
The travelling salesman problem (TSP) asks the following question: "Given a list of cities and the distances between each pair of cities, what is the shortest possible route that visits each city exactly once and returns to the origin city?" It is an NP-hard problem in combinatorial optimization, important in theoretical computer science and operations research.
The subset sum problem (SSP) is a decision problem in computer science. In its most general formulation, there is a multiset of integers and a target-sum , and the question is to decide whether any subset of the integers sum to precisely . The problem is known to be NP-hard. Moreover, some restricted variants of it are NP-complete too, for example:
An integer programming problem is a mathematical optimization or feasibility program in which some or all of the variables are restricted to be integers. In many settings the term refers to integer linear programming (ILP), in which the objective function and the constraints are linear.

In graph theory, graph coloring is a special case of graph labeling; it is an assignment of labels traditionally called "colors" to elements of a graph subject to certain constraints. In its simplest form, it is a way of coloring the vertices of a graph such that no two adjacent vertices are of the same color; this is called a vertex coloring. Similarly, an edge coloring assigns a color to each edge so that no two adjacent edges are of the same color, and a face coloring of a planar graph assigns a color to each face or region so that no two faces that share a boundary have the same color.

In graph theory, a vertex cover of a graph is a set of vertices that includes at least one endpoint of every edge of the graph.
In computer science and operations research, approximation algorithms are efficient algorithms that find approximate solutions to optimization problems with provable guarantees on the distance of the returned solution to the optimal one. Approximation algorithms naturally arise in the field of theoretical computer science as a consequence of the widely believed P ≠ NP conjecture. Under this conjecture, a wide class of optimization problems cannot be solved exactly in polynomial time. The field of approximation algorithms, therefore, tries to understand how closely it is possible to approximate optimal solutions to such problems in polynomial time. In an overwhelming majority of the cases, the guarantee of such algorithms is a multiplicative one expressed as an approximation ratio or approximation factor i.e., the optimal solution is always guaranteed to be within a (predetermined) multiplicative factor of the returned solution. However, there are also many approximation algorithms that provide an additive guarantee on the quality of the returned solution. A notable example of an approximation algorithm that provides both is the classic approximation algorithm of Lenstra, Shmoys and Tardos for scheduling on unrelated parallel machines.
The set cover problem is a classical question in combinatorics, computer science, operations research, and complexity theory.
The art gallery problem or museum problem is a well-studied visibility problem in computational geometry. It originates from the following real-world problem:
"In an art gallery, what is the minimum number of guards who together can observe the whole gallery?"
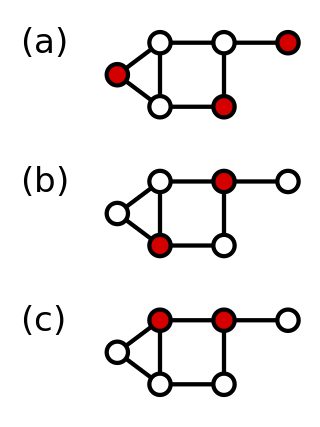
In graph theory, a dominating set for a graph G is a subset D of its vertices, such that any vertex of G is either in D, or has a neighbor in D. The domination numberγ(G) is the number of vertices in a smallest dominating set for G.

In graph theory and graph algorithms, a feedback arc set or feedback edge set in a directed graph is a subset of the edges of the graph that contains at least one edge out of every cycle in the graph. Removing these edges from the graph breaks all of the cycles, producing an acyclic subgraph of the given graph, often called a directed acyclic graph. A feedback arc set with the fewest possible edges is a minimum feedback arc set and its removal leaves a maximum acyclic subgraph; weighted versions of these optimization problems are also used. If a feedback arc set is minimal, meaning that removing any edge from it produces a subset that is not a feedback arc set, then it has an additional property: reversing all of its edges, rather than removing them, produces a directed acyclic graph.
The Christofides algorithm or Christofides–Serdyukov algorithm is an algorithm for finding approximate solutions to the travelling salesman problem, on instances where the distances form a metric space . It is an approximation algorithm that guarantees that its solutions will be within a factor of 3/2 of the optimal solution length, and is named after Nicos Christofides and Anatoliy I. Serdyukov ; the latter discovered it independently in 1976.

In theoretical computer science, smoothed analysis is a way of measuring the complexity of an algorithm. Since its introduction in 2001, smoothed analysis has been used as a basis for considerable research, for problems ranging from mathematical programming, numerical analysis, machine learning, and data mining. It can give a more realistic analysis of the practical performance of the algorithm compared to analysis that uses worst-case or average-case scenarios.
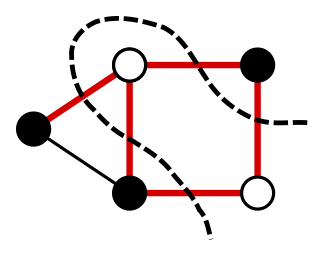
In a graph, a maximum cut is a cut whose size is at least the size of any other cut. That is, it is a partition of the graph's vertices into two complementary sets S and T, such that the number of edges between S and T is as large as possible. Finding such a cut is known as the max-cut problem.
In graph theory, the metric k-center problem is a combinatorial optimization problem studied in theoretical computer science. Given n cities with specified distances, one wants to build k warehouses in different cities and minimize the maximum distance of a city to a warehouse. In graph theory, this means finding a set of k vertices for which the largest distance of any point to its closest vertex in the k-set is minimum. The vertices must be in a metric space, providing a complete graph that satisfies the triangle inequality.

In graph drawing, a circular layout is a style of drawing that places the vertices of a graph on a circle, often evenly spaced so that they form the vertices of a regular polygon.

In computational geometry, the farthest-first traversal of a compact metric space is a sequence of points in the space, where the first point is selected arbitrarily and each successive point is as far as possible from the set of previously-selected points. The same concept can also be applied to a finite set of geometric points, by restricting the selected points to belong to the set or equivalently by considering the finite metric space generated by these points. For a finite metric space or finite set of geometric points, the resulting sequence forms a permutation of the points, also known as the greedy permutation.
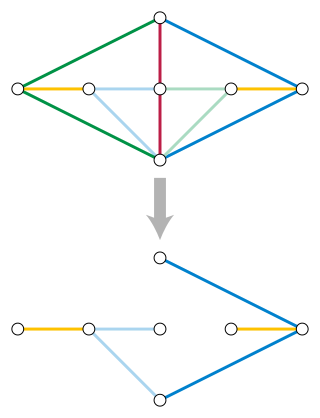
In combinatorial optimization, the matroid parity problem is a problem of finding the largest independent set of paired elements in a matroid. The problem was formulated by Lawler (1976) as a common generalization of graph matching and matroid intersection. It is also known as polymatroid matching, or the matchoid problem.
In computer science, multiway number partitioning is the problem of partitioning a multiset of numbers into a fixed number of subsets, such that the sums of the subsets are as similar as possible. It was first presented by Ronald Graham in 1969 in the context of the identical-machines scheduling problem. The problem is parametrized by a positive integer k, and called k-way number partitioning. The input to the problem is a multiset S of numbers, whose sum is k*T.
Identical-machines scheduling is an optimization problem in computer science and operations research. We are given n jobs J1, J2, ..., Jn of varying processing times, which need to be scheduled on m identical machines, such that a certain objective function is optimized, for example, the makespan is minimized.
The Recursive Largest First (RLF) algorithm is a heuristic for the NP-hard graph coloring problem. It was originally proposed by Frank Leighton in 1979.




























