
A digital elevation model (DEM) is a 3D computer graphics representation of elevation data to represent terrain, commonly of a planet, moon, or asteroid. A "global DEM" refers to a discrete global grid. DEMs are used often in geographic information systems, and are the most common basis for digitally produced relief maps.

Fort Victoria, near present-day Smoky Lake, Alberta, was established by the Hudson's Bay Company in 1864 on the North Saskatchewan River as a trading post with the local Cree First Nations. It had previously been settled in 1862 as a Methodist Missionary site, on the location of an aboriginal meeting place. Today, it is a historical museum known as Victoria Settlement.

The Shuttle Radar Topography Mission (SRTM) is an international research effort that obtained digital elevation models on a near-global scale from 56°S to 60°N, to generate the most complete high-resolution digital topographic database of Earth prior to the release of the ASTER GDEM in 2009. SRTM consisted of a specially modified radar system that flew on board the Space Shuttle Endeavour during the 11-day STS-99 mission in February 2000. The radar system was based on the older Spaceborne Imaging Radar-C/X-band Synthetic Aperture Radar (SIR-C/X-SAR), previously used on the Shuttle in 1994. To acquire topographic data, the SRTM payload was outfitted with two radar antennas. One antenna was located in the Shuttle's payload bay, the other – a critical change from the SIR-C/X-SAR, allowing single-pass interferometry – on the end of a 60-meter (200-foot) mast that extended from the payload bay once the Shuttle was in space. The technique employed is known as interferometric synthetic aperture radar. Intermap Technologies was the prime contractor for processing the interferometric synthetic aperture radar data.

Data analysis is a process of inspecting, cleansing, transforming, and modelling data with the goal of discovering useful information, informing conclusions, and supporting decision-making. Data analysis has multiple facets and approaches, encompassing diverse techniques under a variety of names, and is used in different business, science, and social science domains. In today's business world, data analysis plays a role in making decisions more scientific and helping businesses operate more effectively.
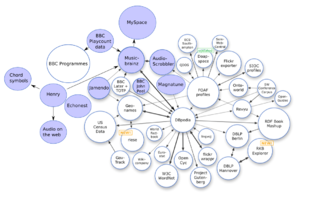
Open Data is the idea that some data should be freely available to everyone to use and republish as they wish, without restrictions from copyright, patents or other mechanisms of control. The goals of the open-source data movement are similar to those of other "open(-source)" movements such as open-source software, hardware, open content, open specifications, open education, open educational resources, open government, open knowledge, open access, open science, and the open web. Paradoxically, the growth of the open data movement is paralleled by a rise in intellectual property rights. The philosophy behind open data has been long established, but the term "open data" itself is recent, gaining popularity with the rise of the Internet and World Wide Web and, especially, with the launch of open-data government initiatives such as Data.gov, Data.gov.uk and Data.gov.in.

DBpedia is a project aiming to extract structured content from the information created in the Wikipedia project. This structured information is made available on the World Wide Web. DBpedia allows users to semantically query relationships and properties of Wikipedia resources, including links to other related datasets.
The Uppsala Conflict Data Program (UCDP) is a data collection program on organized violence, based at Uppsala University in Sweden. The UCDP is a leading provider of data on organized violence and armed conflict, and it is the oldest ongoing data collection project for civil war, with a history of almost 40 years. UCDP data are systematically collected and have global coverage, comparability across cases and countries, and long time series. Data are updated annually and are publicly available, free of charge. Furthermore, preliminary data on events of organized violence in Africa is released on a monthly basis.
In computer science, uncertain data is data that contains noise that makes it deviate from the correct, intended or original values. In the age of big data, uncertainty or data veracity is one of the defining characteristics of data. Data is constantly growing in volume, variety, velocity and uncertainty (1/veracity). Uncertain data is found in abundance today on the web, in sensor networks, within enterprises both in their structured and unstructured sources. For example, there may be uncertainty regarding the address of a customer in an enterprise dataset, or the temperature readings captured by a sensor due to aging of the sensor. In 2012 IBM called out managing uncertain data at scale in its global technology outlook report that presents a comprehensive analysis looking three to ten years into the future seeking to identify significant, disruptive technologies that will change the world. In order to make confident business decisions based on real-world data, analyses must necessarily account for many different kinds of uncertainty present in very large amounts of data. Analyses based on uncertain data will have an effect on the quality of subsequent decisions, so the degree and types of inaccuracies in this uncertain data cannot be ignored.
Market intelligence (MI) is the information relevant to a company's market - trends, competitor and customer monitoring, gathered and analyzed. It is a subtype of competitive intelligence (CI), is data and information gathered by companies that provides continuous insight into market trends such as competitors and customers values and preferences.

Big data is a field that treats ways to analyze, systematically extract information from, or otherwise deal with data sets that are too large or complex to be dealt with by traditional data-processing application software. Data with many fields (columns) offer greater statistical power, while data with higher complexity may lead to a higher false discovery rate. Big data analysis challenges include capturing data, data storage, data analysis, search, sharing, transfer, visualization, querying, updating, information privacy, and data source. Big data was originally associated with three key concepts: volume, variety, and velocity. The analysis of big data presents challenges in sampling, and thus previously allowing for only observations and sampling. Therefore, big data often includes data with sizes that exceed the capacity of traditional software to process within an acceptable time and value.

OpenChrom is an open source software for the analysis and visualization of mass spectrometric and chromatographic data. Its focus is to handle native data files from several mass spectrometry systems, vendors like Agilent Technologies, Varian, Shimadzu, Thermo Fisher, PerkinElmer and others. But also data formats from other detector types are supported recently.
Food composition data (FCD) are detailed sets of information on the nutritionally important components of foods and provide values for energy and nutrients including protein, carbohydrates, fat, vitamins and minerals and for other important food components such as fibre. The data are presented in food composition databases (FCDBs).
Data publishing is the act of releasing research data in published form for use by others. It is a practice consisting in preparing certain data or data set(s) for public use thus to make them available to everyone to use as they wish. This practice is an integral part of the open science movement. There is a large and multidisciplinary consensus on the benefits resulting from this practice.
The Open Energy Modelling Initiative (openmod) is a grassroots community of energy system modellers from universities and research institutes across Europe and elsewhere. The initiative promotes the use of open-source software and open data in energy system modelling for research and policy advice. The Open Energy Modelling Initiative documents a variety of open-source energy models and addresses practical and conceptual issues regarding their development and application. The initiative runs an email list, an internet forum, and a wiki and hosts occasional academic workshops. A statement of aims is available.
Data blending is a process whereby big data from multiple sources are merged into a single data warehouse or data set. It concerns not merely the merging of different file formats or disparate sources of data but also different varieties of data. Data blending allows business analysts to cope with the expansion of data that they need to make critical business decisions based on good quality business intelligence.
Truth-default theory (TDT) is a communication theory which predicts and explains the use of veracity and deception detection in humans. It was developed upon the discovery of the veracity effect - whereby the proportion of truths versus lies presented in a judgement study on deception will drive accuracy rates. This theory gets its name from its central idea which is the truth-default state. This idea suggests that people presume others to be honest because they either don't think of deception as a possibility during communicating or because there is insufficient evidence that they are being deceived. Emotions, arousal, strategic self-presentation, and cognitive effort are nonverbal behaviors that one might find in deception detection. Ultimately this theory predicts that speakers and listeners will default to use the truth to achieve their communicative goals. However, if the truth presents a problem, then deception will surface as a viable option for goal attainment.
Weak supervision is a branch of machine learning where noisy, limited, or imprecise sources are used to provide supervision signal for labeling large amounts of training data in a supervised learning setting. This approach alleviates the burden of obtaining hand-labeled data sets, which can be costly or impractical. Instead, inexpensive weak labels are employed with the understanding that they are imperfect, but can nonetheless be used to create a strong predictive model.
SILAM is a global-to-meso-scale atmospheric dispersion model developed by the Finnish Meteorological Institute (FMI). It provides information on atmospheric composition, air quality, and wildfire smoke (PM2.5) and is also able to solve the inverse dispersion problem. It can take data from a variety of sources, including natural ones such as sea salt, blown dust, and pollen.
COVID-19 datasets are public databases for sharing case data and medical information related to the COVID-19 pandemic.