A semantic grid is an approach to grid computing in which information, computing resources and services are described using the semantic data model. In this model, the data and metadata are expressed through facts (small sentences), becoming directly understandable for humans. This makes it easier for resources to be discovered and combined automatically to create virtual organizations (VOs). The descriptions constitute metadata and are typically represented using the technologies of the Semantic Web, such as the Resource Description Framework (RDF).
Like the Semantic Web, the semantic grid can be defined as "an extension of the current grid in which information and services are given well-defined meaning, better enabling computers and people to work in cooperation."[1]
This notion of the semantic grid was first articulated in the context of e-Science, observing that such an approach is necessary to achieve a high degree of easy-to-use and seamless automation, enabling flexible collaborations and computations on a global scale.
The use of semantic web and other knowledge technologies in grid applications are sometimes described as the knowledge grid. Semantic grid extends this by also applying these technologies within the grid middleware.
Some semantic grid activities are coordinated through the Semantic Grid Research Group of the Global Grid Forum.
Notes
↑ De Roure, David (2005). "The Semantic Grid: Past, Present and Future". The Semantic Web: Research and Applications. Lecture Notes in Computer Science. Vol.3532. p.726. doi:10.1007/11431053_50. ISBN978-3-540-26124-7. S2CID8114038.
The Dublin Core, also known as the Dublin Core Metadata Element Set (DCMES), is a set of fifteen "core" elements (properties) for describing resources. This fifteen-element Dublin Core has been formally standardized as ISO 15836, ANSI/NISO Z39.85, and IETF RFC 5013. The Dublin Core Metadata Initiative (DCMI), which formulates the Dublin Core, is a project of the Association for Information Science and Technology (ASIS&T), a non-profit organization. The core properties are part of a larger set of DCMI Metadata Terms. "Dublin Core" is also used as an adjective for Dublin Core metadata, a style of metadata that draws on multiple Resource Description Framework (RDF) vocabularies, packaged and constrained in Dublin Core application profiles.
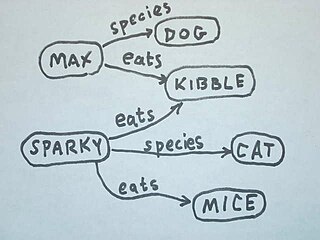
A semantic network, or frame network is a knowledge base that represents semantic relations between concepts in a network. This is often used as a form of knowledge representation. It is a directed or undirected graph consisting of vertices, which represent concepts, and edges, which represent semantic relations between concepts, mapping or connecting semantic fields. A semantic network may be instantiated as, for example, a graph database or a concept map. Typical standardized semantic networks are expressed as semantic triples.
The Semantic Web, sometimes known as Web 3.0, is an extension of the World Wide Web through standards set by the World Wide Web Consortium (W3C). The goal of the Semantic Web is to make Internet data machine-readable.
Grid computing is the use of widely distributed computer resources to reach a common goal. A computing grid can be thought of as a distributed system with non-interactive workloads that involve many files. Grid computing is distinguished from conventional high-performance computing systems such as cluster computing in that grid computers have each node set to perform a different task/application. Grid computers also tend to be more heterogeneous and geographically dispersed than cluster computers. Although a single grid can be dedicated to a particular application, commonly a grid is used for a variety of purposes. Grids are often constructed with general-purpose grid middleware software libraries. Grid sizes can be quite large.
In computer science and information science, an ontology encompasses a representation, formal naming, and definition of the categories, properties, and relations between the concepts, data, and entities that substantiate one, many, or all domains of discourse. More simply, an ontology is a way of showing the properties of a subject area and how they are related, by defining a set of concepts and categories that represent the subject.
A modeling language is any artificial language that can be used to express information or knowledge or systems in a structure that is defined by a consistent set of rules. The rules are used for interpretation of the meaning of components in the structure.
Fedora is a digital asset management (DAM) content repository architecture upon which institutional repositories, digital archives, and digital library systems might be built. Fedora is the underlying architecture for a digital repository, and is not a complete management, indexing, discovery, and delivery application. It is a modular architecture built on the principle that interoperability and extensibility are best achieved by the integration of data, interfaces, and mechanisms as clearly defined modules.
The ultimate goal of semantic technology is to help machines understand data. To enable the encoding of semantics with the data, well-known technologies are RDF and OWL. These technologies formally represent the meaning involved in information. For example, ontology can describe concepts, relationships between things, and categories of things. These embedded semantics with the data offer significant advantages such as reasoning over data and dealing with heterogeneous data sources.
Data integration involves combining data residing in different sources and providing users with a unified view of them. This process becomes significant in a variety of situations, which include both commercial and scientific domains. Data integration appears with increasing frequency as the volume and the need to share existing data explodes. It has become the focus of extensive theoretical work, and numerous open problems remain unsolved. Data integration encourages collaboration between internal as well as external users. The data being integrated must be received from a heterogeneous database system and transformed to a single coherent data store that provides synchronous data across a network of files for clients. A common use of data integration is in data mining when analyzing and extracting information from existing databases that can be useful for Business information.
European Grid Infrastructure (EGI) is a series of efforts to provide access to high-throughput computing resources across Europe using grid computing techniques. The EGI links centres in different European countries to support international research in many scientific disciplines. Following a series of research projects such as DataGrid and Enabling Grids for E-sciencE, the EGI Foundation was formed in 2010 to sustain the services of EGI.
The AgMES initiative was developed by the Food and Agriculture Organization (FAO) of the United Nations and aims to encompass issues of semantic standards in the domain of agriculture with respect to description, resource discovery, interoperability and data exchange for different types of information resources.
In computer science, the Semantic Desktop is a collective term for ideas related to changing a computer's user interface and data handling capabilities so that data are more easily shared between different applications or tasks and so that data that once could not be automatically processed by a computer could be. It also encompasses some ideas about being able to share information automatically between different people. This concept is very much related to the Semantic Web, but is distinct insofar as its main concern is the personal use of information.
Distributed GIS refers to GI Systems that do not have all of the system components in the same physical location. This could be the processing, the database, the rendering or the user interface. It represents a special case of distributed computing, with examples of distributed systems including Internet GIS, Web GIS, and Mobile GIS. Distribution of resources provides corporate and enterprise-based models for GIS. Distributed GIS permits a shared services model, including data fusion based on Open Geospatial Consortium (OGC) web services. Distributed GIS technology enables modern online mapping systems, Location-based services (LBS), web-based GIS and numerous map-enabled applications. Other applications include transportation, logistics, utilities, farm / agricultural information systems, real-time environmental information systems and the analysis of the movement of people. In terms of data, the concept has been extended to include volunteered geographical information. Distributed processing allows improvements to the performance of spatial analysis through the use of techniques such as parallel processing.
Amit Sheth is a computer scientist at University of South Carolina in Columbia, South Carolina. He is the founding Director of the Artificial Intelligence Institute, and a Professor of Computer Science and Engineering. From 2007 to June 2019, he was the Lexis Nexis Ohio Eminent Scholar, director of the Ohio Center of Excellence in Knowledge-enabled Computing, and a Professor of Computer Science at Wright State University. Sheth's work has been cited by over 48,800 publications. He has an h-index of 106, which puts him among the top 100 computer scientists with the highest h-index. Prior to founding the Kno.e.sis Center, he served as the director of the Large Scale Distributed Information Systems Lab at the University of Georgia in Athens, Georgia.
Metadata is "data that provides information about other data", but not the content of the data, such as the text of a message or the image itself. There are many distinct types of metadata, including:
In computer science, information science and systems engineering, ontology engineering is a field which studies the methods and methodologies for building ontologies, which encompasses a representation, formal naming and definition of the categories, properties and relations between the concepts, data and entities. In a broader sense, this field also includes a knowledge construction of the domain using formal ontology representations such as OWL/RDF. A large-scale representation of abstract concepts such as actions, time, physical objects and beliefs would be an example of ontological engineering. Ontology engineering is one of the areas of applied ontology, and can be seen as an application of philosophical ontology. Core ideas and objectives of ontology engineering are also central in conceptual modeling.
The Semantic Sensor Web (SSW) is a marriage of sensor web and semantic Web technologies. The encoding of sensor descriptions and sensor observation data with Semantic Web languages enables more expressive representation, advanced access, and formal analysis of sensor resources. The SSW annotates sensor data with spatial, temporal, and thematic semantic metadata. This technique builds on current standardization efforts within the Open Geospatial Consortium's Sensor Web Enablement (SWE) and extends them with Semantic Web technologies to provide enhanced descriptions and access to sensor data.
The Handle System is the Corporation for National Research Initiatives's proprietary registry assigning persistent identifiers, or handles, to information resources, and for resolving "those handles into the information necessary to locate, access, and otherwise make use of the resources".
Knowledge extraction is the creation of knowledge from structured and unstructured sources. The resulting knowledge needs to be in a machine-readable and machine-interpretable format and must represent knowledge in a manner that facilitates inferencing. Although it is methodically similar to information extraction (NLP) and ETL, the main criterion is that the extraction result goes beyond the creation of structured information or the transformation into a relational schema. It requires either the reuse of existing formal knowledge or the generation of a schema based on the source data.
In natural language processing, linguistics, and neighboring fields, Linguistic Linked Open Data (LLOD) describes a method and an interdisciplinary community concerned with creating, sharing, and (re-)using language resources in accordance with Linked Data principles. The Linguistic Linked Open Data Cloud was conceived and is being maintained by the Open Linguistics Working Group (OWLG) of the Open Knowledge Foundation, but has been a point of focal activity for several W3C community groups, research projects, and infrastructure efforts since then.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.