Related Research Articles
Computational linguistics is an interdisciplinary field concerned with the computational modelling of natural language, as well as the study of appropriate computational approaches to linguistic questions. In general, computational linguistics draws upon linguistics, computer science, artificial intelligence, mathematics, logic, philosophy, cognitive science, cognitive psychology, psycholinguistics, anthropology and neuroscience, among others.

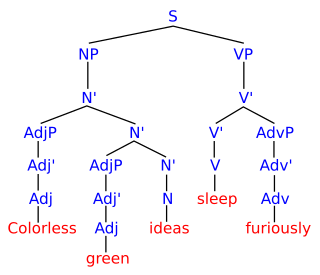
In formal language theory, a context-free grammar (CFG) is a formal grammar whose production rules can be applied to a nonterminal symbol regardless of its context. In particular, in a context-free grammar, each production rule is of the form
In logic, mathematics, computer science, and linguistics, a formal language consists of words whose letters are taken from an alphabet and are well-formed according to a specific set of rules.

Natural language processing (NLP) is an interdisciplinary subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human language, in particular how to program computers to process and analyze large amounts of natural language data. The goal is a computer capable of "understanding" the contents of documents, including the contextual nuances of the language within them. The technology can then accurately extract information and insights contained in the documents as well as categorize and organize the documents themselves.
Corpus linguistics is the study of a language as that language is expressed in its text corpus, its body of "real world" text. Corpus linguistics proposes that a reliable analysis of a language is more feasible with corpora collected in the field—the natural context ("realia") of that language—with minimal experimental interference.
In computer science, Backus–Naur form or Backus normal form (BNF) is a metasyntax notation for context-free grammars, often used to describe the syntax of languages used in computing, such as computer programming languages, document formats, instruction sets and communication protocols. It is applied wherever exact descriptions of languages are needed: for instance, in official language specifications, in manuals, and in textbooks on programming language theory.
In computer science, a compiler-compiler or compiler generator is a programming tool that creates a parser, interpreter, or compiler from some form of formal description of a programming language and machine.
In computer science, lexical analysis, lexing or tokenization is the process of converting a sequence of characters into a sequence of lexical tokens. A program that performs lexical analysis may be termed a lexer, tokenizer, or scanner, although scanner is also a term for the first stage of a lexer. A lexer is generally combined with a parser, which together analyze the syntax of programming languages, web pages, and so forth.
Grammar theory to model symbol strings originated from work in computational linguistics aiming to understand the structure of natural languages. Probabilistic context free grammars (PCFGs) have been applied in probabilistic modeling of RNA structures almost 40 years after they were introduced in computational linguistics.
Parsing, syntax analysis, or syntactic analysis is the process of analyzing a string of symbols, either in natural language, computer languages or data structures, conforming to the rules of a formal grammar. The term parsing comes from Latin pars (orationis), meaning part.
Tree-adjoining grammar (TAG) is a grammar formalism defined by Aravind Joshi. Tree-adjoining grammars are somewhat similar to context-free grammars, but the elementary unit of rewriting is the tree rather than the symbol. Whereas context-free grammars have rules for rewriting symbols as strings of other symbols, tree-adjoining grammars have rules for rewriting the nodes of trees as other trees.
In computer science, an ambiguous grammar is a context-free grammar for which there exists a string that can have more than one leftmost derivation or parse tree. Every non-empty context-free language admits an ambiguous grammar by introducing e.g. a duplicate rule. A language that only admits ambiguous grammars is called an inherently ambiguous language. Deterministic context-free grammars are always unambiguous, and are an important subclass of unambiguous grammars; there are non-deterministic unambiguous grammars, however.
A bigram or digram is a sequence of two adjacent elements from a string of tokens, which are typically letters, syllables, or words. A bigram is an n-gram for n=2.

In linguistics, a treebank is a parsed text corpus that annotates syntactic or semantic sentence structure. The construction of parsed corpora in the early 1990s revolutionized computational linguistics, which benefitted from large-scale empirical data.

Grammar induction is the process in machine learning of learning a formal grammar from a set of observations, thus constructing a model which accounts for the characteristics of the observed objects. More generally, grammatical inference is that branch of machine learning where the instance space consists of discrete combinatorial objects such as strings, trees and graphs.
In computer science, a grammar is informally called a recursive grammar if it contains production rules that are recursive, meaning that expanding a non-terminal according to these rules can eventually lead to a string that includes the same non-terminal again. Otherwise it is called a non-recursive grammar.
In computer programming, a parser combinator is a higher-order function that accepts several parsers as input and returns a new parser as its output. In this context, a parser is a function accepting strings as input and returning some structure as output, typically a parse tree or a set of indices representing locations in the string where parsing stopped successfully. Parser combinators enable a recursive descent parsing strategy that facilitates modular piecewise construction and testing. This parsing technique is called combinatory parsing.
Applicative universal grammar, or AUG, is a universal semantic metalanguage intended for studying the semantic processes in particular languages. This is a linguistic theory that views the formation of phrase structure by analogy to function application in an applicative programming language. Among the innovations in this approach to natural language processing are the ideas of functional superposition and stratified types.
Naomi Sager is an American computational linguistics research scientist. She is a former research professor at New York University, now retired. She is a pioneer in the development of natural language processing for computers.
Universal Dependencies, frequently abbreviated as UD, is an international cooperative project to create treebanks of the world's languages. These treebanks are openly accessible and available. Core applications are automated text processing in the field of natural language processing (NLP) and research into natural language syntax and grammar, especially within linguistic typology. The project's primary aim is to achieve cross-linguistic consistency of annotation, while still permitting language-specific extensions when necessary. The annotation scheme has it roots in three related projects: Stanford Dependencies, Google universal part-of-speech tags, and the Interset interlingua for morphosyntactic tagsets. The UD annotation scheme uses a representation in the form of dependency trees as opposed to a phrase structure trees. At the present time, there are just over 200 treebanks of more than 100 languages available in the UD inventory.
References
- ↑ Cohn, Trevor; Blunsom, Phil (2009). "A Bayesian model of syntax-directed tree to string grammar induction". Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing Volume 1 – EMNLP '09. Vol. 1. Morristown, NJ, USA: Association for Computational Linguistics. pp. 352–361. doi:10.3115/1699510.1699557. ISBN 978-1-932432-59-6. S2CID 2785745.
- ↑ Salkoff, M.; Sager, N. (1967). "The elimination of grammatical restrictions in a string grammar of English". Proceedings of the 1967 conference on Computational linguistics. pp. 1–15. doi:10.3115/991566.991582. S2CID 12583235.
- ↑ Salkoff, Morris (1999). A French-English Grammar: A Contrastive Grammar on Translational Principles. Lingvisticæ Investigationes Supplementa. Vol. 22. p. 12. doi:10.1075/lis.22. ISBN 978-90-272-3131-4.
- ↑ "Programming in Apache Qpid: 2.4.4. Address String Grammar". Red Hat Customer Portal. Retrieved 2019-10-01.
- ↑ "Variable Typing (The GNU Awk User's Guide)". GNU.org. Retrieved 2019-10-01.