
In probability theory, a normaldistribution is a type of continuous probability distribution for a real-valued random variable. The general form of its probability density function is

In probability theory, a log-normal distribution is a continuous probability distribution of a random variable whose logarithm is normally distributed. Thus, if the random variable X is log-normally distributed, then Y = ln(X) has a normal distribution. Equivalently, if Y has a normal distribution, then the exponential function of Y, X = exp(Y), has a log-normal distribution. A random variable which is log-normally distributed takes only positive real values. It is a convenient and useful model for measurements in exact and engineering sciences, as well as medicine, economics and other topics.
In statistics, maximum likelihood estimation (MLE) is a method of estimating the parameters of an assumed probability distribution, given some observed data. This is achieved by maximizing a likelihood function so that, under the assumed statistical model, the observed data is most probable. The point in the parameter space that maximizes the likelihood function is called the maximum likelihood estimate. The logic of maximum likelihood is both intuitive and flexible, and as such the method has become a dominant means of statistical inference.

A geometric Brownian motion (GBM) is a continuous-time stochastic process in which the logarithm of the randomly varying quantity follows a Brownian motion with drift. It is an important example of stochastic processes satisfying a stochastic differential equation (SDE); in particular, it is used in mathematical finance to model stock prices in the Black–Scholes model.
In mathematics, a Gaussian function, often simply referred to as a Gaussian, is a function of the form
In probability theory and statistics, a Gaussian process is a stochastic process, such that every finite collection of those random variables has a multivariate normal distribution, i.e. every finite linear combination of them is normally distributed. The distribution of a Gaussian process is the joint distribution of all those random variables, and as such, it is a distribution over functions with a continuous domain, e.g. time or space.
In probability and statistics, an exponential family is a parametric set of probability distributions of a certain form, specified below. This special form is chosen for mathematical convenience, based on some useful algebraic properties, as well as for generality, as exponential families are in a sense very natural sets of distributions to consider. The term exponential class is sometimes used in place of "exponential family", or the older term Koopman–Darmois family. The terms "distribution" and "family" are often used loosely: properly, an exponential family is a set of distributions, where the specific distribution varies with the parameter; however, a parametric family of distributions is often referred to as "a distribution", and the set of all exponential families is sometimes loosely referred to as "the" exponential family. They are distinct because they possess a variety of desirable properties, most importantly the existence of a sufficient statistic.
In numerical analysis and computational statistics, rejection sampling is a basic technique used to generate observations from a distribution. It is also commonly called the acceptance-rejection method or "accept-reject algorithm" and is a type of exact simulation method. The method works for any distribution in with a density.
In statistics, sometimes the covariance matrix of a multivariate random variable is not known but has to be estimated. Estimation of covariance matrices then deals with the question of how to approximate the actual covariance matrix on the basis of a sample from the multivariate distribution. Simple cases, where observations are complete, can be dealt with by using the sample covariance matrix. The sample covariance matrix (SCM) is an unbiased and efficient estimator of the covariance matrix if the space of covariance matrices is viewed as an extrinsic convex cone in Rp×p; however, measured using the intrinsic geometry of positive-definite matrices, the SCM is a biased and inefficient estimator. In addition, if the random variable has normal distribution, the sample covariance matrix has Wishart distribution and a slightly differently scaled version of it is the maximum likelihood estimate. Cases involving missing data require deeper considerations. Another issue is the robustness to outliers, to which sample covariance matrices are highly sensitive.
In probability theory and statistics, the generalized extreme value (GEV) distribution is a family of continuous probability distributions developed within extreme value theory to combine the Gumbel, Fréchet and Weibull families also known as type I, II and III extreme value distributions. By the extreme value theorem the GEV distribution is the only possible limit distribution of properly normalized maxima of a sequence of independent and identically distributed random variables. Note that a limit distribution needs to exist, which requires regularity conditions on the tail of the distribution. Despite this, the GEV distribution is often used as an approximation to model the maxima of long (finite) sequences of random variables.
Differential entropy is a concept in information theory that began as an attempt by Shannon to extend the idea of (Shannon) entropy, a measure of average surprisal of a random variable, to continuous probability distributions. Unfortunately, Shannon did not derive this formula, and rather just assumed it was the correct continuous analogue of discrete entropy, but it is not. The actual continuous version of discrete entropy is the limiting density of discrete points (LDDP). Differential entropy is commonly encountered in the literature, but it is a limiting case of the LDDP, and one that loses its fundamental association with discrete entropy.
In probability theory and computer science, a log probability is simply a logarithm of a probability. The use of log probabilities means representing probabilities on a logarithmic scale, instead of the standard unit interval.

The folded normal distribution is a probability distribution related to the normal distribution. Given a normally distributed random variable X with mean μ and variance σ2, the random variable Y = |X| has a folded normal distribution. Such a case may be encountered if only the magnitude of some variable is recorded, but not its sign. The distribution is called "folded" because probability mass to the left of x = 0 is folded over by taking the absolute value. In the physics of heat conduction, the folded normal distribution is a fundamental solution of the heat equation on the half space; it corresponds to having a perfect insulator on a hyperplane through the origin.
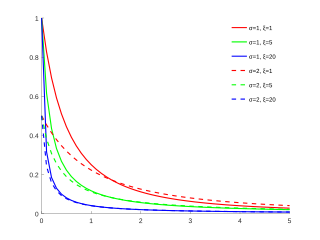
In statistics, the generalized Pareto distribution (GPD) is a family of continuous probability distributions. It is often used to model the tails of another distribution. It is specified by three parameters: location , scale , and shape . Sometimes it is specified by only scale and shape and sometimes only by its shape parameter. Some references give the shape parameter as .

The Nakagami distribution or the Nakagami-m distribution is a probability distribution related to the gamma distribution. The family of Nakagami distributions has two parameters: a shape parameter and a second parameter controlling spread .
A ratio distribution is a probability distribution constructed as the distribution of the ratio of random variables having two other known distributions. Given two random variables X and Y, the distribution of the random variable Z that is formed as the ratio Z = X/Y is a ratio distribution.
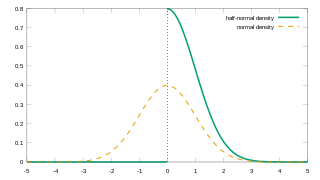
In probability theory and statistics, the half-normal distribution is a special case of the folded normal distribution.
In probability, statistics, economics, and actuarial science, the Benini distribution is a continuous probability distribution that is a statistical size distribution often applied to model incomes, severity of claims or losses in actuarial applications, and other economic data. Its tail behavior decays faster than a power law, but not as fast as an exponential. This distribution was introduced by Rodolfo Benini in 1905. Somewhat later than Benini's original work, the distribution has been independently discovered or discussed by a number of authors.

In probability theory, a log-Cauchy distribution is a probability distribution of a random variable whose logarithm is distributed in accordance with a Cauchy distribution. If X is a random variable with a Cauchy distribution, then Y = exp(X) has a log-Cauchy distribution; likewise, if Y has a log-Cauchy distribution, then X = log(Y) has a Cauchy distribution.
In probability theory and statistics, the discrete Weibull distribution is the discrete variant of the Weibull distribution. It was first described by Nakagawa and Osaki in 1975.


