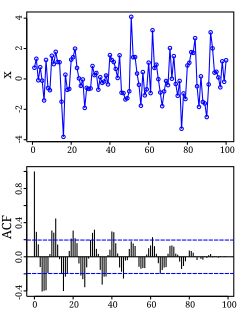
Autocorrelation, also known as serial correlation, is the correlation of a signal with a delayed copy of itself as a function of delay. Informally, it is the similarity between observations as a function of the time lag between them. The analysis of autocorrelation is a mathematical tool for finding repeating patterns, such as the presence of a periodic signal obscured by noise, or identifying the missing fundamental frequency in a signal implied by its harmonic frequencies. It is often used in signal processing for analyzing functions or series of values, such as time domain signals.

In mathematics, the discrete Fourier transform (DFT) converts a finite sequence of equally-spaced samples of a function into a same-length sequence of equally-spaced samples of the discrete-time Fourier transform (DTFT), which is a complex-valued function of frequency. The interval at which the DTFT is sampled is the reciprocal of the duration of the input sequence. An inverse DFT is a Fourier series, using the DTFT samples as coefficients of complex sinusoids at the corresponding DTFT frequencies. It has the same sample-values as the original input sequence. The DFT is therefore said to be a frequency domain representation of the original input sequence. If the original sequence spans all the non-zero values of a function, its DTFT is continuous, and the DFT provides discrete samples of one cycle. If the original sequence is one cycle of a periodic function, the DFT provides all the non-zero values of one DTFT cycle.
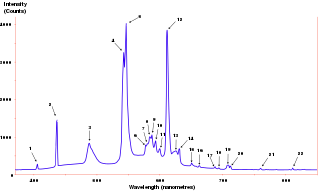
The power spectrum of a time series describes the distribution of power into frequency components composing that signal. According to Fourier analysis, any physical signal can be decomposed into a number of discrete frequencies, or a spectrum of frequencies over a continuous range. The statistical average of a certain signal or sort of signal as analyzed in terms of its frequency content, is called its spectrum.

In signal processing and statistics, a window function is a mathematical function that is zero-valued outside of some chosen interval, normally symmetric around the middle of the interval, usually near a maximum in the middle, and usually tapering away from the middle. Mathematically, when another function or waveform/data-sequence is "multiplied" by a window function, the product is also zero-valued outside the interval: all that is left is the part where they overlap, the "view through the window". Equivalently, and in actual practice, the segment of data within the window is first isolated, and then only that data is multiplied by the window function values. Thus, tapering, not segmentation, is the main purpose of window functions.
In signal processing, a periodogram is an estimate of the spectral density of a signal. The term was coined by Arthur Schuster in 1898. Today, the periodogram is a component of more sophisticated methods. It is the most common tool for examining the amplitude vs frequency characteristics of FIR filters and window functions. FFT spectrum analyzers are also implemented as a time-sequence of periodograms.
Welch's method, named after Peter D. Welch, is an approach for spectral density estimation. It is used in physics, engineering, and applied mathematics for estimating the power of a signal at different frequencies. The method is based on the concept of using periodogram spectrum estimates, which are the result of converting a signal from the time domain to the frequency domain. Welch's method is an improvement on the standard periodogram spectrum estimating method and on Bartlett's method, in that it reduces noise in the estimated power spectra in exchange for reducing the frequency resolution. Due to the noise caused by imperfect and finite data, the noise reduction from Welch's method is often desired.
In mathematics, the discrete-time Fourier transform (DTFT) is a form of Fourier analysis that is applicable to a sequence of values.
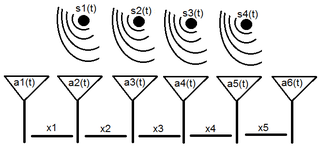
Array processing is a wide area of research in the field of signal processing that extends from the simplest form of 1 dimensional line arrays to 2 and 3 dimensional array geometries. Array structure can be defined as a set of sensors that are spatially separated, e.g. radio antenna and seismic arrays. The sensors used for a specific problem may vary widely, for example microphones, accelerometers and telescopes. However, many similarities exist, the most fundamental of which may be an assumption of wave propagation. Wave propagation means there is a systemic relationship between the signal received on spatially separated sensors. By creating a physical model of the wave propagation, or in machine learning applications a training data set, the relationships between the signals received on spatially separated sensors can be leveraged for many applications.
In statistics, econometrics and signal processing, an autoregressive (AR) model is a representation of a type of random process; as such, it is used to describe certain time-varying processes in nature, economics, etc. The autoregressive model specifies that the output variable depends linearly on its own previous values and on a stochastic term ; thus the model is in the form of a stochastic difference equation. Together with the moving-average (MA) model, it is a special case and key component of the more general autoregressive–moving-average (ARMA) and autoregressive integrated moving average (ARIMA) models of time series, which have a more complicated stochastic structure; it is also a special case of the vector autoregressive model (VAR), which consists of a system of more than one interlocking stochastic difference equation in more than one evolving random variable.
A cyclostationary process is a signal having statistical properties that vary cyclically with time. A cyclostationary process can be viewed as multiple interleaved stationary processes. For example, the maximum daily temperature in New York City can be modeled as a cyclostationary process: the maximum temperature on July 21 is statistically different from the temperature on December 20; however, it is a reasonable approximation that the temperature on December 20 of different years has identical statistics. Thus, we can view the random process composed of daily maximum temperatures as 365 interleaved stationary processes, each of which takes on a new value once per year.
In applied mathematics, the Wiener–Khinchin theorem, also known as the Wiener–Khintchine theorem and sometimes as the Wiener–Khinchin–Einstein theorem or the Khinchin–Kolmogorov theorem, states that the autocorrelation function of a wide-sense-stationary random process has a spectral decomposition given by the power spectrum of that process.
The autocorrelation technique is a method for estimating the dominating frequency in a complex signal, as well as its variance. Specifically, it calculates the first two moments of the power spectrum, namely the mean and variance. It is also known as the pulse-pair algorithm in radar theory.
Geophysical survey is the systematic collection of geophysical data for spatial studies. Detection and analysis of the geophysical signals forms the core of Geophysical signal processing. The magnetic and gravitational fields emanating from the Earth's interior hold essential information concerning seismic activities and the internal structure. Hence, detection and analysis of the electric and Magnetic fields is very crucial. As the Electromagnetic and gravitational waves are multi-dimensional signals, all the 1-D transformation techniques can be extended for the analysis of these signals as well. Hence this article also discusses multi-dimensional signal processing techniques.

In signal processing, the multitaper method is a technique developed by David J. Thomson to estimate the power spectrum SX of a stationary ergodic finite-variance random process X, given a finite contiguous realization of X as data. It is one of a number of approaches to spectral density estimation.
In statistical signal processing, the goal of spectral density estimation (SDE) is to estimate the spectral density of a random signal from a sequence of time samples of the signal. Intuitively speaking, the spectral density characterizes the frequency content of the signal. One purpose of estimating the spectral density is to detect any periodicities in the data, by observing peaks at the frequencies corresponding to these periodicities.
Least-squares spectral analysis (LSSA) is a method of estimating a frequency spectrum, based on a least squares fit of sinusoids to data samples, similar to Fourier analysis. Fourier analysis, the most used spectral method in science, generally boosts long-periodic noise in long gapped records; LSSA mitigates such problems.
In computer networks, self-similarity is a feature of network data transfer dynamics. When modeling network data dynamics the traditional time series models, such as an autoregressive moving average model, are not appropriate. This is because these models only provide a finite number of parameters in the model and thus interaction in a finite time window, but the network data usually have a long-range dependent temporal structure. A self-similar process is one way of modeling network data dynamics with such a long range correlation. This article defines and describes network data transfer dynamics in the context of a self-similar process. Properties of the process are shown and methods are given for graphing and estimating parameters modeling the self-similarity of network data.
In mathematical analysis and applications, multidimensional transforms are used to analyze the frequency content of signals in a domain of two or more dimensions.
Many concepts in one–dimensional signal processing are similar to concepts in multidimensional signal processing. However, many familiar one–dimensional procedures do not readily generalize to the multidimensional case and some important issues associated with multidimensional signals and systems do not appear in the one–dimensional special case.
In statistics, Whittle likelihood is an approximation to the likelihood function of a stationary Gaussian time series. It is named after the mathematician and statistician Peter Whittle, who introduced it in his PhD thesis in 1951. It is commonly utilized in time series analysis and signal processing for parameter estimation and signal detection.

























