Related Research Articles

Natural language processing (NLP) is an interdisciplinary subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human language, in particular how to program computers to process and analyze large amounts of natural language data. The goal is a computer capable of "understanding" the contents of documents, including the contextual nuances of the language within them. The technology can then accurately extract information and insights contained in the documents as well as categorize and organize the documents themselves.
The Semantic Web, sometimes known as Web 3.0, is an extension of the World Wide Web through standards set by the World Wide Web Consortium (W3C). The goal of the Semantic Web is to make Internet data machine-readable.
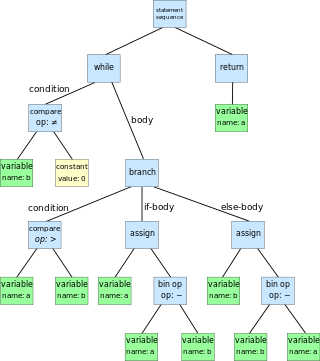
In computer science, an abstract syntax tree (AST), or just syntax tree, is a tree representation of the abstract syntactic structure of text written in a formal language. Each node of the tree denotes a construct occurring in the text.
MPEG-7 is a multimedia content description standard. It was standardized in ISO/IEC 15938. This description will be associated with the content itself, to allow fast and efficient searching for material that is of interest to the user. MPEG-7 is formally called Multimedia Content Description Interface. Thus, it is not a standard which deals with the actual encoding of moving pictures and audio, like MPEG-1, MPEG-2 and MPEG-4. It uses XML to store metadata, and can be attached to timecode in order to tag particular events, or synchronise lyrics to a song, for example.
An annotation is extra information associated with a particular point in a document or other piece of information. It can be a note that includes a comment or explanation. Annotations are sometimes presented in the margin of book pages. For annotations of different digital media, see web annotation and text annotation.

Automatic image annotation is the process by which a computer system automatically assigns metadata in the form of captioning or keywords to a digital image. This application of computer vision techniques is used in image retrieval systems to organize and locate images of interest from a database.
UCCA may stand for:

In linguistics, a treebank is a parsed text corpus that annotates syntactic or semantic sentence structure. The construction of parsed corpora in the early 1990s revolutionized computational linguistics, which benefitted from large-scale empirical data.
Semantic publishing on the Web, or semantic web publishing, refers to publishing information on the web as documents accompanied by semantic markup. Semantic publication provides a way for computers to understand the structure and even the meaning of the published information, making information search and data integration more efficient.
The concept of the Social Semantic Web subsumes developments in which social interactions on the Web lead to the creation of explicit and semantically rich knowledge representations. The Social Semantic Web can be seen as a Web of collective knowledge systems, which are able to provide useful information based on human contributions and which get better as more people participate. The Social Semantic Web combines technologies, strategies and methodologies from the Semantic Web, social software and the Web 2.0.
The Semantic Sensor Web (SSW) is a marriage of sensor web and semantic Web technologies. The encoding of sensor descriptions and sensor observation data with Semantic Web languages enables more expressive representation, advanced access, and formal analysis of sensor resources. The SSW annotates sensor data with spatial, temporal, and thematic semantic metadata. This technique builds on current standardization efforts within the Open Geospatial Consortium's Sensor Web Enablement (SWE) and extends them with Semantic Web technologies to provide enhanced descriptions and access to sensor data.
A discourse relation is a description of how two segments of discourse are logically and/or structurally connected to one another.
Knowledge extraction is the creation of knowledge from structured and unstructured sources. The resulting knowledge needs to be in a machine-readable and machine-interpretable format and must represent knowledge in a manner that facilitates inferencing. Although it is methodically similar to information extraction (NLP) and ETL, the main criterion is that the extraction result goes beyond the creation of structured information or the transformation into a relational schema. It requires either the reuse of existing formal knowledge or the generation of a schema based on the source data.
Semantic Annotations for WSDL and XML Schema (SAWSDL) is a 2007 published technical recommendation of W3C in the context of Semantic Web framework:
Temporal annotation is the study of how to automatically add semantic information regarding time to natural language documents. It plays a role in natural language processing and computational linguistics.
Babelfy is a software algorithm for the disambiguation of text written in any language.
NeXML is an exchange standard for representing phyloinformatic data. It was inspired by the widely used Nexus file format but uses XML to produce a more robust format for rich phylogenetic data. Advantages include syntax validation, semantic annotation, and web services. The format is broadly supported and has libraries in many popular programming languages for bioinformatics.
In natural language processing, linguistics, and neighboring fields, Linguistic Linked Open Data (LLOD) describes a method and an interdisciplinary community concerned with creating, sharing, and (re-)using language resources in accordance with Linked Data principles. The Linguistic Linked Open Data Cloud was conceived and is being maintained by the Open Linguistics Working Group (OWLG) of the Open Knowledge Foundation, but has been a point of focal activity for several W3C community groups, research projects, and infrastructure efforts since then.
Drama annotation is the process of annotating the metadata of a drama. Given a drama expressed in some medium, the process of metadata annotation identifies what are the elements that characterize the drama and annotates such elements in some metadata format. For example, in the sentence "Laertes and Polonius warn Ophelia to stay away from Hamlet." from the text Hamlet, the word "Laertes", which refers to a drama element, namely a character, will be annotated as "Char", taken from some set of metadata. This article addresses the drama annotation projects, with the sets of metadata and annotations proposed in the scientific literature, based markup languages and ontologies.
IEML is an Open source artificial method to represent the semantic content of a linguistic sign. It was designed by Pierre Lévy as an Open collaboration project as part of his works on Collective intelligence in order to encode meaning in a computer readable way. Its design is based on mathematics and logic abstractions but with a clear inspiration from the organic structure of natural languages.
References
| | This semantics article is a stub. You can help Wikipedia by expanding it. |