
In machine learning, a neural network is a model inspired by the structure and function of biological neural networks in animal brains.
Natural language processing (NLP) is an interdisciplinary subfield of computer science and artificial intelligence. It is primarily concerned with providing computers the ability to process data encoded in natural language and is thus closely related to information retrieval, knowledge representation and computational linguistics, a subfield of linguistics. Typically data is collected in text corpora, using either rule-based, statistical or neural-based approaches of machine learning and deep learning.
Speech processing is the study of speech signals and the processing methods of signals. The signals are usually processed in a digital representation, so speech processing can be regarded as a special case of digital signal processing, applied to speech signals. Aspects of speech processing includes the acquisition, manipulation, storage, transfer and output of speech signals. Different speech processing tasks include speech recognition, speech synthesis, speaker diarization, speech enhancement, speaker recognition, etc.
Speech recognition is an interdisciplinary subfield of computer science and computational linguistics that develops methodologies and technologies that enable the recognition and translation of spoken language into text by computers. It is also known as automatic speech recognition (ASR), computer speech recognition or speech-to-text (STT). It incorporates knowledge and research in the computer science, linguistics and computer engineering fields. The reverse process is speech synthesis.
Pattern recognition is the task of assigning a class to an observation based on patterns extracted from data. While similar, pattern recognition (PR) is not to be confused with pattern machines (PM) which may possess (PR) capabilities but their primary function is to distinguish and create emergent patterns. PR has applications in statistical data analysis, signal processing, image analysis, information retrieval, bioinformatics, data compression, computer graphics and machine learning. Pattern recognition has its origins in statistics and engineering; some modern approaches to pattern recognition include the use of machine learning, due to the increased availability of big data and a new abundance of processing power.
SpeechFX, Inc. offers voice technology for mobile phone and wireless devices, interactive video games, toys, home appliances, computer telephony systems and vehicle telematics. SpeechFX speech solutions are based on the firm’s proprietary neural network-based automatic speech recognition (ASR) and Fonix DECtalk, a text-to-speech speech synthesis system (TTS). Fonix speech technology is user-independent, meaning no voice training is involved.
A recurrent neural network (RNN) is one of the two broad types of artificial neural network, characterized by direction of the flow of information between its layers. In contrast to the uni-directional feedforward neural network, it is a bi-directional artificial neural network, meaning that it allows the output from some nodes to affect subsequent input to the same nodes. Their ability to use internal state (memory) to process arbitrary sequences of inputs makes them applicable to tasks such as unsegmented, connected handwriting recognition or speech recognition. The term "recurrent neural network" is used to refer to the class of networks with an infinite impulse response, whereas "convolutional neural network" refers to the class of finite impulse response. Both classes of networks exhibit temporal dynamic behavior. A finite impulse recurrent network is a directed acyclic graph that can be unrolled and replaced with a strictly feedforward neural network, while an infinite impulse recurrent network is a directed cyclic graph that cannot be unrolled.
A language model is a probabilistic model of a natural language. In 1980, the first significant statistical language model was proposed, and during the decade IBM performed ‘Shannon-style’ experiments, in which potential sources for language modeling improvement were identified by observing and analyzing the performance of human subjects in predicting or correcting text.

An echo state network (ESN) is a type of reservoir computer that uses a recurrent neural network with a sparsely connected hidden layer. The connectivity and weights of hidden neurons are fixed and randomly assigned. The weights of output neurons can be learned so that the network can produce or reproduce specific temporal patterns. The main interest of this network is that although its behavior is non-linear, the only weights that are modified during training are for the synapses that connect the hidden neurons to output neurons. Thus, the error function is quadratic with respect to the parameter vector and can be differentiated easily to a linear system.
Reservoir computing is a framework for computation derived from recurrent neural network theory that maps input signals into higher dimensional computational spaces through the dynamics of a fixed, non-linear system called a reservoir. After the input signal is fed into the reservoir, which is treated as a "black box," a simple readout mechanism is trained to read the state of the reservoir and map it to the desired output. The first key benefit of this framework is that training is performed only at the readout stage, as the reservoir dynamics are fixed. The second is that the computational power of naturally available systems, both classical and quantum mechanical, can be used to reduce the effective computational cost.

Long short-term memory (LSTM) is a type of recurrent neural network (RNN) aimed at dealing with the vanishing gradient problem present in traditional RNNs. Its relative insensitivity to gap length is its advantage over other RNNs, hidden Markov models and other sequence learning methods. It aims to provide a short-term memory for RNN that can last thousands of timesteps, thus "long short-term memory". It is applicable to classification, processing and predicting data based on time series, such as in handwriting, speech recognition, machine translation, speech activity detection, robot control, video games, and healthcare.
SpinVox was a start-up company that is now a subsidiary of global speech technology company Nuance Communications, an American multinational computer software technology corporation, headquartered in Burlington, Massachusetts, United States on the outskirts of Boston, that provides speech and imaging applications. Initially, SpinVox provided voice-to-text conversion services for carrier markets, including wireless, fixed, VoIP and cable, as well as for unified communications, enterprise and Web 2.0 environments. This service was ostensibly provided through an automated computer system, with human intervention where needed. However, there were accusations that the system operated almost exclusively through the use of call-center workers in South Africa and the Philippines.
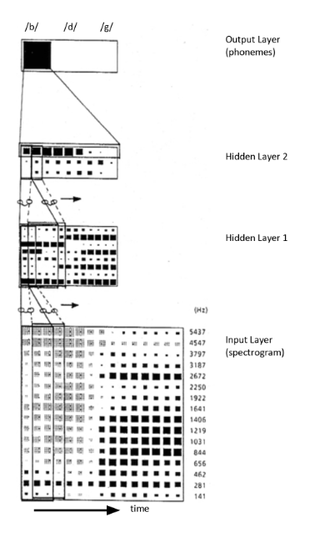
Time delay neural network (TDNN) is a multilayer artificial neural network architecture whose purpose is to 1) classify patterns with shift-invariance, and 2) model context at each layer of the network.
Loquendo is an Italian multinational computer software technology corporation, headquartered in Torino, Italy, that provides speech recognition, speech synthesis, speaker verification and identification applications. Loquendo, which was founded in 2001 under the Telecom Italia Lab, also had offices in United Kingdom, Spain, Germany, France, and the United States.

Deep learning is the subset of machine learning methods based on neural networks with representation learning. The adjective "deep" refers to the use of multiple layers in the network. Methods used can be either supervised, semi-supervised or unsupervised.
Nelson Harold Morgan is an American computer scientist and professor in residence (emeritus) of electrical engineering and computer science at the University of California, Berkeley. Morgan is the co-inventor of the Relative Spectral (RASTA) approach to speech signal processing, first described in a technical report published in 1991.
In signal processing, Feature space Maximum Likelihood Linear Regression (fMLLR) is a global feature transform that are typically applied in a speaker adaptive way, where fMLLR transforms acoustic features to speaker adapted features by a multiplication operation with a transformation matrix. In some literature, fMLLR is also known as the Constrained Maximum Likelihood Linear Regression (cMLLR).
Connectionist temporal classification (CTC) is a type of neural network output and associated scoring function, for training recurrent neural networks (RNNs) such as LSTM networks to tackle sequence problems where the timing is variable. It can be used for tasks like on-line handwriting recognition or recognizing phonemes in speech audio. CTC refers to the outputs and scoring, and is independent of the underlying neural network structure. It was introduced in 2006.
Speechmatics is a technology company based in Cambridge, England, which develops automatic speech recognition software (ASR) based on recurrent neural networks and statistical language modelling. Speechmatics was originally named Cantab Research Ltd when founded in 2006 by speech recognition specialist Dr. Tony Robinson.
Artificial neural networks (ANNs) are models created using machine learning to perform a number of tasks. Their creation was inspired by neural circuitry. While some of the computational implementations ANNs relate to earlier discoveries in mathematics, the first implementation of ANNs was by psychologist Frank Rosenblatt, who developed the perceptron. Little research was conducted on ANNs in the 1970s and 1980s, with the AAAI calling that period an "AI winter".