Related Research Articles

Artificial neural networks (ANNs), usually simply called neural networks (NNs), are computing systems inspired by the biological neural networks that constitute animal brains.

Reinforcement learning (RL) is an area of machine learning concerned with how intelligent agents ought to take actions in an environment in order to maximize the notion of cumulative reward. Reinforcement learning is one of three basic machine learning paradigms, alongside supervised learning and unsupervised learning.
In machine learning, early stopping is a form of regularization used to avoid overfitting when training a learner with an iterative method, such as gradient descent. Such methods update the learner so as to make it better fit the training data with each iteration. Up to a point, this improves the learner's performance on data outside of the training set. Past that point, however, improving the learner's fit to the training data comes at the expense of increased generalization error. Early stopping rules provide guidance as to how many iterations can be run before the learner begins to over-fit. Early stopping rules have been employed in many different machine learning methods, with varying amounts of theoretical foundation.
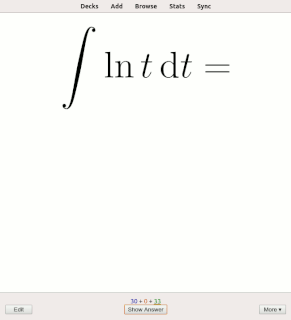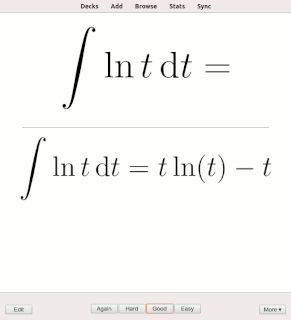
Rote learning is a memorization technique based on repetition. The method rests on the premise that the recall of repeated material becomes faster the more one repeats it. Some of the alternatives to rote learning include meaningful learning, associative learning, spaced repetition and active learning.
Machine learning (ML) is a field of inquiry devoted to understanding and building methods that 'learn', that is, methods that leverage data to improve performance on some set of tasks. It is seen as a part of artificial intelligence. Machine learning algorithms build a model based on sample data, known as training data, in order to make predictions or decisions without being explicitly programmed to do so. Machine learning algorithms are used in a wide variety of applications, such as in medicine, email filtering, speech recognition, and computer vision, where it is difficult or unfeasible to develop conventional algorithms to perform the needed tasks.

A brain–computer interface (BCI), sometimes called a brain–machine interface (BMI), is a direct communication pathway between the brain's electrical activity and an external device, most commonly a computer or robotic limb. BCIs are often directed at researching, mapping, assisting, augmenting, or repairing human cognitive or sensory-motor functions. Implementations of BCIs range from non-invasive and partially invasive to invasive, based on how close electrodes get to brain tissue.

CORDIC, also known as Volder's algorithm, or: Digit-by-digit methodCircular CORDIC, Linear CORDIC, Hyperbolic CORDIC, and Generalized Hyperbolic CORDIC, is a simple and efficient algorithm to calculate trigonometric functions, hyperbolic functions, square roots, multiplications, divisions, and exponentials and logarithms with arbitrary base, typically converging with one digit per iteration. CORDIC is therefore also an example of digit-by-digit algorithms. CORDIC and closely related methods known as pseudo-multiplication and pseudo-division or factor combining are commonly used when no hardware multiplier is available, as the only operations it requires are additions, subtractions, bitshift and lookup tables. As such, they all belong to the class of shift-and-add algorithms. In computer science, CORDIC is often used to implement floating-point arithmetic when the target platform lacks hardware multiply for cost or space reasons.

Iterative reconstruction refers to iterative algorithms used to reconstruct 2D and 3D images in certain imaging techniques. For example, in computed tomography an image must be reconstructed from projections of an object. Here, iterative reconstruction techniques are usually a better, but computationally more expensive alternative to the common filtered back projection (FBP) method, which directly calculates the image in a single reconstruction step. In recent research works, scientists have shown that extremely fast computations and massive parallelism is possible for iterative reconstruction, which makes iterative reconstruction practical for commercialization.
Stochastic gradient descent is an iterative method for optimizing an objective function with suitable smoothness properties. It can be regarded as a stochastic approximation of gradient descent optimization, since it replaces the actual gradient by an estimate thereof. Especially in high-dimensional optimization problems this reduces the very high computational burden, achieving faster iterations in trade for a lower convergence rate.
k-means clustering is a method of vector quantization, originally from signal processing, that aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as a prototype of the cluster. This results in a partitioning of the data space into Voronoi cells. k-means clustering minimizes within-cluster variances, but not regular Euclidean distances, which would be the more difficult Weber problem: the mean optimizes squared errors, whereas only the geometric median minimizes Euclidean distances. For instance, better Euclidean solutions can be found using k-medians and k-medoids.
Iterative Learning Control (ILC) is a method of tracking control for systems that work in a repetitive mode. Examples of systems that operate in a repetitive manner include robot arm manipulators, chemical batch processes and reliability testing rigs. In each of these tasks the system is required to perform the same action over and over again with high precision. This action is represented by the objective of accurately tracking a chosen reference signal on a finite time interval.
Compressed sensing is a signal processing technique for efficiently acquiring and reconstructing a signal, by finding solutions to underdetermined linear systems. This is based on the principle that, through optimization, the sparsity of a signal can be exploited to recover it from far fewer samples than required by the Nyquist–Shannon sampling theorem. There are two conditions under which recovery is possible. The first one is sparsity, which requires the signal to be sparse in some domain. The second one is incoherence, which is applied through the isometric property, which is sufficient for sparse signals.
In statistical signal processing, the goal of spectral density estimation (SDE) is to estimate the spectral density of a random signal from a sequence of time samples of the signal. Intuitively speaking, the spectral density characterizes the frequency content of the signal. One purpose of estimating the spectral density is to detect any periodicities in the data, by observing peaks at the frequencies corresponding to these periodicities.
The Bregman method is an iterative algorithm to solve certain convex optimization problems involving regularization. The original version is due to Lev M. Bregman, who published it in 1967.

A Penrose tiling is an example of an aperiodic tiling. Here, a tiling is a covering of the plane by non-overlapping polygons or other shapes, and aperiodic means that shifting any tiling with these shapes by any finite distance, without rotation, cannot produce the same tiling. However, despite their lack of translational symmetry, Penrose tilings may have both reflection symmetry and fivefold rotational symmetry. Penrose tilings are named after mathematician and physicist Roger Penrose, who investigated them in the 1970s.
In machine learning the random subspace method, also called attribute bagging or feature bagging, is an ensemble learning method that attempts to reduce the correlation between estimators in an ensemble by training them on random samples of features instead of the entire feature set.

Deep learning is part of a broader family of machine learning methods based on artificial neural networks with representation learning. Learning can be supervised, semi-supervised or unsupervised.
Coordinate descent is an optimization algorithm that successively minimizes along coordinate directions to find the minimum of a function. At each iteration, the algorithm determines a coordinate or coordinate block via a coordinate selection rule, then exactly or inexactly minimizes over the corresponding coordinate hyperplane while fixing all other coordinates or coordinate blocks. A line search along the coordinate direction can be performed at the current iterate to determine the appropriate step size. Coordinate descent is applicable in both differentiable and derivative-free contexts.
Sparse coding is a representation learning method which aims at finding a sparse representation of the input data in the form of a linear combination of basic elements as well as those basic elements themselves. These elements are called atoms and they compose a dictionary. Atoms in the dictionary are not required to be orthogonal, and they may be an over-complete spanning set. This problem setup also allows the dimensionality of the signals being represented to be higher than the one of the signals being observed. The above two properties lead to having seemingly redundant atoms that allow multiple representations of the same signal but also provide an improvement in sparsity and flexibility of the representation.
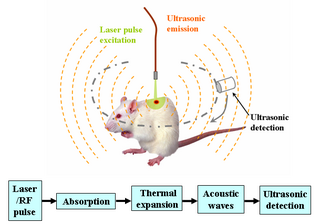
Deep learning in photoacoustic imaging combines the hybrid imaging modality of photoacoustic imaging (PA) with the rapidly evolving field of deep learning. Photoacoustic imaging is based on the photoacoustic effect, in which optical absorption causes a rise in temperature, which causes a subsequent rise in pressure via thermo-elastic expansion. This pressure rise propagates through the tissue and is sensed via ultrasonic transducers. Due to the proportionality between the optical absorption, the rise in temperature, and the rise in pressure, the ultrasound pressure wave signal can be used to quantify the original optical energy deposition within the tissue.
References
- ↑ "An Overview on Repetitive Control --- what are the issues and where does it lead to?" (PDF). Yutaka Yamamoto. Archived from the original (PDF) on 6 October 2011. Retrieved 22 August 2011.
- ↑ "Iterative Learning Control, Delays and Repetitive Control" (PDF). David Owens and Jari Hätönen*. Retrieved 22 August 2011.
- Wang Y.; Gao F.; Doyle III, F.J. (2009). "Survey on iterative learning control, repetitive control, and run-to-run control". Journal of Process Control. 19 (10): 1589–1600. doi:10.1016/j.jprocont.2009.09.006.
| | This article relating to education is a stub. You can help Wikipedia by expanding it. |