
In mathematics, a self-similar object is exactly or approximately similar to a part of itself. Many objects in the real world, such as coastlines, are statistically self-similar: parts of them show the same statistical properties at many scales. Self-similarity is a typical property of artificial fractals. Scale invariance is an exact form of self-similarity where at any magnification there is a smaller piece of the object that is similar to the whole. For instance, a side of the Koch snowflake is both symmetrical and scale-invariant; it can be continually magnified 3x without changing shape. The non-trivial similarity evident in fractals is distinguished by their fine structure, or detail on arbitrarily small scales. As a counterexample, whereas any portion of a straight line may resemble the whole, further detail is not revealed.

A complex system is a system composed of many components which may interact with each other. Examples of complex systems are Earth's global climate, organisms, the human brain, infrastructure such as power grid, transportation or communication systems, social and economic organizations, an ecosystem, a living cell, and ultimately the entire universe.

Two geometrical objects are called similar if they both have the same shape, or one has the same shape as the mirror image of the other. More precisely, one can be obtained from the other by uniformly scaling, possibly with additional translation, rotation and reflection. This means that either object can be rescaled, repositioned, and reflected, so as to coincide precisely with the other object. If two objects are similar, each is congruent to the result of a particular uniform scaling of the other. A modern and novel perspective of similarity is to consider geometrical objects similar if one appears congruent to the other when zoomed in or out at some level.
The New England Complex Systems Institute (NECSI) is a small American research institution dedicated to advancing the study of complex systems. NECSI offers educational programs, conducts research, and hosts the International Conference on Complex Systems. It was founded in 1996 and is located in Cambridge, Massachusetts.
In mathematical folklore, the "no free lunch" (NFL) theorem of David Wolpert and William Macready appears in the 1997 "No Free Lunch Theorems for Optimization". Wolpert had previously derived no free lunch theorems for machine learning.

In computational complexity and optimization the no free lunch theorem is a result that states that for certain types of mathematical problems, the computational cost of finding a solution, averaged over all problems in the class, is the same for any solution method. No solution therefore offers a "short cut". In computing, there are circumstances in which the outputs of all procedures solving a particular type of problem are statistically identical. A colourful way of describing such a circumstance, introduced by David Wolpert and William G. Macready in connection with the problems of search and optimization, is to say that there is no free lunch. Wolpert had previously derived no free lunch theorems for machine learning. Before Wolpert's article was published, Cullen Schaffer independently proved a restricted version of one of Wolpert's theorems and used it to critique the current state of machine learning research on the problem of induction.
A complex adaptive system is a system in which a perfect understanding of the individual parts does not automatically convey a perfect understanding of the whole system's behavior. The study of complex adaptive systems, a subset of nonlinear dynamical systems, is highly interdisciplinary and blends insights from the natural and social sciences to develop system-level models and insights that allow for heterogeneous agents, phase transition, and emergent behavior.

In graph theory and network analysis, indicators of centrality identify the most important vertices within a graph. Applications include identifying the most influential person(s) in a social network, key infrastructure nodes in the Internet or urban networks, and super-spreaders of disease. Centrality concepts were first developed in social network analysis, and many of the terms used to measure centrality reflect their sociological origin. They should not be confused with node influence metrics, which seek to quantify the influence of every node in the network.
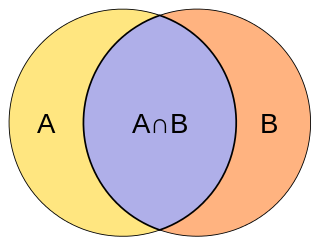
The Jaccard index, also known as Intersection over Union and the Jaccard similarity coefficient, is a statistic used for comparing the similarity and diversity of sample sets. The Jaccard coefficient measures similarity between finite sample sets, and is defined as the size of the intersection divided by the size of the union of the sample sets:
Complexity measure / measure of complexity may refer to any measure defined in various branches of complexity theory, specifically:
Complexity theory and organizations, also called complexity strategy or complex adaptive organizations, is the use of the study of complexity systems in the field of strategic management and organizational studies.
Nearest neighbor search (NNS), as a form of proximity search, is the optimization problem of finding the point in a given set that is closest to a given point. Closeness is typically expressed in terms of a dissimilarity function: the less similar the objects, the larger the function values. Formally, the nearest-neighbor (NN) search problem is defined as follows: given a set S of points in a space M and a query point q ∈ M, find the closest point in S to q. Donald Knuth in vol. 3 of The Art of Computer Programming (1973) called it the post-office problem, referring to an application of assigning to a residence the nearest post office. A direct generalization of this problem is a k-NN search, where we need to find the k closest points.

Yaneer Bar-Yam is an American physicist, systems scientist, and founding president of the New England Complex Systems Institute.
In ecology and biology, the Bray–Curtis dissimilarity, named after J. Roger Bray and John T. Curtis, is a statistic used to quantify the compositional dissimilarity between two different sites, based on counts at each site. As defined by Bray and Curtis, the index of dissimilarity is:
Effective complexity is a measure of complexity defined in a 2003 paper by Murray Gell-Mann and Seth Lloyd that attempts to measure the amount of non-random information in a system. It has been criticised as being dependent on the subjective decisions made as to which parts of the information in the system are to be discounted as random.
Logical depth is a measure of complexity devised by Charles H. Bennett based on the computational complexity of an algorithm that can recreate a given piece of information. It differs from Kolmogorov complexity in that it considers the computation time of the algorithm with the shortest length, rather than its length.
Argument from analogy is a special type of inductive argument, whereby perceived similarities are used as a basis to infer some further similarity that has yet to be observed. Analogical reasoning is one of the most common methods by which human beings attempt to understand the world and make decisions. When a person has a bad experience with a product and decides not to buy anything further from the producer, this is often a case of analogical reasoning. It is also implicit in much of science; for instance, experiments on laboratory rats typically proceed on the basis that some physiological similarities between rats and humans entails some further similarity.
Carlos Gershenson is a Mexican researcher at the Universidad Nacional Autónoma de México. His academic interests include self-organizing systems, complexity, and artificial life.
