Related Research Articles

In genetics, complementary DNA (cDNA) is DNA that was reverse transcribed from an RNA. cDNA exists in both single-stranded and double-stranded forms and in both natural and engineered forms.

The polymerase chain reaction (PCR) is a method widely used to make millions to billions of copies of a specific DNA sample rapidly, allowing scientists to amplify a very small sample of DNA sufficiently to enable detailed study. PCR was invented in 1983 by American biochemist Kary Mullis at Cetus Corporation. Mullis and biochemist Michael Smith, who had developed other essential ways of manipulating DNA, were jointly awarded the Nobel Prize in Chemistry in 1993.

A reverse transcriptase (RT) is an enzyme used to convert RNA genome to DNA, a process termed reverse transcription. Reverse transcriptases are used by viruses such as HIV and hepatitis B to replicate their genomes, by retrotransposon mobile genetic elements to proliferate within the host genome, and by eukaryotic cells to extend the telomeres at the ends of their linear chromosomes. Contrary to a widely held belief, the process does not violate the flows of genetic information as described by the classical central dogma, as transfers of information from RNA to DNA are explicitly held possible.

A transposable element is a nucleic acid sequence in DNA that can change its position within a genome, sometimes creating or reversing mutations and altering the cell's genetic identity and genome size. Transposition often results in duplication of the same genetic material. In the human genome, L1 and Alu elements are two examples. Barbara McClintock's discovery of them earned her a Nobel Prize in 1983. Its importance in personalized medicine is becoming increasingly relevant, as well as gaining more attention in data analytics given the difficulty of analysis in very high dimensional spaces.
Molecular evolution describes how inherited DNA and/or RNA change over evolutionary time, and the consequences of this for proteins and other components of cells and organisms. Molecular evolution is the basis of phylogenetic approaches to describing the tree of life. Molecular evolution overlaps with population genetics, especially on shorter timescales. Topics in molecular evolution include the origins of new genes, the genetic nature of complex traits, the genetic basis of adaptation and speciation, the evolution of development, and patterns and processes underlying genomic changes during evolution.
Protein engineering is the process of developing useful or valuable proteins through the design and production of unnatural polypeptides, often by altering amino acid sequences found in nature. It is a young discipline, with much research taking place into the understanding of protein folding and recognition for protein design principles. It has been used to improve the function of many enzymes for industrial catalysis. It is also a product and services market, with an estimated value of $168 billion by 2017.
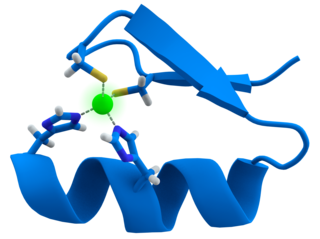
A zinc finger is a small protein structural motif that is characterized by the coordination of one or more zinc ions (Zn2+) which stabilizes the fold. It was originally coined to describe the finger-like appearance of a hypothesized structure from the African clawed frog (Xenopus laevis) transcription factor IIIA. However, it has been found to encompass a wide variety of differing protein structures in eukaryotic cells. Xenopus laevis TFIIIA was originally demonstrated to contain zinc and require the metal for function in 1983, the first such reported zinc requirement for a gene regulatory protein followed soon thereafter by the Krüppel factor in Drosophila. It often appears as a metal-binding domain in multi-domain proteins.
Site-directed mutagenesis is a molecular biology method that is used to make specific and intentional mutating changes to the DNA sequence of a gene and any gene products. Also called site-specific mutagenesis or oligonucleotide-directed mutagenesis, it is used for investigating the structure and biological activity of DNA, RNA, and protein molecules, and for protein engineering.

In molecular biology, a library is a collection of genetic material fragments that are stored and propagated in a population of microbes through the process of molecular cloning. There are different types of DNA libraries, including cDNA libraries, genomic libraries and randomized mutant libraries. DNA library technology is a mainstay of current molecular biology, genetic engineering, and protein engineering, and the applications of these libraries depend on the source of the original DNA fragments. There are differences in the cloning vectors and techniques used in library preparation, but in general each DNA fragment is uniquely inserted into a cloning vector and the pool of recombinant DNA molecules is then transferred into a population of bacteria or yeast such that each organism contains on average one construct. As the population of organisms is grown in culture, the DNA molecules contained within them are copied and propagated.

DNA sequencing is the process of determining the nucleic acid sequence – the order of nucleotides in DNA. It includes any method or technology that is used to determine the order of the four bases: adenine, guanine, cytosine, and thymine. The advent of rapid DNA sequencing methods has greatly accelerated biological and medical research and discovery.
A random permutation is a random ordering of a set of objects, that is, a permutation-valued random variable. The use of random permutations is often fundamental to fields that use randomized algorithms such as coding theory, cryptography, and simulation. A good example of a random permutation is the shuffling of a deck of cards: this is ideally a random permutation of the 52 cards.

Two-hybrid screening is a molecular biology technique used to discover protein–protein interactions (PPIs) and protein–DNA interactions by testing for physical interactions between two proteins or a single protein and a DNA molecule, respectively.
Coalescent theory is a model of how alleles sampled from a population may have originated from a common ancestor. In the simplest case, coalescent theory assumes no recombination, no natural selection, and no gene flow or population structure, meaning that each variant is equally likely to have been passed from one generation to the next. The model looks backward in time, merging alleles into a single ancestral copy according to a random process in coalescence events. Under this model, the expected time between successive coalescence events increases almost exponentially back in time. Variance in the model comes from both the random passing of alleles from one generation to the next, and the random occurrence of mutations in these alleles.

DNA shuffling, also known as molecular breeding, is an in vitro random recombination method to generate mutant genes for directed evolution and to enable a rapid increase in DNA library size. Three procedures for accomplishing DNA shuffling are molecular breeding which relies on homologous recombination or the similarity of the DNA sequences, restriction enzymes which rely on common restriction sites, and nonhomologous random recombination which requires the use of hairpins. In all of these techniques, the parent genes are fragmented and then recombined.
Exon shuffling is a molecular mechanism for the formation of new genes. It is a process through which two or more exons from different genes can be brought together ectopically, or the same exon can be duplicated, to create a new exon-intron structure. There are different mechanisms through which exon shuffling occurs: transposon mediated exon shuffling, crossover during sexual recombination of parental genomes and illegitimate recombination.
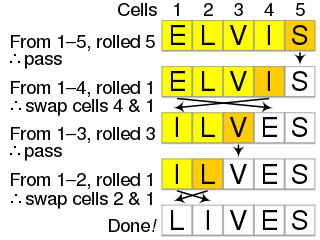
The Fisher–Yates shuffle is an algorithm for shuffling a finite sequence. The algorithm takes a list of all the elements of the sequence, and continually determines the next element in the shuffled sequence by randomly drawing an element from the list until no elements remain. The algorithm produces an unbiased permutation: every permutation is equally likely. The modern version of the algorithm takes time proportional to the number of items being shuffled and shuffles them in place.
Multiple displacement amplification (MDA) is a DNA amplification technique. This method can rapidly amplify minute amounts of DNA samples to a reasonable quantity for genomic analysis. The reaction starts by annealing random hexamer primers to the template: DNA synthesis is carried out by a high fidelity enzyme, preferentially Φ29 DNA polymerase. Compared with conventional PCR amplification techniques, MDA does not employ sequence-specific primers but amplifies all DNA, generates larger-sized products with a lower error frequency, and works at a constant temperature. MDA has been actively used in whole genome amplification (WGA) and is a promising method for application to single cell genome sequencing and sequencing-based genetic studies.

Molecular cloning is a set of experimental methods in molecular biology that are used to assemble recombinant DNA molecules and to direct their replication within host organisms. The use of the word cloning refers to the fact that the method involves the replication of one molecule to produce a population of cells with identical DNA molecules. Molecular cloning generally uses DNA sequences from two different organisms: the species that is the source of the DNA to be cloned, and the species that will serve as the living host for replication of the recombinant DNA. Molecular cloning methods are central to many contemporary areas of modern biology and medicine.

Ligation is the joining of two nucleic acid fragments through the action of an enzyme. It is an essential laboratory procedure in the molecular cloning of DNA, whereby DNA fragments are joined to create recombinant DNA molecules (such as when a foreign DNA fragment is inserted into a plasmid). The ends of DNA fragments are joined by the formation of phosphodiester bonds between the 3'-hydroxyl of one DNA terminus with the 5'-phosphoryl of another. RNA may also be ligated similarly. A co-factor is generally involved in the reaction, and this is usually ATP or NAD+. Eukaryotic cells ligases belong to ATP type, and NAD+ - dependent are found in bacteria (e.g. E. coli).

Duplex sequencing is a library preparation and analysis method for next-generation sequencing (NGS) platforms that employs random tagging of double-stranded DNA to detect mutations with higher accuracy and lower error rates.
References
- ↑ Coco, Wayne M.; Levinson, William E.; Crist, Michael J.; Hektor, Harm J.; Darzins, Aldis; Pienkos, Philip T.; Squires, Charles H.; Monticello, Daniel J. (31 March 2001). "DNA shuffling method for generating highly recombined genes and evolved enzymes". Nature Biotechnology. 19 (4): 354–359. doi:10.1038/86744. PMID 11283594. S2CID 35360374.
| | This biochemistry article is a stub. You can help Wikipedia by expanding it. |
| | This molecular biology article is a stub. You can help Wikipedia by expanding it. |