
A Markov chain or Markov process is a stochastic model describing a sequence of possible events in which the probability of each event depends only on the state attained in the previous event. Informally, this may be thought of as, "What happens next depends only on the state of affairs now." A countably infinite sequence, in which the chain moves state at discrete time steps, gives a discrete-time Markov chain (DTMC). A continuous-time process is called a continuous-time Markov chain (CTMC). It is named after the Russian mathematician Andrey Markov.
Reinforcement learning (RL) is an interdisciplinary area of machine learning and optimal control concerned with how an intelligent agent ought to take actions in a dynamic environment in order to maximize the cumulative reward. Reinforcement learning is one of three basic machine learning paradigms, alongside supervised learning and unsupervised learning.

In mathematical optimization and decision theory, a loss function or cost function is a function that maps an event or values of one or more variables onto a real number intuitively representing some "cost" associated with the event. An optimization problem seeks to minimize a loss function. An objective function is either a loss function or its opposite, in which case it is to be maximized. The loss function could include terms from several levels of the hierarchy.
A prior probability distribution of an uncertain quantity, often simply called the prior, is its assumed probability distribution before some evidence is taken into account. For example, the prior could be the probability distribution representing the relative proportions of voters who will vote for a particular politician in a future election. The unknown quantity may be a parameter of the model or a latent variable rather than an observable variable.
In statistics, Gibbs sampling or a Gibbs sampler is a Markov chain Monte Carlo (MCMC) algorithm for sampling from a specified multivariate probability distribution when direct sampling from the joint distribution is difficult, but sampling from the conditional distribution is more practical. This sequence can be used to approximate the joint distribution ; to approximate the marginal distribution of one of the variables, or some subset of the variables ; or to compute an integral. Typically, some of the variables correspond to observations whose values are known, and hence do not need to be sampled.
In probability theory, a Lévy process, named after the French mathematician Paul Lévy, is a stochastic process with independent, stationary increments: it represents the motion of a point whose successive displacements are random, in which displacements in pairwise disjoint time intervals are independent, and displacements in different time intervals of the same length have identical probability distributions. A Lévy process may thus be viewed as the continuous-time analog of a random walk.
In mathematics, a Markov decision process (MDP) is a discrete-time stochastic control process. It provides a mathematical framework for modeling decision making in situations where outcomes are partly random and partly under the control of a decision maker. MDPs are useful for studying optimization problems solved via dynamic programming. MDPs were known at least as early as the 1950s; a core body of research on Markov decision processes resulted from Ronald Howard's 1960 book, Dynamic Programming and Markov Processes. They are used in many disciplines, including robotics, automatic control, economics and manufacturing. The name of MDPs comes from the Russian mathematician Andrey Markov as they are an extension of Markov chains.

In probability theory and machine learning, the multi-armed bandit problem is a problem in which a decision maker iteratively selects one of multiple fixed choices when the properties of each choice are only partially known at the time of allocation, and may become better understood as time passes. A fundamental aspect of bandit problems is that choosing an arm does not affect the properties of the arm or other arms.
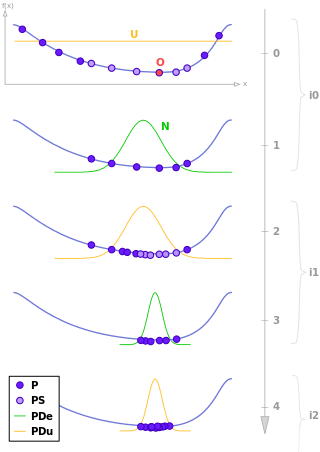
Estimation of distribution algorithms (EDAs), sometimes called probabilistic model-building genetic algorithms (PMBGAs), are stochastic optimization methods that guide the search for the optimum by building and sampling explicit probabilistic models of promising candidate solutions. Optimization is viewed as a series of incremental updates of a probabilistic model, starting with the model encoding an uninformative prior over admissible solutions and ending with the model that generates only the global optima.
A partially observable Markov decision process (POMDP) is a generalization of a Markov decision process (MDP). A POMDP models an agent decision process in which it is assumed that the system dynamics are determined by an MDP, but the agent cannot directly observe the underlying state. Instead, it must maintain a sensor model and the underlying MDP. Unlike the policy function in MDP which maps the underlying states to the actions, POMDP's policy is a mapping from the history of observations to the actions.
Bayesian inference of phylogeny combines the information in the prior and in the data likelihood to create the so-called posterior probability of trees, which is the probability that the tree is correct given the data, the prior and the likelihood model. Bayesian inference was introduced into molecular phylogenetics in the 1990s by three independent groups: Bruce Rannala and Ziheng Yang in Berkeley, Bob Mau in Madison, and Shuying Li in University of Iowa, the last two being PhD students at the time. The approach has become very popular since the release of the MrBayes software in 2001, and is now one of the most popular methods in molecular phylogenetics.
In probability theory, Dirichlet processes are a family of stochastic processes whose realizations are probability distributions. In other words, a Dirichlet process is a probability distribution whose range is itself a set of probability distributions. It is often used in Bayesian inference to describe the prior knowledge about the distribution of random variables—how likely it is that the random variables are distributed according to one or another particular distribution.
The Gittins index is a measure of the reward that can be achieved through a given stochastic process with certain properties, namely: the process has an ultimate termination state and evolves with an option, at each intermediate state, of terminating. Upon terminating at a given state, the reward achieved is the sum of the probabilistic expected rewards associated with every state from the actual terminating state to the ultimate terminal state, inclusive. The index is a real scalar.
In computer science and graph theory, the Canadian traveller problem (CTP) is a generalization of the shortest path problem to graphs that are partially observable. In other words, a "traveller" on a given point on the graph cannot see the full graph, rather only adjacent nodes or a certain "realization restriction."
In probability theory, Robbins' problem of optimal stopping, named after Herbert Robbins, is sometimes referred to as the fourth secretary problem or the problem of minimizing the expected rank with full information.
Let X1, ..., Xn be independent, identically distributed random variables, uniform on [0, 1]. We observe the Xk's sequentially and must stop on exactly one of them. No recall of preceding observations is permitted. What stopping rule minimizes the expected rank of the selected observation, and what is its corresponding value?
Bayesian econometrics is a branch of econometrics which applies Bayesian principles to economic modelling. Bayesianism is based on a degree-of-belief interpretation of probability, as opposed to a relative-frequency interpretation.
In queueing theory, a discipline within the mathematical theory of probability, an M/G/1 queue is a queue model where arrivals are Markovian, service times have a General distribution and there is a single server. The model name is written in Kendall's notation, and is an extension of the M/M/1 queue, where service times must be exponentially distributed. The classic application of the M/G/1 queue is to model performance of a fixed head hard disk.

In probability theory, a log-Cauchy distribution is a probability distribution of a random variable whose logarithm is distributed in accordance with a Cauchy distribution. If X is a random variable with a Cauchy distribution, then Y = exp(X) has a log-Cauchy distribution; likewise, if Y has a log-Cauchy distribution, then X = log(Y) has a Cauchy distribution.
A mixed Poisson distribution is a univariate discrete probability distribution in stochastics. It results from assuming that the conditional distribution of a random variable, given the value of the rate parameter, is a Poisson distribution, and that the rate parameter itself is considered as a random variable. Hence it is a special case of a compound probability distribution. Mixed Poisson distributions can be found in actuarial mathematics as a general approach for the distribution of the number of claims and is also examined as an epidemiological model. It should not be confused with compound Poisson distribution or compound Poisson process.
Integrated nested Laplace approximations (INLA) is a method for approximate Bayesian inference based on Laplace's method. It is designed for a class of models called latent Gaussian models (LGMs), for which it can be a fast and accurate alternative for Markov chain Monte Carlo methods to compute posterior marginal distributions. Due to its relative speed even with large data sets for certain problems and models, INLA has been a popular inference method in applied statistics, in particular spatial statistics, ecology, and epidemiology. It is also possible to combine INLA with a finite element method solution of a stochastic partial differential equation to study e.g. spatial point processes and species distribution models. The INLA method is implemented in the R-INLA R package.












