
In computing, a database is an organized collection of data or a type of data store based on the use of a database management system (DBMS), the software that interacts with end users, applications, and the database itself to capture and analyze the data. The DBMS additionally encompasses the core facilities provided to administer the database. The sum total of the database, the DBMS and the associated applications can be referred to as a database system. Often the term "database" is also used loosely to refer to any of the DBMS, the database system or an application associated with the database.
XFS is a high-performance 64-bit journaling file system created by Silicon Graphics, Inc (SGI) in 1993. It was the default file system in SGI's IRIX operating system starting with its version 5.3. XFS was ported to the Linux kernel in 2001; as of June 2014, XFS is supported by most Linux distributions; Red Hat Enterprise Linux uses it as its default file system.
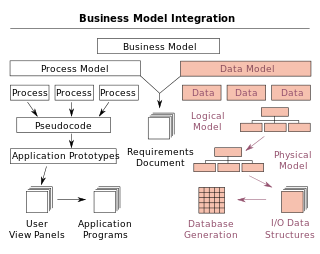
A data model is an abstract model that organizes elements of data and standardizes how they relate to one another and to the properties of real-world entities. For instance, a data model may specify that the data element representing a car be composed of a number of other elements which, in turn, represent the color and size of the car and define its owner.

The database schema is the structure of a database described in a formal language supported typically by a relational database management system (RDBMS). The term "schema" refers to the organization of data as a blueprint of how the database is constructed. The formal definition of a database schema is a set of formulas (sentences) called integrity constraints imposed on a database. These integrity constraints ensure compatibility between parts of the schema. All constraints are expressible in the same language. A database can be considered a structure in realization of the database language. The states of a created conceptual schema are transformed into an explicit mapping, the database schema. This describes how real-world entities are modeled in the database.
WinFS was the code name for a canceled data storage and management system project based on relational databases, developed by Microsoft and first demonstrated in 2003. It was intended as an advanced storage subsystem for the Microsoft Windows operating system, designed for persistence and management of structured, semi-structured and unstructured data.
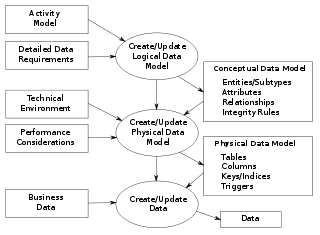
Data modeling in software engineering is the process of creating a data model for an information system by applying certain formal techniques. It may be applied as part of broader Model-driven engineering (MDE) concept.

In computing, a file system or filesystem is a method and data structure that the operating system uses to control how data is stored and retrieved. Without a file system, data placed in a storage medium would be one large body of data with no way to tell where one piece of data stopped and the next began, or where any piece of data was located when it was time to retrieve it. By separating the data into pieces and giving each piece a name, the data are easily isolated and identified. Taking its name from the way a paper-based data management system is named, each group of data is called a "file". The structure and logic rules used to manage the groups of data and their names is called a "file system."
A physical data model is a representation of a data design as implemented, or intended to be implemented, in a database management system. In the lifecycle of a project it typically derives from a logical data model, though it may be reverse-engineered from a given database implementation. A complete physical data model will include all the database artifacts required to create relationships between tables or to achieve performance goals, such as indexes, constraint definitions, linking tables, partitioned tables or clusters. Analysts can usually use a physical data model to calculate storage estimates; it may include specific storage allocation details for a given database system.
Database design is the organization of data according to a database model. The designer determines what data must be stored and how the data elements interrelate. With this information, they can begin to fit the data to the database model. A database management system manages the data accordingly.
A database index is a data structure that improves the speed of data retrieval operations on a database table at the cost of additional writes and storage space to maintain the index data structure. Indexes are used to quickly locate data without having to search every row in a database table every time said table is accessed. Indexes can be created using one or more columns of a database table, providing the basis for both rapid random lookups and efficient access of ordered records.
Data independence is the type of data transparency that matters for a centralized DBMS. It refers to the immunity of user applications to changes made in the definition and organization of data. Application programs should not, ideally, be exposed to details of data representation and storage. The DBMS provides an abstract view of the data that hides such details.

In computer science, data is any sequence of one or more symbols; datum is a single symbol of data. Data requires interpretation to become information. Digital data is data that is represented using the binary number system of ones (1) and zeros (0), instead of analog representation. In modern (post-1960) computer systems, all data is digital.
In Linux, Logical Volume Manager (LVM) is a device mapper framework that provides logical volume management for the Linux kernel. Most modern Linux distributions are LVM-aware to the point of being able to have their root file systems on a logical volume.
Replication in computing involves sharing information so as to ensure consistency between redundant resources, such as software or hardware components, to improve reliability, fault-tolerance, or accessibility.
In computer science, storage virtualization is "the process of presenting a logical view of the physical storage resources to" a host computer system, "treating all storage media in the enterprise as a single pool of storage."
An entity–attribute–value model (EAV) is a data model optimized for the space-efficient storage of sparse—or ad-hoc—property or data values, intended for situations where runtime usage patterns are arbitrary, subject to user variation, or otherwise unforeseeable using a fixed design. The use-case targets applications which offer a large or rich system of defined property types, which are in turn appropriate to a wide set of entities, but where typically only a small, specific selection of these are instantiated for a given entity. Therefore, this type of data model relates to the mathematical notion of a sparse matrix. EAV is also known as object–attribute–value model, vertical database model, and open schema.
Entity Framework (EF) is an open source object–relational mapping (ORM) framework for ADO.NET. It was originally shipped as an integral part of .NET Framework, however starting with Entity Framework version 6.0 it has been delivered separately from the .NET Framework.
Btrfs is a computer storage format that combines a file system based on the copy-on-write (COW) principle with a logical volume manager, developed together. It was founded by Chris Mason in 2007 for use in Linux, and since November 2013, the file system's on-disk format has been declared stable in the Linux kernel.
A graph database (GDB) is a database that uses graph structures for semantic queries with nodes, edges, and properties to represent and store data. A key concept of the system is the graph. The graph relates the data items in the store to a collection of nodes and edges, the edges representing the relationships between the nodes. The relationships allow data in the store to be linked together directly and, in many cases, retrieved with one operation. Graph databases hold the relationships between data as a priority. Querying relationships is fast because they are perpetually stored in the database. Relationships can be intuitively visualized using graph databases, making them useful for heavily inter-connected data.
The following is provided as an overview of and topical guide to databases: