Pseudo-LRU or PLRU is a family of cache algorithms which improve on the performance of the Least Recently Used (LRU) algorithm by replacing values using approximate measures of age rather than maintaining the exact age of every value in the cache.
PLRU usually refers to two cache replacement algorithms: tree-PLRU and bit-PLRU.
Tree-PLRU
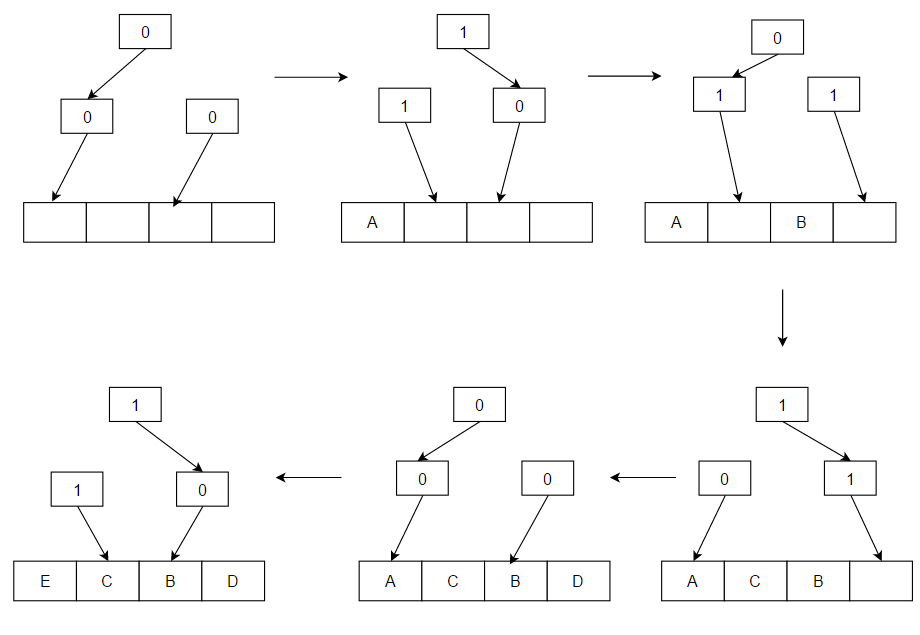
Tree-PLRU is an efficient algorithm to select an item that most likely has not been accessed very recently, given a set of items and a sequence of access events to the items.
The algorithm works as follows: consider a binary search tree for the items in question. Each node of the tree has a one-bit flag denoting "go left to insert a pseudo-LRU element" or "go right to insert a pseudo-LRU element". To find a pseudo-LRU element, traverse the tree according to the values of the flags. To update the tree with an access to an item N, traverse the tree to find N and, during the traversal, set the node flags to denote the direction that is opposite to the direction taken.
Pseudo LRU working
This algorithm can be sub-optimal since it is an approximation. For example, in the above diagram with A, C, B, D cache lines, if the access pattern was: C, B, D, A, on an eviction, B would be chosen instead of C. This is because both A and C are in the same half and accessing A directs the algorithm to the other half that does not contain cache line C.
Bit-PLRU
Bit-PLRU stores one status bit for each cache line. These bits are called MRU-bits. Every access to a line sets its MRU-bit to 1, indicating that the line was recently used. Whenever the last remaining 0 bit of a set's status bits is set to 1, all other bits are reset to 0. At cache misses, the leftmost line whose MRU-bit is 0 is replaced.[1]
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.