Pattern recognition is the task of assigning a class to an observation based on patterns extracted from data. While similar, pattern recognition (PR) is not to be confused with pattern machines (PM) which may possess (PR) capabilities but their primary function is to distinguish and create emergent patterns. PR has applications in statistical data analysis, signal processing, image analysis, information retrieval, bioinformatics, data compression, computer graphics and machine learning. Pattern recognition has its origins in statistics and engineering; some modern approaches to pattern recognition include the use of machine learning, due to the increased availability of big data and a new abundance of processing power.
The Hough transform is a feature extraction technique used in image analysis, computer vision, and digital image processing. The purpose of the technique is to find imperfect instances of objects within a certain class of shapes by a voting procedure. This voting procedure is carried out in a parameter space, from which object candidates are obtained as local maxima in a so-called accumulator space that is explicitly constructed by the algorithm for computing the Hough transform.

In digital image processing and computer vision, image segmentation is the process of partitioning a digital image into multiple image segments, also known as image regions or image objects. The goal of segmentation is to simplify and/or change the representation of an image into something that is more meaningful and easier to analyze. Image segmentation is typically used to locate objects and boundaries in images. More precisely, image segmentation is the process of assigning a label to every pixel in an image such that pixels with the same label share certain characteristics.
In computer vision or natural language processing, document layout analysis is the process of identifying and categorizing the regions of interest in the scanned image of a text document. A reading system requires the segmentation of text zones from non-textual ones and the arrangement in their correct reading order. Detection and labeling of the different zones as text body, illustrations, math symbols, and tables embedded in a document is called geometric layout analysis. But text zones play different logical roles inside the document and this kind of semantic labeling is the scope of the logical layout analysis.

In statistics, a multimodaldistribution is a probability distribution with more than one mode. These appear as distinct peaks in the probability density function, as shown in Figures 1 and 2. Categorical, continuous, and discrete data can all form multimodal distributions. Among univariate analyses, multimodal distributions are commonly bimodal.
Random sample consensus (RANSAC) is an iterative method to estimate parameters of a mathematical model from a set of observed data that contains outliers, when outliers are to be accorded no influence on the values of the estimates. Therefore, it also can be interpreted as an outlier detection method. It is a non-deterministic algorithm in the sense that it produces a reasonable result only with a certain probability, with this probability increasing as more iterations are allowed. The algorithm was first published by Fischler and Bolles at SRI International in 1981. They used RANSAC to solve the Location Determination Problem (LDP), where the goal is to determine the points in the space that project onto an image into a set of landmarks with known locations.
The scale-invariant feature transform (SIFT) is a computer vision algorithm to detect, describe, and match local features in images, invented by David Lowe in 1999. Applications include object recognition, robotic mapping and navigation, image stitching, 3D modeling, gesture recognition, video tracking, individual identification of wildlife and match moving.

In digital image processing, thresholding is the simplest method of segmenting images. From a grayscale image, thresholding can be used to create binary images.

In computer vision and image processing, Otsu's method, named after Nobuyuki Otsu, is used to perform automatic image thresholding. In the simplest form, the algorithm returns a single intensity threshold that separate pixels into two classes, foreground and background. This threshold is determined by minimizing intra-class intensity variance, or equivalently, by maximizing inter-class variance. Otsu's method is a one-dimensional discrete analogue of Fisher's Discriminant Analysis, is related to Jenks optimization method, and is equivalent to a globally optimal k-means performed on the intensity histogram. The extension to multi-level thresholding was described in the original paper, and computationally efficient implementations have since been proposed.
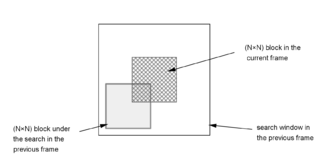
A Block Matching Algorithm is a way of locating matching macroblocks in a sequence of digital video frames for the purposes of motion estimation. The underlying supposition behind motion estimation is that the patterns corresponding to objects and background in a frame of video sequence move within the frame to form corresponding objects on the subsequent frame. This can be used to discover temporal redundancy in the video sequence, increasing the effectiveness of inter-frame video compression by defining the contents of a macroblock by reference to the contents of a known macroblock which is minimally different.
Mean shift is a non-parametric feature-space mathematical analysis technique for locating the maxima of a density function, a so-called mode-seeking algorithm. Application domains include cluster analysis in computer vision and image processing.
Compressed sensing is a signal processing technique for efficiently acquiring and reconstructing a signal, by finding solutions to underdetermined linear systems. This is based on the principle that, through optimization, the sparsity of a signal can be exploited to recover it from far fewer samples than required by the Nyquist–Shannon sampling theorem. There are two conditions under which recovery is possible. The first one is sparsity, which requires the signal to be sparse in some domain. The second one is incoherence, which is applied through the isometric property, which is sufficient for sparse signals. Compressed sensing has applications in, for example, MRI where the incoherence condition is typically satisfied.
The Kadir–Brady saliency detector extracts features of objects in images that are distinct and representative. It was invented by Timor Kadir and J. Michael Brady in 2001 and an affine invariant version was introduced by Kadir and Brady in 2004 and a robust version was designed by Shao et al. in 2007.
Object recognition – technology in the field of computer vision for finding and identifying objects in an image or video sequence. Humans recognize a multitude of objects in images with little effort, despite the fact that the image of the objects may vary somewhat in different view points, in many different sizes and scales or even when they are translated or rotated. Objects can even be recognized when they are partially obstructed from view. This task is still a challenge for computer vision systems. Many approaches to the task have been implemented over multiple decades.
Region growing is a simple region-based image segmentation method. It is also classified as a pixel-based image segmentation method since it involves the selection of initial seed points.

In image processing, the balanced histogram thresholding method (BHT), is a very simple method used for automatic image thresholding. Like Otsu's Method and the Iterative Selection Thresholding Method, this is a histogram based thresholding method. This approach assumes that the image is divided in two main classes: The background and the foreground. The BHT method tries to find the optimum threshold level that divides the histogram in two classes.

Circular thresholding is an algorithm for automatic image threshold selection in image processing. Most threshold selection algorithms assume that the values lie on a linear scale. However, some quantities such as hue and orientation are a circular quantity, and therefore require circular thresholding algorithms. The example shows that the standard linear version of Otsu's method when applied to the hue channel of an image of blood cells fails to correctly segment the large white blood cells (leukocytes). In contrast the white blood cells are correctly segmented by the circular version of Otsu's method.
Underwater computer vision is a subfield of computer vision. In recent years, with the development of underwater vehicles, the need to be able to record and process huge amounts of information has become increasingly important. Applications range from inspection of underwater structures for the offshore industry to the identification and counting of fishes for biological research. However, no matter how big the impact of this technology can be to industry and research, it still is in a very early stage of development compared to traditional computer vision. One reason for this is that, the moment the camera goes into the water, a whole new set of challenges appear. On one hand, cameras have to be made waterproof, marine corrosion deteriorates materials quickly and access and modifications to experimental setups are costly, both in time and resources. On the other hand, the physical properties of the water make light behave differently, changing the appearance of a same object with variations of depth, organic material, currents, temperature etc.

Block-matching and 3D filtering (BM3D) is a 3-D block-matching algorithm used primarily for noise reduction in images. It is one of the expansions of the non-local means methodology. There are two cascades in BM3D: a hard-thresholding and a Wiener filter stage, both involving the following parts: grouping, collaborative filtering, and aggregation. This algorithm depends on an augmented representation in the transformation site.



