Related Research Articles

A supercomputer is a type of computer with a high level of performance as compared to a general-purpose computer. The performance of a supercomputer is commonly measured in floating-point operations per second (FLOPS) instead of million instructions per second (MIPS). Since 2017, supercomputers have existed which can perform over 1017 FLOPS (a hundred quadrillion FLOPS, 100 petaFLOPS or 100 PFLOPS). For comparison, a desktop computer has performance in the range of hundreds of gigaFLOPS (1011) to tens of teraFLOPS (1013). Since November 2017, all of the world's fastest 500 supercomputers run on Linux-based operating systems. Additional research is being conducted in the United States, the European Union, Taiwan, Japan, and China to build faster, more powerful and technologically superior exascale supercomputers.

High-performance computing (HPC) uses supercomputers and computer clusters to solve advanced computation problems.
E-Science or eScience is computationally intensive science that is carried out in highly distributed network environments, or science that uses immense data sets that require grid computing; the term sometimes includes technologies that enable distributed collaboration, such as the Access Grid. The term was created by John Taylor, the Director General of the United Kingdom's Office of Science and Technology in 1999 and was used to describe a large funding initiative starting in November 2000. E-science has been more broadly interpreted since then, as "the application of computer technology to the undertaking of modern scientific investigation, including the preparation, experimentation, data collection, results dissemination, and long-term storage and accessibility of all materials generated through the scientific process. These may include data modeling and analysis, electronic/digitized laboratory notebooks, raw and fitted data sets, manuscript production and draft versions, pre-prints, and print and/or electronic publications." In 2014, IEEE eScience Conference Series condensed the definition to "eScience promotes innovation in collaborative, computationally- or data-intensive research across all disciplines, throughout the research lifecycle" in one of the working definitions used by the organizers. E-science encompasses "what is often referred to as big data [which] has revolutionized science... [such as] the Large Hadron Collider (LHC) at CERN... [that] generates around 780 terabytes per year... highly data intensive modern fields of science...that generate large amounts of E-science data include: computational biology, bioinformatics, genomics" and the human digital footprint for the social sciences.
Computational science, also known as scientific computing, technical computing or scientific computation (SC), is a division of science that uses advanced computing capabilities to understand and solve complex physical problems. This includes
General-purpose computing on graphics processing units is the use of a graphics processing unit (GPU), which typically handles computation only for computer graphics, to perform computation in applications traditionally handled by the central processing unit (CPU). The use of multiple video cards in one computer, or large numbers of graphics chips, further parallelizes the already parallel nature of graphics processing.
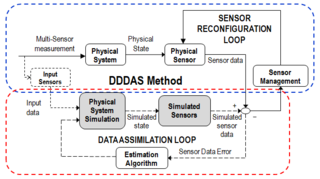
Dynamic Data Driven Applications Systems ("DDDAS") is a paradigm whereby the computation and instrumentation aspects of an application system are dynamically integrated with a feedback control loop, in the sense that instrumentation data can be dynamically incorporated into the executing model of the application, and in reverse the executing model can control the system's instrumentation to cognizantly and adaptively acquire additional data, which in-turn can improve or speedup the model. DDDAS-based approaches have been shown that they can enable more accurate and faster modeling and analysis of the characteristics and behaviors of a system and can exploit data in intelligent ways to convert them to new capabilities, including decision support systems with the accuracy of full-scale modeling, executing model-driven adaptive management of complex instrumentation, as well as efficient data collection, management, and data mining.
Advanced Resource Connector (ARC) is a grid computing middleware introduced by NorduGrid. It provides a common interface for submission of computational tasks to different distributed computing systems and thus can enable grid infrastructures of varying size and complexity. The set of services and utilities providing the interface is known as ARC Computing Element (ARC-CE). ARC-CE functionality includes data staging and caching, developed in order to support data-intensive distributed computing. ARC is an open source software distributed under the Apache License 2.0.
Nimrod is a tool for the parametrization of serial programs to create and execute embarrassingly parallel programs over a computational grid. It is a co-allocating, scheduling and brokering service. Nimrod was one of the first tools to make use of heterogeneous resources in a grid for a single computation. It was also an early example of using a market economy to perform grid scheduling. This enables Nimrod to provide a guaranteed completion time despite using best-effort services.

Volunteer computing is a type of distributed computing in which people donate their computers' unused resources to a research-oriented project, and sometimes in exchange for credit points. The fundamental idea behind it is that a modern desktop computer is sufficiently powerful to perform billions of operations a second, but for most users only between 10–15% of its capacity is used. Common tasks such as word processing or web browsing leave the computer mostly idle.
Xgrid is a proprietary grid computing program and protocol developed by the Advanced Computation Group subdivision of Apple Inc.

Iterative Stencil Loops (ISLs) or Stencil computations are a class of numerical data processing solution which update array elements according to some fixed pattern, called a stencil. They are most commonly found in computer simulations, e.g. for computational fluid dynamics in the context of scientific and engineering applications. Other notable examples include solving partial differential equations, the Jacobi kernel, the Gauss–Seidel method, image processing and cellular automata. The regular structure of the arrays sets stencil techniques apart from other modeling methods such as the Finite element method. Most finite difference codes which operate on regular grids can be formulated as ISLs.

A computer cluster is a set of computers that work together so that they can be viewed as a single system. Unlike grid computers, computer clusters have each node set to perform the same task, controlled and scheduled by software. The newest manifestation of cluster computing is cloud computing.
In computing, algorithmic skeletons, or parallelism patterns, are a high-level parallel programming model for parallel and distributed computing.

Róbert Lovas is a Hungarian computer scientist at SZTAKI, Budapest, Hungary.
Discovery Net is one of the earliest examples of a scientific workflow system allowing users to coordinate the execution of remote services based on Web service and Grid Services standards. The system was designed and implemented at Imperial College London as part of the Discovery Net pilot project funded by the UK e-Science Programme. Many of the concepts pioneered by Discovery Net have been later incorporated into a variety of other scientific workflow systems.
Polish Grid Infrastructure PL-Grid, a nationwide computing structure, built in 2009-2011, under the scientific project PL-Grid – Polish Infrastructure for Supporting Computational Science in the European Research Space. Its purpose was to enable scientific research based on advanced computer simulations and large-scale computations using the computer clusters, and to provide convenient access to the computer resources for research teams, also outside the communities, in which the high performance computing centers operate.

Quasi-opportunistic supercomputing is a computational paradigm for supercomputing on a large number of geographically disperse computers. Quasi-opportunistic supercomputing aims to provide a higher quality of service than opportunistic resource sharing.
SciEngines GmbH is a privately owned company founded 2007 as a spin-off of the COPACOBANA project by the Universities of Bochum and Kiel, both in Germany. The project intended to create a platform for an affordable Custom hardware attack. COPACOBANA is a massively-parallel reconfigurable computer. It can be utilized to perform a so-called Brute force attack to recover DES encrypted data. It consists of 120 commercially available, reconfigurable integrated circuits (FPGAs). These Xilinx Spartan3-1000 run in parallel, and create a massively parallel system. Since 2007, SciEngines GmbH has enhanced and developed successors of COPACOBANA. Furthermore, the COPACOBANA has become a well known reference platform for cryptanalysis and custom hardware based attacks to symmetric, asymmetric cyphers and stream ciphers. 2008 attacks against A5/1 stream cipher an encryption system been used to encrypt voice streams in GSM have been published as the first known real world attack utilizing off-the-shelf custom hardware.

Approaches to supercomputer architecture have taken dramatic turns since the earliest systems were introduced in the 1960s. Early supercomputer architectures pioneered by Seymour Cray relied on compact innovative designs and local parallelism to achieve superior computational peak performance. However, in time the demand for increased computational power ushered in the age of massively parallel systems.
Message passing is an inherent element of all computer clusters. All computer clusters, ranging from homemade Beowulfs to some of the fastest supercomputers in the world, rely on message passing to coordinate the activities of the many nodes they encompass. Message passing in computer clusters built with commodity servers and switches is used by virtually every internet service.
References
- ↑ Computational Science - Iccs 2009: 9th International Conference edited by Gabrielle Allen, Jarek Nabrzyski 2009 ISBN 3-642-01969-2 page 395
- ↑ Computational Science - Iccs 2008: 8th International Conference edited by Marian Bubak 2008 ISBN 978-3-540-69383-3 pages 112-113