
Autocorrelation, sometimes known as serial correlation in the discrete time case, is the correlation of a signal with a delayed copy of itself as a function of delay. Informally, it is the similarity between observations of a random variable as a function of the time lag between them. The analysis of autocorrelation is a mathematical tool for finding repeating patterns, such as the presence of a periodic signal obscured by noise, or identifying the missing fundamental frequency in a signal implied by its harmonic frequencies. It is often used in signal processing for analyzing functions or series of values, such as time domain signals.

In probability theory and statistics, a normal distribution or Gaussian distribution is a type of continuous probability distribution for a real-valued random variable. The general form of its probability density function is The parameter is the mean or expectation of the distribution, while the parameter is the variance. The standard deviation of the distribution is (sigma). A random variable with a Gaussian distribution is said to be normally distributed, and is called a normal deviate.

A random variable is a mathematical formalization of a quantity or object which depends on random events. The term 'random variable' in its mathematical definition refers to neither randomness nor variability but instead is a mathematical function in which

In statistics, the standard deviation is a measure of the amount of variation of the values of a variable about its mean. A low standard deviation indicates that the values tend to be close to the mean of the set, while a high standard deviation indicates that the values are spread out over a wider range. The standard deviation is commonly used in the determination of what constitutes an outlier and what does not. Standard deviation may be abbreviated SD or Std Dev, and is most commonly represented in mathematical texts and equations by the lowercase Greek letter σ (sigma), for the population standard deviation, or the Latin letter s, for the sample standard deviation.

In probability theory and statistics, variance is the expected value of the squared deviation from the mean of a random variable. The standard deviation (SD) is obtained as the square root of the variance. Variance is a measure of dispersion, meaning it is a measure of how far a set of numbers is spread out from their average value. It is the second central moment of a distribution, and the covariance of the random variable with itself, and it is often represented by , , , , or .

In probability theory, the central limit theorem (CLT) states that, under appropriate conditions, the distribution of a normalized version of the sample mean converges to a standard normal distribution. This holds even if the original variables themselves are not normally distributed. There are several versions of the CLT, each applying in the context of different conditions.

In probability theory, a probability density function (PDF), density function, or density of an absolutely continuous random variable, is a function whose value at any given sample in the sample space can be interpreted as providing a relative likelihood that the value of the random variable would be equal to that sample. Probability density is the probability per unit length, in other words, while the absolute likelihood for a continuous random variable to take on any particular value is 0, the value of the PDF at two different samples can be used to infer, in any particular draw of the random variable, how much more likely it is that the random variable would be close to one sample compared to the other sample.

In probability theory, a log-normal (or lognormal) distribution is a continuous probability distribution of a random variable whose logarithm is normally distributed. Thus, if the random variable X is log-normally distributed, then Y = ln(X) has a normal distribution. Equivalently, if Y has a normal distribution, then the exponential function of Y, X = exp(Y), has a log-normal distribution. A random variable which is log-normally distributed takes only positive real values. It is a convenient and useful model for measurements in exact and engineering sciences, as well as medicine, economics and other topics (e.g., energies, concentrations, lengths, prices of financial instruments, and other metrics).

In mathematics, the Wiener process is a real-valued continuous-time stochastic process generalizing Brownian motion, the diffusion of microscopic particles suspended in fluid. It is named in honor of American mathematician Norbert Wiener. It is one of the best known Lévy processes. It occurs frequently in pure and applied mathematics, economics, quantitative finance, evolutionary biology, and physics.
In probability theory, the law of large numbers (LLN) is a mathematical law that states that the average of the results obtained from a large number of independent random samples converges to the true value, if it exists. More formally, the LLN states that given a sample of independent and identically distributed values, the sample mean converges to the true mean.
In mathematics, a Gaussian function, often simply referred to as a Gaussian, is a function of the base form and with parametric extension for arbitrary real constants a, b and non-zero c. It is named after the mathematician Carl Friedrich Gauss. The graph of a Gaussian is a characteristic symmetric "bell curve" shape. The parameter a is the height of the curve's peak, b is the position of the center of the peak, and c controls the width of the "bell".

In probability theory and statistics, the Rayleigh distribution is a continuous probability distribution for nonnegative-valued random variables. Up to rescaling, it coincides with the chi distribution with two degrees of freedom. The distribution is named after Lord Rayleigh.
In mathematics, the moments of a function are certain quantitative measures related to the shape of the function's graph. If the function represents mass density, then the zeroth moment is the total mass, the first moment is the center of mass, and the second moment is the moment of inertia. If the function is a probability distribution, then the first moment is the expected value, the second central moment is the variance, the third standardized moment is the skewness, and the fourth standardized moment is the kurtosis.
Stein's lemma, named in honor of Charles Stein, is a theorem of probability theory that is of interest primarily because of its applications to statistical inference — in particular, to James–Stein estimation and empirical Bayes methods — and its applications to portfolio choice theory. The theorem gives a formula for the covariance of one random variable with the value of a function of another, when the two random variables are jointly normally distributed.

In probability theory and statistics, the continuous uniform distributions or rectangular distributions are a family of symmetric probability distributions. Such a distribution describes an experiment where there is an arbitrary outcome that lies between certain bounds. The bounds are defined by the parameters, and which are the minimum and maximum values. The interval can either be closed or open. Therefore, the distribution is often abbreviated where stands for uniform distribution. The difference between the bounds defines the interval length; all intervals of the same length on the distribution's support are equally probable. It is the maximum entropy probability distribution for a random variable under no constraint other than that it is contained in the distribution's support.

In mathematics, the Ornstein–Uhlenbeck process is a stochastic process with applications in financial mathematics and the physical sciences. Its original application in physics was as a model for the velocity of a massive Brownian particle under the influence of friction. It is named after Leonard Ornstein and George Eugene Uhlenbeck.
In statistics, the delta method is a method of deriving the asymptotic distribution of a random variable. It is applicable when the random variable being considered can be defined as a differentiable function of a random variable which is asymptotically Gaussian.
Differential entropy is a concept in information theory that began as an attempt by Claude Shannon to extend the idea of (Shannon) entropy of a random variable, to continuous probability distributions. Unfortunately, Shannon did not derive this formula, and rather just assumed it was the correct continuous analogue of discrete entropy, but it is not. The actual continuous version of discrete entropy is the limiting density of discrete points (LDDP). Differential entropy is commonly encountered in the literature, but it is a limiting case of the LDDP, and one that loses its fundamental association with discrete entropy.
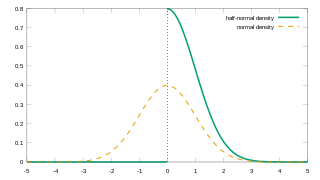
In probability theory and statistics, the half-normal distribution is a special case of the folded normal distribution.
In applied statistics, a variance-stabilizing transformation is a data transformation that is specifically chosen either to simplify considerations in graphical exploratory data analysis or to allow the application of simple regression-based or analysis of variance techniques.




