Related Research Articles

In computing, a database is an organized collection of data stored and accessed electronically from a computer system. Where databases are more complex they are often developed using formal design and modeling techniques.

In computer science, a data structure is a data organization, management, and storage format that enables efficient access and modification. More precisely, a data structure is a collection of data values, the relationships among them, and the functions or operations that can be applied to the data, i.e., it is an algebraic structure about data.
Multivariate statistics is a subdivision of statistics encompassing the simultaneous observation and analysis of more than one outcome variable. Multivariate statistics concerns understanding the different aims and background of each of the different forms of multivariate analysis, and how they relate to each other. The practical application of multivariate statistics to a particular problem may involve several types of univariate and multivariate analyses in order to understand the relationships between variables and their relevance to the problem being studied.

Data mining is a process of extracting and discovering patterns in large data sets involving methods at the intersection of machine learning, statistics, and database systems. Data mining is an interdisciplinary subfield of computer science and statistics with an overall goal to extract information from a data set and transform the information into a comprehensible structure for further use. Data mining is the analysis step of the "knowledge discovery in databases" process, or KDD. Aside from the raw analysis step, it also involves database and data management aspects, data pre-processing, model and inference considerations, interestingness metrics, complexity considerations, post-processing of discovered structures, visualization, and online updating.
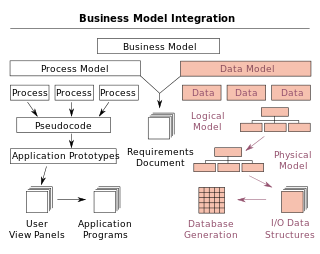
A data model is an abstract model that organizes elements of data and standardizes how they relate to one another and to the properties of real-world entities. For instance, a data model may specify that the data element representing a car be composed of a number of other elements which, in turn, represent the color and size of the car and define its owner.
Software design is the process by which an agent creates a specification of a software artifact intended to accomplish goals, using a set of primitive components and subject to constraints. Software design may refer to either "all the activity involved in conceptualizing, framing, implementing, commissioning, and ultimately modifying complex systems" or "the activity following requirements specification and before programming, as ... [in] a stylized software engineering process."
In information science, formal concept analysis (FCA) is a principled way of deriving a concept hierarchy or formal ontology from a collection of objects and their properties. Each concept in the hierarchy represents the objects sharing some set of properties; and each sub-concept in the hierarchy represents a subset of the objects in the concepts above it. The term was introduced by Rudolf Wille in 1981, and builds on the mathematical theory of lattices and ordered sets that was developed by Garrett Birkhoff and others in the 1930s.
A modeling language is any artificial language that can be used to express information or knowledge or systems in a structure that is defined by a consistent set of rules. The rules are used for interpretation of the meaning of components in the structure.

IDEF, initially an abbreviation of ICAM Definition and renamed in 1999 as Integration Definition, is a family of modeling languages in the field of systems and software engineering. They cover a wide range of uses from functional modeling to data, simulation, object-oriented analysis and design, and knowledge acquisition. These definition languages were developed under funding from U.S. Air Force and, although still most commonly used by them and other military and United States Department of Defense (DoD) agencies, are in the public domain.

In systems engineering, information systems and software engineering, the systems development life cycle (SDLC), also referred to as the application development life-cycle, is a process for planning, creating, testing, and deploying an information system. The systems development life cycle concept applies to a range of hardware and software configurations, as a system can be composed of hardware only, software only, or a combination of both. There are usually six stages in this cycle: requirement analysis, design, development and testing, implementation, documentation, and evaluation.
Cheminformatics refers to use of physical chemistry theory with computer and information science techniques—so called "in silico" techniques—in application to a range of descriptive and prescriptive problems in the field of chemistry, including in its applications to biology and related molecular fields. Such in silico techniques are used, for example, by pharmaceutical companies and in academic settings to aid and inform the process of drug discovery, for instance in the design of well-defined combinatorial libraries of synthetic compounds, or to assist in structure-based drug design. The methods can also be used in chemical and allied industries, and such fields as environmental science and pharmacology, where chemical processes are involved or studied.
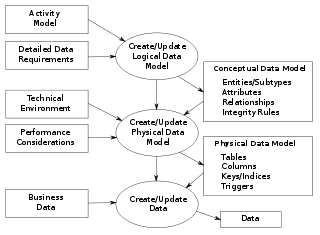
Data modeling in software engineering is the process of creating a data model for an information system by applying certain formal techniques.

An information model in software engineering is a representation of concepts and the relationships, constraints, rules, and operations to specify data semantics for a chosen domain of discourse. Typically it specifies relations between kinds of things, but may also include relations with individual things. It can provide sharable, stable, and organized structure of information requirements or knowledge for the domain context.
Object-oriented analysis and design (OOAD) is a technical approach for analyzing and designing an application, system, or business by applying object-oriented programming, as well as using visual modeling throughout the software development process to guide stakeholder communication and product quality.
A software design description is a representation of a software design that is to be used for recording design information, addressing various design concerns, and communicating that information to the design’s stakeholders. An SDD usually accompanies an architecture diagram with pointers to detailed feature specifications of smaller pieces of the design. Practically, the description is required to coordinate a large team under a single vision, needs to be a stable reference, and outline all parts of the software and how they will work.

In the context of spatial analysis, geographic information systems, and geographic information science, a field is a property that fills space, and varies over space, such as temperature or density. This use of the term has been adopted from physics and mathematics, due to their similarity to physical fields such as the electromagnetic field or gravitational field. Synonymous terms include spatially dependent variable (geostatistics), statistical surface, and intensive property (Chemistry) and crossbreeding between these disciplines is common. The simplest formal model for a field is the function, which yields a single value given a point in space
Conceptual clustering is a machine learning paradigm for unsupervised classification that has been defined by Ryszard S. Michalski in 1980 and developed mainly during the 1980s. It is distinguished from ordinary data clustering by generating a concept description for each generated class. Most conceptual clustering methods are capable of generating hierarchical category structures; see Categorization for more information on hierarchy. Conceptual clustering is closely related to formal concept analysis, decision tree learning, and mixture model learning.
A data model in geographic information systems is a mathematical and digital structure for representing geographic phenomena. Generally, geospatial data models represent various aspects of these phenomena, including spatial locations, properties, change over time, and identity. For example, the vector data model represents geography as collections of points, lines, and polygons, and the raster data model represent geography as cell matrices that store numeric values. Data models are implemented throughout the GIS ecosystem, including the software tools for data management and analysis, data stored in a variety of file formats, specifications and standards, and specific designs for GIS installations.

Semantic data model (SDM) is a high-level semantics-based database description and structuring formalism for databases. This database model is designed to capture more of the meaning of an application environment than is possible with contemporary database models. An SDM specification describes a database in terms of the kinds of entities that exist in the application environment, the classifications and groupings of those entities, and the structural interconnections among them. SDM provides a collection of high-level modeling primitives to capture the semantics of an application environment. By accommodating derived information in a database structural specification, SDM allows the same information to be viewed in several ways; this makes it possible to directly accommodate the variety of needs and processing requirements typically present in database applications. The design of the present SDM is based on our experience in using a preliminary version of it. SDM is designed to enhance the effectiveness and usability of database systems. An SDM database description can serve as a formal specification and documentation tool for a database; it can provide a basis for supporting a variety of powerful user interface facilities, it can serve as a conceptual database model in the database design process; and, it can be used as the database model for a new kind of database management system.
Lynne Billard is an Australian statistician and professor at the University of Georgia, known for her statistics research, leadership, and advocacy for women in science. She has served as president of the American Statistical Association, and the International Biometric Society, one of a handful of people to have led both organizations.
References
- ↑ Diday, Edwin; Esposito, Floriana (December 2003). "An introduction to symbolic data analysis and the SODAS software". Intelligent Data Analysis. 7 (6): 583–601. doi:10.3233/IDA-2003-7606.
- ↑ Lynne Billard; Edwin Diday (14 May 2012). Symbolic Data Analysis: Conceptual Statistics and Data Mining. John Wiley & Sons. ISBN 978-0-470-09017-6.