Related Research Articles
In computer science, a B-tree is a self-balancing tree data structure that maintains sorted data and allows searches, sequential access, insertions, and deletions in logarithmic time. The B-tree generalizes the binary search tree, allowing for nodes with more than two children. Unlike other self-balancing binary search trees, the B-tree is well suited for storage systems that read and write relatively large blocks of data, such as databases and file systems.

In computer science and information theory, a Huffman code is a particular type of optimal prefix code that is commonly used for lossless data compression. The process of finding or using such a code is Huffman coding, an algorithm developed by David A. Huffman while he was a Sc.D. student at MIT, and published in the 1952 paper "A Method for the Construction of Minimum-Redundancy Codes".

A minimum spanning tree (MST) or minimum weight spanning tree is a subset of the edges of a connected, edge-weighted undirected graph that connects all the vertices together, without any cycles and with the minimum possible total edge weight. That is, it is a spanning tree whose sum of edge weights is as small as possible. More generally, any edge-weighted undirected graph has a minimum spanning forest, which is a union of the minimum spanning trees for its connected components.
A* is a graph traversal and pathfinding algorithm, which is used in many fields of computer science due to its completeness, optimality, and optimal efficiency. Given a weighted graph, a source node and a goal node, the algorithm finds the shortest path from source to goal.
Alpha–beta pruning is a search algorithm that seeks to decrease the number of nodes that are evaluated by the minimax algorithm in its search tree. It is an adversarial search algorithm used commonly for machine playing of two-player combinatorial games. It stops evaluating a move when at least one possibility has been found that proves the move to be worse than a previously examined move. Such moves need not be evaluated further. When applied to a standard minimax tree, it returns the same move as minimax would, but prunes away branches that cannot possibly influence the final decision.

In computer science, the treap and the randomized binary search tree are two closely related forms of binary search tree data structures that maintain a dynamic set of ordered keys and allow binary searches among the keys. After any sequence of insertions and deletions of keys, the shape of the tree is a random variable with the same probability distribution as a random binary tree; in particular, with high probability its height is proportional to the logarithm of the number of keys, so that each search, insertion, or deletion operation takes logarithmic time to perform.
Combinatorial game theory measures game complexity in several ways:
- State-space complexity,
- Game tree size,
- Decision complexity,
- Game-tree complexity,
- Computational complexity.

R-trees are tree data structures used for spatial access methods, i.e., for indexing multi-dimensional information such as geographical coordinates, rectangles or polygons. The R-tree was proposed by Antonin Guttman in 1984 and has found significant use in both theoretical and applied contexts. A common real-world usage for an R-tree might be to store spatial objects such as restaurant locations or the polygons that typical maps are made of: streets, buildings, outlines of lakes, coastlines, etc. and then find answers quickly to queries such as "Find all museums within 2 km of my current location", "retrieve all road segments within 2 km of my location" or "find the nearest gas station". The R-tree can also accelerate nearest neighbor search for various distance metrics, including great-circle distance.
In combinatorial mathematics, the Prüfer sequence of a labeled tree is a unique sequence associated with the tree. The sequence for a tree on n vertices has length n − 2, and can be generated by a simple iterative algorithm. Prüfer sequences were first used by Heinz Prüfer to prove Cayley's formula in 1918.

In computer science, a k-d tree is a space-partitioning data structure for organizing points in a k-dimensional space. K-dimensional is that which concerns exactly k orthogonal axes or a space of any number of dimensions. k-d trees are a useful data structure for several applications, such as:
Principal variation search is a negamax algorithm that can be faster than alpha–beta pruning. Like alpha–beta pruning, NegaScout is a directional search algorithm for computing the minimax value of a node in a tree. It dominates alpha–beta pruning in the sense that it will never examine a node that can be pruned by alpha–beta; however, it relies on accurate node ordering to capitalize on this advantage.
In backtracking algorithms, backjumping is a technique that reduces search space, therefore increasing efficiency. While backtracking always goes up one level in the search tree when all values for a variable have been tested, backjumping may go up more levels. In this article, a fixed order of evaluation of variables is used, but the same considerations apply to a dynamic order of evaluation.
An and–or tree is a graphical representation of the reduction of problems to conjunctions and disjunctions of subproblems.
In computer science, B* is a best-first graph search algorithm that finds the least-cost path from a given initial node to any goal node. First published by Hans Berliner in 1979, it is related to the A* search algorithm.

In computer science, a Cartesian tree is a binary tree derived from a sequence of distinct numbers. To construct the Cartesian tree, set its root to be the minimum number in the sequence, and recursively construct its left and right subtrees from the subsequences before and after this number. It is uniquely defined as a min-heap whose symmetric (in-order) traversal returns the original sequence.
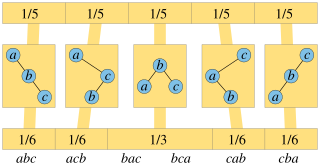
In computer science and probability theory, a random binary tree is a binary tree selected at random from some probability distribution on binary trees. Different distributions have been used, leading to different properties for these trees.
In computer science, a ball tree, balltree or metric tree, is a space partitioning data structure for organizing points in a multi-dimensional space. A ball tree partitions data points into a nested set of balls. The resulting data structure has characteristics that make it useful for a number of applications, most notably nearest neighbor search.
In computer science, Monte Carlo tree search (MCTS) is a heuristic search algorithm for some kinds of decision processes, most notably those employed in software that plays board games. In that context MCTS is used to solve the game tree.
In computer science, k-way merge algorithms or multiway merges are a specific type of sequence merge algorithms that specialize in taking in k sorted lists and merging them into a single sorted list. These merge algorithms generally refer to merge algorithms that take in a number of sorted lists greater than two. Two-way merges are also referred to as binary merges. The k-way merge is also an external sorting algorithm.
The Garsia–Wachs algorithm is an efficient method for computers to construct optimal binary search trees and alphabetic Huffman codes, in linearithmic time. It is named after Adriano Garsia and Michelle L. Wachs.
References
- ↑ Allis, L Victor. Searching for Solutions in Games and Artificial Intelligence. PhD Thesis. Ponsen & Looijen. ISBN 90-9007488-0. Archived from the original on 2004-12-04. Retrieved 24 Oct 2014.
{{cite book}}: CS1 maint: bot: original URL status unknown (link) - ↑ Mark H.M. Winands, Jos W.H.M. Uiterwijk, and H. Jaap van den Herik (2003). PDS-PN: A New Proof-Number Search Algorithm (PDF). Lecture Notes in Computer Science.
{{cite book}}: CS1 maint: multiple names: authors list (link)