
In speech science and phonetics, a formant is the broad spectral maximum that results from an acoustic resonance of the human vocal tract. In acoustics, a formant is usually defined as a broad peak, or local maximum, in the spectrum. For harmonic sounds, with this definition, the formant frequency is sometimes taken as that of the harmonic that is most augmented by a resonance. The difference between these two definitions resides in whether "formants" characterise the production mechanisms of a sound or the produced sound itself. In practice, the frequency of a spectral peak differs slightly from the associated resonance frequency, except when, by luck, harmonics are aligned with the resonance frequency, or when the sound source is mostly non-harmonic, as in whispering and vocal fry.
In linguistics, a liquid consonant or simply liquid is any of a class of consonants that consists of rhotics and voiced lateral approximants, which are also sometimes described as "R-like sounds" and "L-like sounds". The word liquid seems to be a calque of the Ancient Greek word ὑγρός, initially used by grammarian Dionysius Thrax to describe Greek sonorants.
A vowel is a syllabic speech sound pronounced without any stricture in the vocal tract. Vowels are one of the two principal classes of speech sounds, the other being the consonant. Vowels vary in quality, in loudness and also in quantity (length). They are usually voiced and are closely involved in prosodic variation such as tone, intonation and stress.
Linear predictive coding (LPC) is a method used mostly in audio signal processing and speech processing for representing the spectral envelope of a digital signal of speech in compressed form, using the information of a linear predictive model.

An overtone is any resonant frequency above the fundamental frequency of a sound. In other words, overtones are all pitches higher than the lowest pitch within an individual sound; the fundamental is the lowest pitch. While the fundamental is usually heard most prominently, overtones are actually present in any pitch except a true sine wave. The relative volume or amplitude of various overtone partials is one of the key identifying features of timbre, or the individual characteristic of a sound.
Speech synthesis is the artificial production of human speech. A computer system used for this purpose is called a speech synthesizer, and can be implemented in software or hardware products. A text-to-speech (TTS) system converts normal language text into speech; other systems render symbolic linguistic representations like phonetic transcriptions into speech. The reverse process is speech recognition.
Dida is a dialect cluster of the Kru family spoken in Ivory Coast.

In music, timbre, also known as tone color or tone quality, is the perceived sound quality of a musical note, sound or tone. Timbre distinguishes different types of sound production, such as choir voices and musical instruments. It also enables listeners to distinguish different instruments in the same category.

Pitch is a perceptual property that allows sounds to be ordered on a frequency-related scale, or more commonly, pitch is the quality that makes it possible to judge sounds as "higher" and "lower" in the sense associated with musical melodies. Pitch is a major auditory attribute of musical tones, along with duration, loudness, and timbre.

Silbo Gomero, also known as el silbo, is a whistled register of Spanish used by inhabitants of La Gomera in the Canary Islands, historically used to communicate across the deep ravines and narrow valleys that radiate through the island. It enabled messages to be exchanged over a distance of up to five kilometres. Due to its loudness, Silbo Gomero is generally used for public communication. Messages conveyed range from event invitations to public information advisories. A speaker of Silbo Gomero is sometimes called a silbador ("whistler").
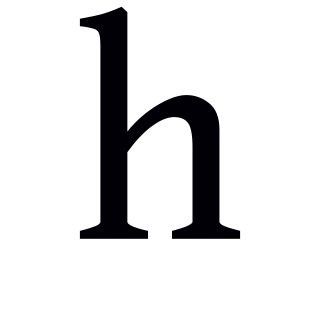
The voiceless glottal fricative, sometimes called voiceless glottal transition or the aspirate, is a type of sound used in some spoken languages that patterns like a fricative or approximant consonant phonologically, but often lacks the usual phonetic characteristics of a consonant. The symbol in the International Phonetic Alphabet that represents this sound is ⟨h⟩. However, has been described as a voiceless phonation because in many languages, it lacks the place and manner of articulation of a prototypical consonant, as well as the height and backness of a prototypical vowel:
[h and ɦ] have been described as voiceless or breathy voiced counterparts of the vowels that follow them [but] the shape of the vocal tract [...] is often simply that of the surrounding sounds. [...] Accordingly, in such cases it is more appropriate to regard h and ɦ as segments that have only a laryngeal specification, and are unmarked for all other features. There are other languages [such as Hebrew and Arabic] which show a more definite displacement of the formant frequencies for h, suggesting it has a [glottal] constriction associated with its production.
Acoustic phonetics is a subfield of phonetics, which deals with acoustic aspects of speech sounds. Acoustic phonetics investigates time domain features such as the mean squared amplitude of a waveform, its duration, its fundamental frequency, or frequency domain features such as the frequency spectrum, or even combined spectrotemporal features and the relationship of these properties to other branches of phonetics, and to abstract linguistic concepts such as phonemes, phrases, or utterances.

The open-mid central rounded vowel, or low-mid central rounded vowel, is a vowel sound, used in some spoken languages. The symbol in the International Phonetic Alphabet that represents this sound is ⟨ɞ⟩, and the equivalent X-SAMPA symbol is 3\. The symbol is called closed reversed epsilon. It was added to the IPA in 1993; before that, this vowel was transcribed ⟨ɔ̈⟩.
In linguistics, prosody is the study of elements of speech including intonation, stress, rhythm and loudness. These elements occur simultaneously with individual phonetic segments: vowels and consonants. Often, prosody specifically refers to such elements that extend across more than one phonetic segment. These elements are known as suprasegmentals.
Signal processing is an electrical engineering subfield that focuses on analysing, modifying, and synthesizing signals such as sound, images, and scientific measurements. For example, with a filter g, an inverse filterh is one such that the sequence of applying g then h to a signal results in the original signal. Software or electronic inverse filters are often used to compensate for the effect of unwanted environmental filtering of signals.

Kenneth Noble Stevens was the Clarence J. LeBel Professor of Electrical Engineering and Computer Science, and professor of health sciences and technology at the research laboratory of electronics at MIT. Stevens was head of the speech communication group in MIT's research laboratory of electronics (RLE), and was one of the world's leading scientists in acoustic phonetics.
In linguistics, speech synthesis, and music, the pitch contour of a sound is a function or curve that tracks the perceived pitch of the sound over time. Pitch contour may include multiple sounds utilizing many pitches, and can relate the frequency function at one point in time to the frequency function at a later point.

A vowel diagram or vowel chart is a schematic arrangement of the vowels. Depending on the particular language being discussed, it can take the form of a triangle or a quadrilateral. Vertical position on the diagram denotes the vowel closeness, with close vowels at the top of the diagram, and horizontal position denotes the vowel backness, with front vowels at the left of the diagram. Vowels are unique in that their main features do not contain differences in voicing, manner, or place (articulators). Vowels differ only in the position of the tongue when voiced. The tongue moves vertically and horizontally within the oral cavity. Vowels are produced with at least a part of their vocal tract obstructed.
The quantal theory of speech is a phonetic answer to one of the fundamental questions of phonology, specifically: if each language community is free to arbitrarily select a system of phonemes or segments, then why are the phoneme inventories of different languages so similar? For example, almost all languages have the stop consonants /p/, /t/, /k/, and almost all have the vowels /a/, /i/, and /u/. Other phonemes differ considerably among languages, but not nearly as much as they would if each language were free to choose arbitrarily.
The phonology of Māori is typical for a Polynesian language, with its phonetic inventory being one of the smallest in the world with considerable variation in realisation. The Māori language retains the Proto-Polynesian syllable structure: (C)V(V ), with no closed syllables. The stress pattern is unpredictable, unlike in many other Polynesian languages.