
In computational complexity theory, a computational problem H is called NP-hard if, for every problem L which can be solved in non-deterministic polynomial-time, there is a polynomial-time reduction from L to H. That is, assuming a solution for H takes 1 unit time, H's solution can be used to solve L in polynomial time. As a consequence, finding a polynomial time algorithm to solve a single NP-hard problem would give polynomial time algorithms for all the problems in the complexity class NP. As it is suspected, but unproven, that P≠NP, it is unlikely that any polynomial-time algorithms for NP-hard problems exist.

In computer science, the clique problem is the computational problem of finding cliques in a graph. It has several different formulations depending on which cliques, and what information about the cliques, should be found. Common formulations of the clique problem include finding a maximum clique, finding a maximum weight clique in a weighted graph, listing all maximal cliques, and solving the decision problem of testing whether a graph contains a clique larger than a given size.

In graph theory, an independent set, stable set, coclique or anticlique is a set of vertices in a graph, no two of which are adjacent. That is, it is a set of vertices such that for every two vertices in , there is no edge connecting the two. Equivalently, each edge in the graph has at most one endpoint in . A set is independent if and only if it is a clique in the graph's complement. The size of an independent set is the number of vertices it contains. Independent sets have also been called "internally stable sets", of which "stable set" is a shortening.

In graph theory, a vertex cover of a graph is a set of vertices that includes at least one endpoint of every edge of the graph.
In computer science and operations research, approximation algorithms are efficient algorithms that find approximate solutions to optimization problems with provable guarantees on the distance of the returned solution to the optimal one. Approximation algorithms naturally arise in the field of theoretical computer science as a consequence of the widely believed P ≠ NP conjecture. Under this conjecture, a wide class of optimization problems cannot be solved exactly in polynomial time. The field of approximation algorithms, therefore, tries to understand how closely it is possible to approximate optimal solutions to such problems in polynomial time. In an overwhelming majority of the cases, the guarantee of such algorithms is a multiplicative one expressed as an approximation ratio or approximation factor i.e., the optimal solution is always guaranteed to be within a (predetermined) multiplicative factor of the returned solution. However, there are also many approximation algorithms that provide an additive guarantee on the quality of the returned solution. A notable example of an approximation algorithm that provides both is the classic approximation algorithm of Lenstra, Shmoys and Tardos for scheduling on unrelated parallel machines.
In computer science, a polynomial-time approximation scheme (PTAS) is a type of approximation algorithm for optimization problems.
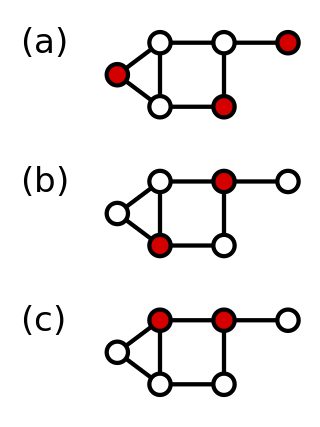
In graph theory, a dominating set for a graph G is a subset D of its vertices, such that any vertex of G is in D, or has a neighbor in D. The domination numberγ(G) is the number of vertices in a smallest dominating set for G.
In the mathematical discipline of graph theory, a feedback vertex set (FVS) of a graph is a set of vertices whose removal leaves a graph without cycles. Equivalently, each FVS contains at least one vertex of any cycle in the graph. The feedback vertex set number of a graph is the size of a smallest feedback vertex set. The minimum feedback vertex set problem is an NP-complete problem; it was among the first problems shown to be NP-complete. It has wide applications in operating systems, database systems, and VLSI chip design.

In graph theory and graph algorithms, a feedback arc set or feedback edge set in a directed graph is a subset of the edges of the graph that contains at least one edge out of every cycle in the graph. Removing these edges from the graph breaks all of the cycles, producing an acyclic subgraph of the given graph, often called a directed acyclic graph. A feedback arc set with the fewest possible edges is a minimum feedback arc set and its removal leaves a maximum acyclic subgraph; weighted versions of these optimization problems are also used. If a feedback arc set is minimal, meaning that removing any edge from it produces a subset that is not a feedback arc set, then it has an additional property: reversing all of its edges, rather than removing them, produces a directed acyclic graph.
Set packing is a classical NP-complete problem in computational complexity theory and combinatorics, and was one of Karp's 21 NP-complete problems. Suppose one has a finite set S and a list of subsets of S. Then, the set packing problem asks if some k subsets in the list are pairwise disjoint.
In computational complexity theory, the class APX is the set of NP optimization problems that allow polynomial-time approximation algorithms with approximation ratio bounded by a constant. In simple terms, problems in this class have efficient algorithms that can find an answer within some fixed multiplicative factor of the optimal answer.
In graph theory, a cut is a partition of the vertices of a graph into two disjoint subsets. Any cut determines a cut-set, the set of edges that have one endpoint in each subset of the partition. These edges are said to cross the cut. In a connected graph, each cut-set determines a unique cut, and in some cases cuts are identified with their cut-sets rather than with their vertex partitions.
MAX-3SAT is a problem in the computational complexity subfield of computer science. It generalises the Boolean satisfiability problem (SAT) which is a decision problem considered in complexity theory. It is defined as:
In number theory and computer science, the partition problem, or number partitioning, is the task of deciding whether a given multiset S of positive integers can be partitioned into two subsets S1 and S2 such that the sum of the numbers in S1 equals the sum of the numbers in S2. Although the partition problem is NP-complete, there is a pseudo-polynomial time dynamic programming solution, and there are heuristics that solve the problem in many instances, either optimally or approximately. For this reason, it has been called "the easiest hard problem".
In mathematics, a graph partition is the reduction of a graph to a smaller graph by partitioning its set of nodes into mutually exclusive groups. Edges of the original graph that cross between the groups will produce edges in the partitioned graph. If the number of resulting edges is small compared to the original graph, then the partitioned graph may be better suited for analysis and problem-solving than the original. Finding a partition that simplifies graph analysis is a hard problem, but one that has applications to scientific computing, VLSI circuit design, and task scheduling in multiprocessor computers, among others. Recently, the graph partition problem has gained importance due to its application for clustering and detection of cliques in social, pathological and biological networks. For a survey on recent trends in computational methods and applications see Buluc et al. (2013). Two common examples of graph partitioning are minimum cut and maximum cut problems.
In graph theory, a clique cover or partition into cliques of a given undirected graph is a collection of cliques that cover the whole graph. A minimum clique cover is a clique cover that uses as few cliques as possible. The minimum k for which a clique cover exists is called the clique cover number of the given graph.
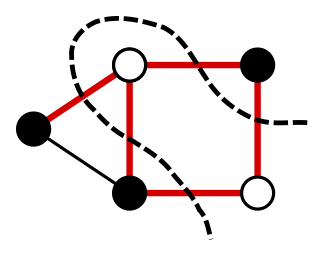
In a graph, a maximum cut is a cut whose size is at least the size of any other cut. That is, it is a partition of the graph's vertices into two complementary sets S and T, such that the number of edges between S and T is as large as possible. Finding such a cut is known as the max-cut problem.

In the mathematical discipline of graph theory, a 3-dimensional matching is a generalization of bipartite matching to 3-partite hypergraphs, which consist of hyperedges each of which contains 3 vertices.
In mathematics, the minimum k-cut is a combinatorial optimization problem that requires finding a set of edges whose removal would partition the graph to at least k connected components. These edges are referred to as k-cut. The goal is to find the minimum-weight k-cut. This partitioning can have applications in VLSI design, data-mining, finite elements and communication in parallel computing.
