
In computer science, binary search, also known as half-interval search, logarithmic search, or binary chop, is a search algorithm that finds the position of a target value within a sorted array. Binary search compares the target value to the middle element of the array. If they are not equal, the half in which the target cannot lie is eliminated and the search continues on the remaining half, again taking the middle element to compare to the target value, and repeating this until the target value is found. If the search ends with the remaining half being empty, the target is not in the array.

In computer science, heapsort is a comparison-based sorting algorithm which can be thought of as "an implementation of selection sort using the right data structure." Like selection sort, heapsort divides its input into a sorted and an unsorted region, and it iteratively shrinks the unsorted region by extracting the largest element from it and inserting it into the sorted region. Unlike selection sort, heapsort does not waste time with a linear-time scan of the unsorted region; rather, heap sort maintains the unsorted region in a heap data structure to efficiently find the largest element in each step.

In computer science, a suffix tree is a compressed trie containing all the suffixes of the given text as their keys and positions in the text as their values. Suffix trees allow particularly fast implementations of many important string operations.
In computer science, a disjoint-set data structure, also called a union–find data structure or merge–find set, is a data structure that stores a collection of disjoint (non-overlapping) sets. Equivalently, it stores a partition of a set into disjoint subsets. It provides operations for adding new sets, merging sets, and finding a representative member of a set. The last operation makes it possible to find out efficiently if any two elements are in the same or different sets.
In computer science, a fusion tree is a type of tree data structure that implements an associative array on w-bit integers on a finite universe, where each of the input integers has size less than 2w and is non-negative. When operating on a collection of n key–value pairs, it uses O(n) space and performs searches in O(logwn) time, which is asymptotically faster than a traditional self-balancing binary search tree, and also better than the van Emde Boas tree for large values of w. It achieves this speed by using certain constant-time operations that can be done on a machine word. Fusion trees were invented in 1990 by Michael Fredman and Dan Willard.
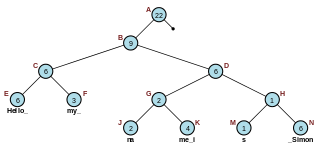
In computer programming, a rope, or cord, is a data structure composed of smaller strings that is used to efficiently store and manipulate a very long string. For example, a text editing program may use a rope to represent the text being edited, so that operations such as insertion, deletion, and random access can be done efficiently.
In computer science, a suffix array is a sorted array of all suffixes of a string. It is a data structure used in, among others, full-text indices, data-compression algorithms, and the field of bibliometrics.
A B+ tree is an m-ary tree with a variable but often large number of children per node. A B+ tree consists of a root, internal nodes and leaves. The root may be either a leaf or a node with two or more children.
In graph theory and computer science, the lowest common ancestor (LCA) of two nodes v and w in a tree or directed acyclic graph (DAG) T is the lowest node that has both v and w as descendants, where we define each node to be a descendant of itself.
In computer science, a succinct data structure is a data structure which uses an amount of space that is "close" to the information-theoretic lower bound, but still allows for efficient query operations. The concept was originally introduced by Jacobson to encode bit vectors, (unlabeled) trees, and planar graphs. Unlike general lossless data compression algorithms, succinct data structures retain the ability to use them in-place, without decompressing them first. A related notion is that of a compressed data structure, insofar as the size of the stored or encoded data similarly depends upon the specific content of the data itself.

In computer science, a Cartesian tree is a binary tree derived from a sequence of distinct numbers. To construct the Cartesian tree, set its root to be the minimum number in the sequence, and recursively construct its left and right subtrees from the subsequences before and after this number. It is uniquely defined as a min-heap whose symmetric (in-order) traversal returns the original sequence.
In computer science, the all nearest smaller values problem is the following task: for each position in a sequence of numbers, search among the previous positions for the last position that contains a smaller value. This problem can be solved efficiently both by parallel and non-parallel algorithms: Berkman, Schieber & Vishkin (1993), who first identified the procedure as a useful subroutine for other parallel programs, developed efficient algorithms to solve it in the Parallel Random Access Machine model; it may also be solved in linear time on a non-parallel computer using a stack-based algorithm. Later researchers have studied algorithms to solve it in other models of parallel computation.

A Fenwick tree or binary indexed tree(BIT) is a data structure that can efficiently update values and calculate prefix sums in an array of values.

In graph algorithms, the widest path problem is the problem of finding a path between two designated vertices in a weighted graph, maximizing the weight of the minimum-weight edge in the path. The widest path problem is also known as the maximum capacity path problem. It is possible to adapt most shortest path algorithms to compute widest paths, by modifying them to use the bottleneck distance instead of path length. However, in many cases even faster algorithms are possible.
In computer science, the range query problem consists of efficiently answering several queries regarding a given interval of elements within an array. For example, a common task, known as range minimum query, is finding the smallest value inside a given range within a list of numbers.
In graph theory and theoretical computer science, the level ancestor problem is the problem of preprocessing a given rooted tree T into a data structure that can determine the ancestor of a given node at a given distance from the root of the tree.
In computer science, the longest common prefix array is an auxiliary data structure to the suffix array. It stores the lengths of the longest common prefixes (LCPs) between all pairs of consecutive suffixes in a sorted suffix array.
In data structures, the range mode query problem asks to build a data structure on some input data to efficiently answer queries asking for the mode of any consecutive subset of the input.
In computer science, a Range Query Tree, or RQT, is a term for referring to a data structure that is used for performing range queries and updates on an underlying array, which is treated as the leaves of the tree. RQTs are, in principle, complete binary trees with a static structure, where each node stores the result of applying a fixed binary operation to a range of the tree's leaves.
In computer science, a generalized suffix array (GSA) is a suffix array containing all suffixes for a set of strings. Given the set of strings of total length , it is a lexicographically sorted array of all suffixes of each string in . It is primarily used in bioinformatics and string processing.

![Example of Cartesian trees for A = [0,5,2,5,4,3,1,6,3]. Notice that the first and third tree have the same layout, so there are exactly two pre-computed sets of queries in the table on the left. Example of Cartesian Trees.png](http://upload.wikimedia.org/wikipedia/commons/thumb/6/69/Example_of_Cartesian_Trees.png/220px-Example_of_Cartesian_Trees.png)