Continuum mechanics is a branch of mechanics that deals with the deformation of and transmission of forces through materials modeled as a continuous medium rather than as discrete particles.

In mathematics, a normed vector space or normed space is a vector space over the real or complex numbers on which a norm is defined. A norm is a generalization of the intuitive notion of "length" in the physical world. If is a vector space over , where is a field equal to or to , then a norm on is a map , typically denoted by , satisfying the following four axioms:
- Non-negativity: for every ,.
- Positive definiteness: for every , if and only if is the zero vector.
- Absolute homogeneity: for every and ,
- Triangle inequality: for every and ,
In mathematics, a product is the result of multiplication, or an expression that identifies objects to be multiplied, called factors. For example, 21 is the product of 3 and 7, and is the product of and . When one factor is an integer, the product is called a multiple.

In mathematics, a tensor is an algebraic object that describes a multilinear relationship between sets of algebraic objects related to a vector space. Tensors may map between different objects such as vectors, scalars, and even other tensors. There are many types of tensors, including scalars and vectors, dual vectors, multilinear maps between vector spaces, and even some operations such as the dot product. Tensors are defined independent of any basis, although they are often referred to by their components in a basis related to a particular coordinate system; those components form an array, which can be thought of as a high-dimensional matrix.

In Euclidean geometry, an affine transformation or affinity is a geometric transformation that preserves lines and parallelism, but not necessarily Euclidean distances and angles.
In mathematics, the Lp spaces are function spaces defined using a natural generalization of the p-norm for finite-dimensional vector spaces. They are sometimes called Lebesgue spaces, named after Henri Lebesgue, although according to the Bourbaki group they were first introduced by Frigyes Riesz.

Noether's theorem states that every continuous symmetry of the action of a physical system with conservative forces has a corresponding conservation law. This is the first of two theorems published by mathematician Emmy Noether in 1918. The action of a physical system is the integral over time of a Lagrangian function, from which the system's behavior can be determined by the principle of least action. This theorem only applies to continuous and smooth symmetries of physical space.
Vapnik–Chervonenkis theory was developed during 1960–1990 by Vladimir Vapnik and Alexey Chervonenkis. The theory is a form of computational learning theory, which attempts to explain the learning process from a statistical point of view.
In functional analysis, it is often convenient to define a linear transformation on a complete, normed vector space by first defining a linear transformation on a dense subset of and then continuously extending to the whole space via the theorem below. The resulting extension remains linear and bounded, and is thus continuous, which makes it a continuous linear extension.
Convex optimization is a subfield of mathematical optimization that studies the problem of minimizing convex functions over convex sets. Many classes of convex optimization problems admit polynomial-time algorithms, whereas mathematical optimization is in general NP-hard.
In mathematics, nuclear spaces are topological vector spaces that can be viewed as a generalization of finite-dimensional Euclidean spaces and share many of their desirable properties. Nuclear spaces are however quite different from Hilbert spaces, another generalization of finite-dimensional Euclidean spaces. They were introduced by Alexander Grothendieck.
In machine learning, kernel machines are a class of algorithms for pattern analysis, whose best known member is the support-vector machine (SVM). These methods involve using linear classifiers to solve nonlinear problems. The general task of pattern analysis is to find and study general types of relations in datasets. For many algorithms that solve these tasks, the data in raw representation have to be explicitly transformed into feature vector representations via a user-specified feature map: in contrast, kernel methods require only a user-specified kernel, i.e., a similarity function over all pairs of data points computed using inner products. The feature map in kernel machines is infinite dimensional but only requires a finite dimensional matrix from user-input according to the Representer theorem. Kernel machines are slow to compute for datasets larger than a couple of thousand examples without parallel processing.
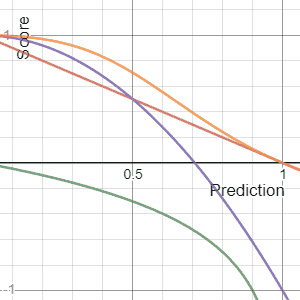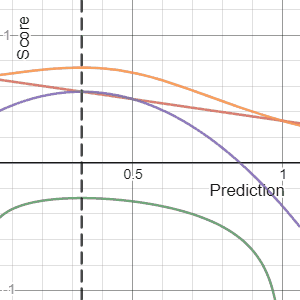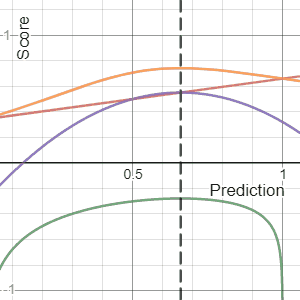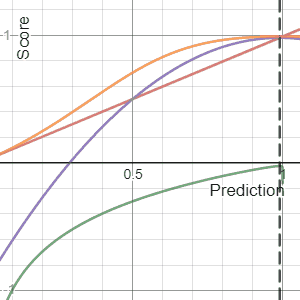
In decision theory, a scoring rule provides evaluation metrics for probabilistic predictions or forecasts. While "regular" loss functions assign a goodness-of-fit score to a predicted value and an observed value, scoring rules assign such a score to a predicted probability distribution and an observed value. On the other hand, a scoring function provides a summary measure for the evaluation of point predictions, i.e. one predicts a property or functional , like the expectation or the median.
In applied mathematics, polyharmonic splines are used for function approximation and data interpolation. They are very useful for interpolating and fitting scattered data in many dimensions. Special cases include thin plate splines and natural cubic splines in one dimension.
In multilinear algebra, the tensor rank decomposition or rank-R decomposition is the decomposition of a tensor as a sum of R rank-1 tensors, where R is minimal. Computing this decomposition is an open problem.
In multilinear algebra, the higher-order singular value decomposition (HOSVD) of a tensor is a specific orthogonal Tucker decomposition. It may be regarded as one type of generalization of the matrix singular value decomposition. It has applications in computer vision, computer graphics, machine learning, scientific computing, and signal processing. Some aspects can be traced as far back as F. L. Hitchcock in 1928, but it was L. R. Tucker who developed for third-order tensors the general Tucker decomposition in the 1960s, further advocated by L. De Lathauwer et al. in their Multilinear SVD work that employs the power method, or advocated by Vasilescu and Terzopoulos that developed M-mode SVD a parallel algorithm that employs the matrix SVD.
Within bayesian statistics for machine learning, kernel methods arise from the assumption of an inner product space or similarity structure on inputs. For some such methods, such as support vector machines (SVMs), the original formulation and its regularization were not Bayesian in nature. It is helpful to understand them from a Bayesian perspective. Because the kernels are not necessarily positive semidefinite, the underlying structure may not be inner product spaces, but instead more general reproducing kernel Hilbert spaces. In Bayesian probability kernel methods are a key component of Gaussian processes, where the kernel function is known as the covariance function. Kernel methods have traditionally been used in supervised learning problems where the input space is usually a space of vectors while the output space is a space of scalars. More recently these methods have been extended to problems that deal with multiple outputs such as in multi-task learning.
Baranyi and Yam proposed the TP model transformation as a new concept in quasi-LPV (qLPV) based control, which plays a central role in the highly desirable bridging between identification and polytopic systems theories. It is also used as a TS (Takagi-Sugeno) fuzzy model transformation. It is uniquely effective in manipulating the convex hull of polytopic forms, and, hence, has revealed and proved the fact that convex hull manipulation is a necessary and crucial step in achieving optimal solutions and decreasing conservativeness in modern linear matrix inequality based control theory. Thus, although it is a transformation in a mathematical sense, it has established a conceptually new direction in control theory and has laid the ground for further new approaches towards optimality.
Based on the key idea of higher-order singular value decomposition (HOSVD) in tensor algebra, Baranyi and Yam proposed the concept of HOSVD-based canonical form of TP functions and quasi-LPV system models. Szeidl et al. proved that the TP model transformation is capable of numerically reconstructing this canonical form.
Lagrangian field theory is a formalism in classical field theory. It is the field-theoretic analogue of Lagrangian mechanics. Lagrangian mechanics is used to analyze the motion of a system of discrete particles each with a finite number of degrees of freedom. Lagrangian field theory applies to continua and fields, which have an infinite number of degrees of freedom.
Baranyi, P. (2018). Extension of the Multi-TP Model Transformation to Functions with Different Numbers of Variables. Complexity, 2018.



































