Related Research Articles

A programming language is a system of notation for writing computer programs. Programming languages are described in terms of their syntax (form) and semantics (meaning), usually defined by a formal language. Languages usually provide features such as a type system, variables, and mechanisms for error handling. An implementation of a programming language is required in order to execute programs, namely an interpreter or a compiler. An interpreter directly executes the source code, while a compiler produces an executable program.
Prolog is a logic programming language that has its origins in artificial intelligence, automated theorem proving and computational linguistics.
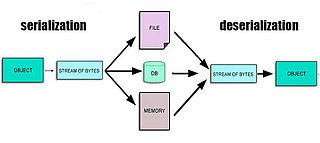
In computing, serialization is the process of translating a data structure or object state into a format that can be stored or transmitted and reconstructed later. When the resulting series of bits is reread according to the serialization format, it can be used to create a semantically identical clone of the original object. For many complex objects, such as those that make extensive use of references, this process is not straightforward. Serialization of objects does not include any of their associated methods with which they were previously linked.

The Semantic Web, sometimes known as Web 3.0, is an extension of the World Wide Web through standards set by the World Wide Web Consortium (W3C). The goal of the Semantic Web is to make Internet data machine-readable.
The Web Ontology Language (OWL) is a family of knowledge representation languages for authoring ontologies. Ontologies are a formal way to describe taxonomies and classification networks, essentially defining the structure of knowledge for various domains: the nouns representing classes of objects and the verbs representing relations between the objects.
SWI-Prolog is a free implementation of the programming language Prolog, commonly used for teaching and semantic web applications. It has a rich set of features, libraries for constraint logic programming, multithreading, unit testing, GUI, interfacing to Java, ODBC and others, literate programming, a web server, SGML, RDF, RDFS, developer tools, and extensive documentation.
Constraint Handling Rules (CHR) is a declarative, rule-based programming language, introduced in 1991 by Thom Frühwirth at the time with European Computer-Industry Research Centre (ECRC) in Munich, Germany. Originally intended for constraint programming, CHR finds applications in grammar induction, type systems, abductive reasoning, multi-agent systems, natural language processing, compilation, scheduling, spatial-temporal reasoning, testing, and verification.
The Semantic Web Rule Language (SWRL) is a proposed language for the Semantic Web that can be used to express rules as well as logic, combining OWL DL or OWL Lite with a subset of the Rule Markup Language.
The following outline is provided as an overview of and topical guide to computer programming:
A semantic reasoner, reasoning engine, rules engine, or simply a reasoner, is a piece of software able to infer logical consequences from a set of asserted facts or axioms. The notion of a semantic reasoner generalizes that of an inference engine, by providing a richer set of mechanisms to work with. The inference rules are commonly specified by means of an ontology language, and often a description logic language. Many reasoners use first-order predicate logic to perform reasoning; inference commonly proceeds by forward chaining and backward chaining. There are also examples of probabilistic reasoners, including non-axiomatic reasoning systems, and probabilistic logic networks.

In computer science, information science and systems engineering, ontology engineering is a field which studies the methods and methodologies for building ontologies, which encompasses a representation, formal naming and definition of the categories, properties and relations between the concepts, data and entities of a given domain of interest. In a broader sense, this field also includes a knowledge construction of the domain using formal ontology representations such as OWL/RDF. A large-scale representation of abstract concepts such as actions, time, physical objects and beliefs would be an example of ontological engineering. Ontology engineering is one of the areas of applied ontology, and can be seen as an application of philosophical ontology. Core ideas and objectives of ontology engineering are also central in conceptual modeling.
Ontology engineering aims at making explicit the knowledge contained within software applications, and within enterprises and business procedures for a particular domain. Ontology engineering offers a direction towards solving the inter-operability problems brought about by semantic obstacles, i.e. the obstacles related to the definitions of business terms and software classes. Ontology engineering is a set of tasks related to the development of ontologies for a particular domain.
An application programming interface (API) is a connection between computers or between computer programs. It is a type of software interface, offering a service to other pieces of software. A document or standard that describes how to build such a connection or interface is called an API specification. A computer system that meets this standard is said to implement or expose an API. The term API may refer either to the specification or to the implementation.
Ciao is a general-purpose programming language which supports logic, constraint, functional, higher-order, and object-oriented programming styles. Its main design objectives are high expressive power, extensibility, safety, reliability, and efficient execution.
OMeta is a specialized object-oriented programming language for pattern matching, developed by Alessandro Warth and Ian Piumarta in 2007 at the Viewpoints Research Institute. The language is based on parsing expression grammars (PEGs), rather than context-free grammars, with the intent to provide "a natural and convenient way for programmers to implement tokenizers, parsers, visitors, and tree-transformers".
References
- A. Kozlenkov and M. Schroeder. PROVA: Rule-based Java-Scripting for a Bioinformatics Semantic Web. In E. Rahm, editor, International Workshop on Data Integration in the Life Sciences, Leipzig, Germany, in Lecture Notes in Computer Science, Springer-Verlag, vol. 2994, pp. 17–30, 2004.
- N. Combs and J.-L. Ardoint. Rules versus Scripts in Games Artificial Intelligence, AAAI 2004 Workshop on Challenges in Game AI, 2004.
- J. Dietrich, A. Kozlenkov, M. Schroeder, and G. Wagner. Rule-based Agents for the Semantic Web, Electronic Commerce Research and Applications, vol. 2, no. 4, pp. 323–338, 2004.
- A. Paschke, M. Bichler, and J. Dietrich. ContractLog: An Approach to Rule Based Monitoring and Execution of Service Level Agreements, Int. Conf. on Rules and Rule Markup Languages for the Semantic Web (RuleML 2005), Galway, Ireland, 2005.
- A. Kozlenkov, R. Penaloza, V. Nigam, L. Royer, G. Dawelbait, and M. Schroeder. Prova: Rule-based Java Scripting for Distributed Web Applications: A Case Study in Bioinformatics, Reactivity on the Web Workshop, Munich 2006.