The Semantic Web is an extension of the World Wide Web through standards set by the World Wide Web Consortium (W3C). The goal of the Semantic Web is to make Internet data machine-readable. To enable the encoding of semantics with the data, technologies such as Resource Description Framework (RDF) and Web Ontology Language (OWL) are used. These technologies are used to formally represent metadata. For example, ontology can describe concepts, relationships between entities, and categories of things. These embedded semantics offer significant advantages such as reasoning over data and operating with heterogeneous data sources.
In computer science and information science, an ontology encompasses a representation, formal naming and definition of the categories, properties and relations between the concepts, data and entities that substantiate one, many or all domains of discourse. More simply, an ontology is a way of showing the properties of a subject area and how they are related, by defining a set of concepts and categories that represent the subject.
A conceptual schema is a high-level description of informational needs underlying the design of a database. It typically includes only the main concepts and the main relationships among them. Typically this is a first-cut model, with insufficient detail to build an actual database. This level describes the structure of the whole database for a group of users. The conceptual model is also known as the data model that can be used to describe the conceptual schema when a database system is implemented. It hides the internal details of physical storage and targets on describing entities, datatypes, relationships and constraints.
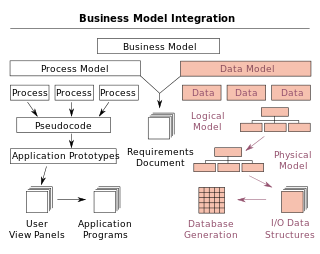
A data model is an abstract model that organizes elements of data and standardizes how they relate to one another and to the properties of real-world entities. For instance, a data model may specify that the data element representing a car be composed of a number of other elements which, in turn, represent the color and size of the car and define its owner.
The Suggested Upper Merged Ontology (SUMO) is an upper ontology intended as a foundation ontology for a variety of computer information processing systems. SUMO defines a hierarchy of classes and related rules and relationships. These are expressed in a version of the language SUO-KIF which has a LISP-like syntax. A mapping from WordNet synsets to SUMO has been defined. Initially, SUMO was focused on meta-level concepts, and thereby would lead naturally to a categorization scheme for encyclopedias. It has now been considerably expanded to include a mid-level ontology and dozens of domain ontologies.
The Web Ontology Language (OWL) is a family of knowledge representation languages for authoring ontologies. Ontologies are a formal way to describe taxonomies and classification networks, essentially defining the structure of knowledge for various domains: the nouns representing classes of objects and the verbs representing relations between the objects. Ontologies resemble class hierarchies in object-oriented programming but there are several critical differences. Class hierarchies are meant to represent structures used in source code that evolve fairly slowly whereas ontologies are meant to represent information on the Internet and are expected to be evolving almost constantly. Similarly, ontologies are typically far more flexible as they are meant to represent information on the Internet coming from all sorts of heterogeneous data sources. Class hierarchies on the other hand are meant to be fairly static and rely on far less diverse and more structured sources of data such as corporate databases.
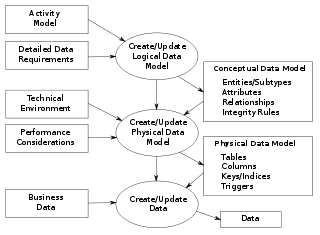
Data modeling in software engineering is the process of creating a data model for an information system by applying certain formal techniques.
A conceptual model is a representation of a system, made of the composition of concepts which are used to help people know, understand, or simulate a subject the model represents. It is also a set of concepts. In contrast, physical models are physical objects; for example, a toy model which may be assembled, and may be made to work like the object it represents.
SPARQL is an RDF query language—that is, a semantic query language for databases—able to retrieve and manipulate data stored in Resource Description Framework (RDF) format. It was made a standard by the RDF Data Access Working Group (DAWG) of the World Wide Web Consortium, and is recognized as one of the key technologies of the semantic web. On 15 January 2008, SPARQL 1.0 was acknowledged by W3C as an official recommendation, and SPARQL 1.1 in March, 2013.
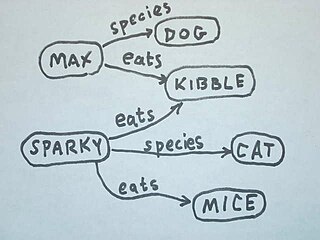
The ultimate goal of semantic technology is to help machines understand data. To enable the encoding of semantics with the data, well-known technologies are RDF and OWL. These technologies formally represent the meaning involved in information. For example, ontology can describe concepts, relationships between things, and categories of things. These embedded semantics with the data offer significant advantages such as reasoning over data and dealing with heterogeneous data sources.
Ontology alignment, or ontology matching, is the process of determining correspondences between concepts in ontologies. A set of correspondences is also called an alignment. The phrase takes on a slightly different meaning, in computer science, cognitive science or philosophy.
The terms schema matching and mapping are often used interchangeably for a database process. For this article, we differentiate the two as follows: Schema matching is the process of identifying that two objects are semantically related while mapping refers to the transformations between the objects. For example, in the two schemas DB1.Student and DB2.Grad-Student ; possible matches would be: DB1.Student ≈ DB2.Grad-Student; DB1.SSN = DB2.ID etc. and possible transformations or mappings would be: DB1.Marks to DB2.Grades.

An ontology chart is a type of chart used in semiotics and software engineering to illustrate an ontology.
Amit Sheth is a computer scientist at Wright State University in Dayton, Ohio. He is the Lexis Nexis Ohio Eminent Scholar for Advanced Data Management and Analysis. Up to October 2018, Sheth's work had been cited by over 41,000 publications. He has an h-index of 100, which puts him among the top 100 computer scientists with the highest h-index. Prior to founding the Kno.e.sis Center, he served as the director of the Large Scale Distributed Information Systems Lab at the University of Georgia in Athens, Georgia.
BORO is an approach to developing ontological or semantic models for large complex operational applications that consists of a top ontology as well as a process for constructing the ontology. It was originally developed as a method for mining ontologies from multiple legacy systems – as the first stage in an architectural transformation or software modernization. It has also been used to enable semantic interoperability between legacy systems. It is described in detail in. It is the analysis method used in the development and maintenance of the U.S. Department of Defense Architecture Framework (DoDAF) Meta Model (DM2), where a data modeling working group of over 350 members was able to systematically resolve a broad spectrum of knowledge representation issues.
Semantic matching is a technique used in computer science to identify information which is semantically related.
The Semantic Sensor Web (SSW) is a marriage of sensor and Semantic Web technologies. The encoding of sensor descriptions and sensor observation data with Semantic Web languages enables more expressive representation, advanced access, and formal analysis of sensor resources. The SSW annotates sensor data with spatial, temporal, and thematic semantic metadata. This technique builds on current standardization efforts within the Open Geospatial Consortium's Sensor Web Enablement (SWE) and extends them with Semantic Web technologies to provide enhanced descriptions and access to sensor data.
Knowledge extraction is the creation of knowledge from structured and unstructured sources. The resulting knowledge needs to be in a machine-readable and machine-interpretable format and must represent knowledge in a manner that facilitates inferencing. Although it is methodically similar to information extraction (NLP) and ETL, the main criteria is that the extraction result goes beyond the creation of structured information or the transformation into a relational schema. It requires either the reuse of existing formal knowledge or the generation of a schema based on the source data.
GermaNet is a semantic network for the German language. It relates nouns, verbs, and adjectives semantically by grouping lexical units that express the same concept into synsets and by defining semantic relations between these synsets. GermaNet is free for academic use, after signing a license. GermaNet has much in common with the English WordNet and can be viewed as an on-line thesaurus or a light-weight ontology. GermaNet has been developed and maintained at the University of Tübingen since 1997 within the research group for General and Computational Linguistics. It has been integrated into the EuroWordNet, a multilingual lexical-semantic database.
Semantic heterogeneity is when database schema or datasets for the same domain are developed by independent parties, resulting in differences in meaning and interpretation of data values. Beyond structured data, the problem of semantic heterogeneity is compounded due to the flexibility of semi-structured data and various tagging methods applied to documents or unstructured data. Semantic heterogeneity is one of the more important sources of differences in heterogeneous datasets.