Related Research Articles

Literate programming is a programming paradigm introduced in 1984 by Donald Knuth in which a computer program is given as an explanation of how it works in a natural language, such as English, interspersed (embedded) with snippets of macros and traditional source code, from which compilable source code can be generated. The approach is used in scientific computing and in data science routinely for reproducible research and open access purposes. Literate programming tools are used by millions of programmers today.

A markuplanguage is a text-encoding system consisting of a set of symbols inserted in a text document to control its structure, formatting, or the relationship between its parts. Markup is often used to control the display of the document or to enrich its content to facilitate automated processing.
Extensible Markup Language (XML) is a markup language and file format for storing, transmitting, and reconstructing arbitrary data. It defines a set of rules for encoding documents in a format that is both human-readable and machine-readable. The World Wide Web Consortium's XML 1.0 Specification of 1998 and several other related specifications—all of them free open standards—define XML.
XSLT is a language originally designed for transforming XML documents into other XML documents, or other formats such as HTML for web pages, plain text or XSL Formatting Objects, which may subsequently be converted to other formats, such as PDF, PostScript and PNG. Support for JSON and plain-text transformation was added in later updates to the XSLT 1.0 specification.
DocBook is a semantic markup language for technical documentation. It was originally intended for writing technical documents related to computer hardware and software, but it can be used for any other sort of documentation.
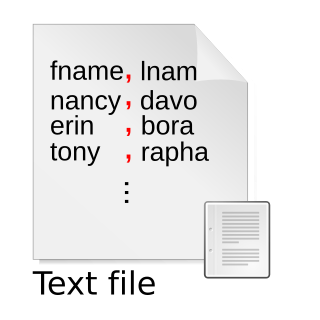
A delimiter is a sequence of one or more characters for specifying the boundary between separate, independent regions in plain text, mathematical expressions or other data streams. An example of a delimiter is the comma character, which acts as a field delimiter in a sequence of comma-separated values. Another example of a delimiter is the time gap used to separate letters and words in the transmission of Morse code.
The Text Encoding Initiative (TEI) is a text-centric community of practice in the academic field of digital humanities, operating continuously since the 1980s. The community currently runs a mailing list, meetings and conference series, and maintains the TEI technical standard, a journal, a wiki, a GitHub repository and a toolchain.
An XML editor is a markup language editor with added functionality to facilitate the editing of XML. This can be done using a plain text editor, with all the code visible, but XML editors have added facilities like tag completion and menus and buttons for tasks that are common in XML editing, based on data supplied with document type definition (DTD) or the XML tree.
In computing, formatted text, styled text, or rich text, as opposed to plain text, is digital text which has styling information beyond the minimum of semantic elements: colours, styles, sizes, and special features in HTML.
A concordancer is a computer program that automatically constructs a concordance. The output of a concordancer may serve as input to a translation memory system for computer-assisted translation, or as an early step in machine translation.
Cocoa may refer to:
The Theological Markup Language (ThML) is a "royalty-free" XML-based format created in 1998 by the Christian Classics Ethereal Library (CCEL) to create electronic theological texts. Other formats such as STEP and Logos Library System (LLS) were found unacceptable by CCEL as they are proprietary, prompting the creation of the new language. The ThML format borrowed elements from a somewhat similar format, the Text Encoding Initiative (TEI).

C. Michael Sperberg-McQueen is an American markup language specialist. He was co-editor of the Extensible Markup Language (XML) 1.0 spec (1998), and chair of the XML Schema working group.
The less-than sign is a mathematical symbol that denotes an inequality between two values. The widely adopted form of two equal-length strokes connecting in an acute angle at the left, <, has been found in documents dated as far back as the 1560s. In mathematical writing, the less-than sign is typically placed between two values being compared and signifies that the first number is less than the second number. Examples of typical usage include 1⁄2 < 1 and −2 < 0.
Steven J DeRose is a computer scientist noted for his contributions to Computational Linguistics and to key standards related to document processing, mostly around ISO's Standard Generalized Markup Language (SGML) and W3C's Extensible Markup Language (XML).
Susan Hockey is an Emeritus Professor of Library and Information Studies at University College London. She has written about the history of digital humanities, the development of text analysis applications, electronic textual mark-up, teaching computing in the humanities, and the role of libraries in managing digital resources. In 2014, University College London created a Digital Humanities lecture series in her honour.

Sebastian Patrick Quintus Rahtz (SPQR) was a British digital humanities information professional.
The Oxford Concordance Program (OCP) was first released in 1981 and was a result of a project started in 1978 by Oxford University Computing Services (OUCS) to create a machine independent text analysis program for producing word lists, indexes and concordances in a variety of languages and alphabets.
Lou Burnard is an internationally recognised expert in digital humanities, particularly in the area of text encoding and digital libraries. He was assistant director of Oxford University Computing Services (OUCS) from 2001 to September 2010, when he officially retired from OUCS. Before that, he was manager of the Humanities Computing Unit at OUCS for five years. He has worked in ICT support for research in the humanities since the 1990s. He was one of the founding editors of the Text Encoding Initiative (TEI) and continues to play an active part in its maintenance and development, as a consultant to the TEI Technical Council and as an elected TEI board member. He has played a key role in the establishment of many other activities and initiatives in this area, such as the UK Arts and Humanities Data Service and the British National Corpus, and has published and lectured widely. Since 2008 he has worked as a Member of the Conseil Scientifique for the CNRS-funded "Adonis" TGE.
References
- ↑ Paul E. Corcoran (November 1974). "COCOA: A FORTRAN Program for Concordance and Word-count Processing of Natural Language Texts". Behavior Research Methods & Instrumentation. 6 (6): 566. doi: 10.3758/BF03201351 .
- ↑ Colin Day and Ian Marriott (February 1976). "Software Reviews: COCOA: A Word Count and Concordance Generator". Computers and the Humanities. 10 (1): 56. doi:10.1007/BF02399143. S2CID 198177017.
- ↑ D. B. Russell (1965). "COCOA - A Word Count and Concordance Generator". Associates Technology Literature Applications Society. Retrieved 20 October 2013.
- ↑ Susan Hockey. "The History of Humanities Computing". University of Illinois. Archived from the original on 18 September 2013. Retrieved 20 October 2013.
- ↑ Gratian, 12th Cent (14 January 1987). "Concordia discordantium canonum ac primum de iure naturae et constitutionis". University of Oxford Text Archive. Retrieved 20 October 2013.
- ↑ James Cummings, Sebastian Rahtz (2010). "This script is used to convert COCOA to TEI" (XSLT). Oxford University. Retrieved 3 April 2018.
- ↑ "Stylesheets/Cocoa at dev · TEIC/Stylesheets". GitHub .
- ↑ "Corpus Resource Database (CoRD)".