found on the 3' side, it is called the 3' UTR. mRNA is RNA that carries information from DNA to the ribosome, the site of protein synthesis (translation) within a cell. The mRNA is initially transcribed from the corresponding DNA sequence and then translated into protein. However, several regions of the mRNA are usually not translated into protein, including the 5' and 3' UTRs.
Ribosomal frameshifting, also known as translational frameshifting or translational recoding, is a biological phenomenon that occurs during translation that results in the production of multiple, unique proteins from a single mRNA. The process can be programmed by the nucleotide sequence of the mRNA and is sometimes affected by the secondary, 3-dimensional mRNA structure. It has been described mainly in viruses, retrotransposons and bacterial insertion elements, and also in some cellular genes.
