
In computer science, binary search, also known as half-interval search, logarithmic search, or binary chop, is a search algorithm that finds the position of a target value within a sorted array. Binary search compares the target value to the middle element of the array. If they are not equal, the half in which the target cannot lie is eliminated and the search continues on the remaining half, again taking the middle element to compare to the target value, and repeating this until the target value is found. If the search ends with the remaining half being empty, the target is not in the array.

In computer science and information theory, a Huffman code is a particular type of optimal prefix code that is commonly used for lossless data compression. The process of finding or using such a code proceeds by means of Huffman coding, an algorithm developed by David A. Huffman while he was a Sc.D. student at MIT, and published in the 1952 paper "A Method for the Construction of Minimum-Redundancy Codes".

In computer science, a heap is a specialized tree-based data structure which is essentially an almost complete tree that satisfies the heap property: in a max heap, for any given node C, if P is a parent node of C, then the key of P is greater than or equal to the key of C. In a min heap, the key of P is less than or equal to the key of C. The node at the "top" of the heap is called the root node.
In computer science, a priority queue is an abstract data-type similar to a regular queue or stack data structure. Each element in a priority queue has an associated priority. In a priority queue, elements with high priority are served before elements with low priority. In some implementations, if two elements have the same priority, they are served in the same order that they were enqueued in. In other implementations, the order of elements with the same priority is undefined.
In the field of data compression, Shannon–Fano coding, named after Claude Shannon and Robert Fano, is a name given to two different but related techniques for constructing a prefix code based on a set of symbols and their probabilities.

A binary heap is a heap data structure that takes the form of a binary tree. Binary heaps are a common way of implementing priority queues. The binary heap was introduced by J. W. J. Williams in 1964, as a data structure for heapsort.
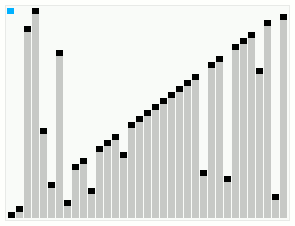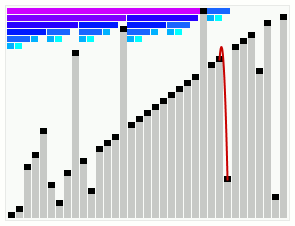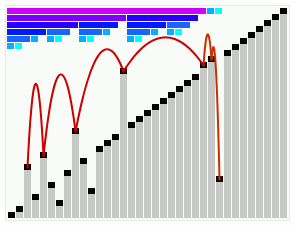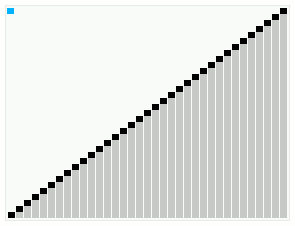
In computer science, smoothsort is a comparison-based sorting algorithm. A variant of heapsort, it was invented and published by Edsger Dijkstra in 1981. Like heapsort, smoothsort is an in-place algorithm with an upper bound of O(n log n), but it is not a stable sort. The advantage of smoothsort is that it comes closer to O(n) time if the input is already sorted to some degree, whereas heapsort averages O(n log n) regardless of the initial sorted state.
In computer science, a Fibonacci heap is a data structure for priority queue operations, consisting of a collection of heap-ordered trees. It has a better amortized running time than many other priority queue data structures including the binary heap and binomial heap. Michael L. Fredman and Robert E. Tarjan developed Fibonacci heaps in 1984 and published them in a scientific journal in 1987. Fibonacci heaps are named after the Fibonacci numbers, which are used in their running time analysis.
In computer science, a topological sort or topological ordering of a directed graph is a linear ordering of its vertices such that for every directed edge uv from vertex u to vertex v, u comes before v in the ordering. For instance, the vertices of the graph may represent tasks to be performed, and the edges may represent constraints that one task must be performed before another; in this application, a topological ordering is just a valid sequence for the tasks. Precisely, a topological sort is a graph traversal in which each node v is visited only after all its dependencies are visited. A topological ordering is possible if and only if the graph has no directed cycles, that is, if it is a directed acyclic graph (DAG). Any DAG has at least one topological ordering, and algorithms are known for constructing a topological ordering of any DAG in linear time. Topological sorting has many applications especially in ranking problems such as feedback arc set. Topological sorting is possible even when the DAG has disconnected components.
In computer science, corecursion is a type of operation that is dual to recursion. Whereas recursion works analytically, starting on data further from a base case and breaking it down into smaller data and repeating until one reaches a base case, corecursion works synthetically, starting from a base case and building it up, iteratively producing data further removed from a base case. Put simply, corecursive algorithms use the data that they themselves produce, bit by bit, as they become available, and needed, to produce further bits of data. A similar but distinct concept is generative recursion which may lack a definite "direction" inherent in corecursion and recursion.

In graph theory, an m-ary tree is a rooted tree in which each node has no more than m children. A binary tree is the special case where m = 2, and a ternary tree is another case with m = 3 that limits its children to three.
A fundamental problem in distributed computing and multi-agent systems is to achieve overall system reliability in the presence of a number of faulty processes. This often requires coordinating processes to reach consensus, or agree on some data value that is needed during computation. Example applications of consensus include agreeing on what transactions to commit to a database in which order, state machine replication, and atomic broadcasts. Real-world applications often requiring consensus include cloud computing, clock synchronization, PageRank, opinion formation, smart power grids, state estimation, control of UAVs, load balancing, blockchain, and others.
In computer science, the prefix sum, cumulative sum, inclusive scan, or simply scan of a sequence of numbers x0, x1, x2, ... is a second sequence of numbers y0, y1, y2, ..., the sums of prefixes of the input sequence:

The distributed minimum spanning tree (MST) problem involves the construction of a minimum spanning tree by a distributed algorithm, in a network where nodes communicate by message passing. It is radically different from the classical sequential problem, although the most basic approach resembles Borůvka's algorithm. One important application of this problem is to find a tree that can be used for broadcasting. In particular, if the cost for a message to pass through an edge in a graph is significant, an MST can minimize the total cost for a source process to communicate with all the other processes in the network.
In distributed computing, leader election is the process of designating a single process as the organizer of some task distributed among several computers (nodes). Before the task has begun, all network nodes are either unaware which node will serve as the "leader" of the task, or unable to communicate with the current coordinator. After a leader election algorithm has been run, however, each node throughout the network recognizes a particular, unique node as the task leader.

A Fenwick tree or binary indexed tree(BIT) is a data structure that can efficiently update elements and calculate prefix sums in a table of numbers.
Collective operations are building blocks for interaction patterns, that are often used in SPMD algorithms in the parallel programming context. Hence, there is an interest in efficient realizations of these operations.
In computer science, the reduction operator is a type of operator that is commonly used in parallel programming to reduce the elements of an array into a single result. Reduction operators are associative and often commutative. The reduction of sets of elements is an integral part of programming models such as Map Reduce, where a reduction operator is applied (mapped) to all elements before they are reduced. Other parallel algorithms use reduction operators as primary operations to solve more complex problems. Many reduction operators can be used for broadcasting to distribute data to all processors.
-dimensional hypercube is a network topology for parallel computers with processing elements. The topology allows for an efficient implementation of some basic communication primitives such as Broadcast, All-Reduce, and Prefix sum. The processing elements are numbered through . Each processing element is adjacent to processing elements whose numbers differ in one and only one bit. The algorithms described in this page utilize this structure efficiently.
Broadcast is a collective communication primitive in parallel programming to distribute programming instructions or data to nodes in a cluster. It is the reverse operation of reduce. The broadcast operation is widely used in parallel algorithms, such as matrix-vector multiplication, Gaussian elimination and shortest paths.









