
In probability theory and statistics, the binomial distribution with parameters n and p is the discrete probability distribution of the number of successes in a sequence of n independent experiments, each asking a yes–no question, and each with its own Boolean-valued outcome: success or failure. A single success/failure experiment is also called a Bernoulli trial or Bernoulli experiment, and a sequence of outcomes is called a Bernoulli process; for a single trial, i.e., n = 1, the binomial distribution is a Bernoulli distribution. The binomial distribution is the basis for the popular binomial test of statistical significance.

In mathematics, the Fibonacci sequence is a sequence in which each number is the sum of the two preceding ones. Numbers that are part of the Fibonacci sequence are known as Fibonacci numbers, commonly denoted Fn . The sequence commonly starts from 0 and 1, although some authors start the sequence from 1 and 1 or sometimes from 1 and 2. Starting from 0 and 1, the sequence begins

A hash function is any function that can be used to map data of arbitrary size to fixed-size values, though there are some hash functions that support variable length output. The values returned by a hash function are called hash values, hash codes, digests, or simply hashes. The values are usually used to index a fixed-size table called a hash table. Use of a hash function to index a hash table is called hashing or scatter storage addressing.

Ketamine is a dissociative anesthetic used medically for induction and maintenance of anesthesia. It is also used as a treatment for depression, a pain management tool, and as a recreational or date rape drug. Ketamine is a novel compound that was derived from phencyclidine in 1962 in pursuit of a safer anesthetic with fewer hallucinogenic effects.

In physics, the kinetic energy of an object is the form of energy that it possesses due to its motion.

Oscillation is the repetitive or periodic variation, typically in time, of some measure about a central value or between two or more different states. Familiar examples of oscillation include a swinging pendulum and alternating current. Oscillations can be used in physics to approximate complex interactions, such as those between atoms.

The ideal gas law, also called the general gas equation, is the equation of state of a hypothetical ideal gas. It is a good approximation of the behavior of many gases under many conditions, although it has several limitations. It was first stated by Benoît Paul Émile Clapeyron in 1834 as a combination of the empirical Boyle's law, Charles's law, Avogadro's law, and Gay-Lussac's law. The ideal gas law is often written in an empirical form:

In mathematics, particularly in linear algebra, matrix multiplication is a binary operation that produces a matrix from two matrices. For matrix multiplication, the number of columns in the first matrix must be equal to the number of rows in the second matrix. The resulting matrix, known as the matrix product, has the number of rows of the first and the number of columns of the second matrix. The product of matrices A and B is denoted as AB.

The speed of sound is the distance travelled per unit of time by a sound wave as it propagates through an elastic medium. At 20 °C (68 °F), the speed of sound in air is about 343 metres per second, or one kilometre in 2.91 s or one mile in 4.69 s. It depends strongly on temperature as well as the medium through which a sound wave is propagating. At 0 °C (32 °F), the speed of sound in air is about 331 m/s. More simply, the speed of sound is how fast vibrations travel.

The moment of inertia, otherwise known as the mass moment of inertia, angular mass, second moment of mass, or most accurately, rotational inertia, of a rigid body is a quantity that determines the torque needed for a desired angular acceleration about a rotational axis, akin to how mass determines the force needed for a desired acceleration. It depends on the body's mass distribution and the axis chosen, with larger moments requiring more torque to change the body's rate of rotation by a given amount.

In statistics, the logistic model is a statistical model that models the log-odds of an event as a linear combination of one or more independent variables. In regression analysis, logistic regression is estimating the parameters of a logistic model. Formally, in binary logistic regression there is a single binary dependent variable, coded by an indicator variable, where the two values are labeled "0" and "1", while the independent variables can each be a binary variable or a continuous variable. The corresponding probability of the value labeled "1" can vary between 0 and 1, hence the labeling; the function that converts log-odds to probability is the logistic function, hence the name. The unit of measurement for the log-odds scale is called a logit, from logistic unit, hence the alternative names. See § Background and § Definition for formal mathematics, and § Example for a worked example.
In mathematics, summation is the addition of a sequence of numbers, called addends or summands; the result is their sum or total. Beside numbers, other types of values can be summed as well: functions, vectors, matrices, polynomials and, in general, elements of any type of mathematical objects on which an operation denoted "+" is defined.

In biochemistry, Michaelis–Menten kinetics, named after Leonor Michaelis and Maud Menten, is the simplest case of enzyme kinetics, applied to enzyme-catalysed reactions of one substrate and one product. It takes the form of an equation describing the reaction rate to , the concentration of the substrate A. Its formula is given by the Michaelis–Menten equation:
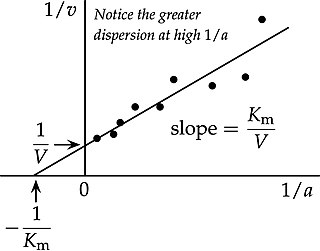
In biochemistry, the Lineweaver–Burk plot is a graphical representation of the Michaelis–Menten equation of enzyme kinetics, described by Hans Lineweaver and Dean Burk in 1934.

k-means clustering is a method of vector quantization, originally from signal processing, that aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as a prototype of the cluster. This results in a partitioning of the data space into Voronoi cells. k-means clustering minimizes within-cluster variances, but not regular Euclidean distances, which would be the more difficult Weber problem: the mean optimizes squared errors, whereas only the geometric median minimizes Euclidean distances. For instance, better Euclidean solutions can be found using k-medians and k-medoids.

Enzyme kinetics is the study of the rates of enzyme-catalysed chemical reactions. In enzyme kinetics, the reaction rate is measured and the effects of varying the conditions of the reaction are investigated. Studying an enzyme's kinetics in this way can reveal the catalytic mechanism of this enzyme, its role in metabolism, how its activity is controlled, and how a drug or a modifier might affect the rate.

In biochemistry, a Hanes–Woolf plot, Hanes plot, or plot of against is a graphical representation of enzyme kinetics in which the ratio of the initial substrate concentration to the reaction velocity is plotted against . It is based on the rearrangement of the Michaelis–Menten equation shown below:

Temperature is a physical quantity that expresses quantitatively the attribute of hotness or coldness. Temperature is measured with a thermometer. It reflects the kinetic energy of the vibrating and colliding atoms making up a substance.

In probability theory and statistics, the Poisson distribution is a discrete probability distribution that expresses the probability of a given number of events occurring in a fixed interval of time or space if these events occur with a known constant mean rate and independently of the time since the last event. It is named after French mathematician Siméon Denis Poisson. The Poisson distribution can also be used for the number of events in other specified interval types such as distance, area, or volume. It plays an important role for discrete-stable distributions.
A transformer is a deep learning architecture based on the multi-head attention mechanism. It is notable for not containing any recurrent units, and thus requires less training time than previous recurrent neural architectures, such as long short-term memory (LSTM), and its later variation has been prevalently adopted for training large language models on large (language) datasets, such as the Wikipedia corpus and Common Crawl. Input text is split into n-grams encoded as tokens and each token is converted into a vector via looking up from a word embedding table. At each layer, each token is then contextualized within the scope of the context window with other (unmasked) tokens via a parallel multi-head attention mechanism allowing the signal for key tokens to be amplified and less important tokens to be diminished. Though the transformer paper was published in 2017, the softmax-based attention mechanism was proposed in 2014 for machine translation, and the Fast Weight Controller, similar to a transformer, was proposed in 1992.